R语言进行神经网络算法——RSNNS
1. 官方资料
很重要,写得也很清楚,其实下文就是文档的学习笔记
https://cran.r-project.org/web/packages/RSNNS/RSNNS.pdf
2. 安装及加载
install.packages(rsnns)
install.packages(rcpp)
library(Rcpp)
library(RSNNS)
3. Demo(iris)解读及学习
文档里表示,一些高度集成的接口(high-level api)已经很强大了,用这些接口可以基本实现大部分的应用啦。我们提供了: mlp, dlvq, rbf, rbfDDA, elman, jordan, som, art1, art2, artmap, or
assoz这么多网络形式供你们选择使用呢。
学习rsnns的快速方法可以通过查看原生的demo开始,通过调用函数demo()可以查看包里的函数。demo(iris)是以iris数据做的一个示例,来对这个示例进行一下解读。
set.seed(2)
data(iris)
#shuffle the vector 打乱原始数据,并拆分成评价集和结果集
df <- iris[sample(nrow(iris)),]
dfValues <- df[,1:4]
dfTargets <- decodeClassLabels(df[,5])
#dfTargets <- decodeClassLabels(df[,5], valTrue=0.9, valFalse=0.1)decodeClassLabels这个函数会将结果集变成一个二元矩阵,就是 c(a, b, c, b) 这样一个输入,会变成这样一个矩阵
| row.num | a | b | c |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | 0 | 1 | 0 |
df <- splitForTrainingAndTest(dfValues, dfTargets, ratio=0.15)splitForTrainingAndTest将按比例拆成训练集和测试集,返回list,含四个元素分别就是训练的评价集(inputsTrain)、训练的结果集(targetTrain)、测试的评价集(inputsTest)和测试的结果集(targetTest)
#normalize data
df <- normTrainingAndTestSet(df)normTrainingAndTestSet,标准化数据,把数据化到[0,1]之间
model <- mlp(df$inputsTrain, df$targetsTrain, size=5, learnFunc="Quickprop", learnFuncParams=c(0.1, 2.0, 0.0001, 0.1),maxit=50, inputsTest=df$inputsTest, targetsTest=df$targetsTest)
#model <- mlp(df$inputsTrain, df$targetsTrain, size=5, learnFunc="BackpropBatch", learnFuncParams=c(10, 0.1), maxit=100, inputsTest=df$inputsTest, targetsTest=df$targetsTest)
#model <- mlp(df$inputsTrain, df$targetsTrain, size=5, learnFunc="SCG", learnFuncParams=c(0, 0, 0, 0), maxit=30, inputsTest=df$inputsTest, targetsTest=df$targetsTest)mlp 创建和训练多层感知器,用的几个参数分别是,两个训练数据集、训练方法及其参数(前向传播、后向传播等)、学习的迭代次数、和两个测试数据集
#以下是通过其他网络形式来训练模型的示例
#model <- rbfDDA(df$inputsTrain, df$targetsTrain)
#model <- elman(df$inputsTrain, df$targetsTrain, size=5, learnFuncParams=c(0.1), maxit=100, inputsTest=df$inputsTest, targetsTest=df$targetsTest)
#model <- rbf(df$inputsTrain, df$targetsTrain, size=40, maxit=200, initFuncParams=c(-4, 4, 0.0, 0.2, 0.04), learnFuncParams=c(1e-3, 0, 1e-3, 0.1, 0.8), linOut=FALSE)
#model <- rbf(df$inputsTrain, df$targetsTrain, size=40, maxit=600, initFuncParams=c(0, 1, 0.0, 0.2, 0.04), learnFuncParams=c(1e-5, 0, 1e-5, 0.1, 0.8), linOut=TRUE)#我们来看看现在model长啥样了。
summary(model)以下是summary出来的结果:
network name : RSNNS_untitled
source files :
no. of units : 12
no. of connections : 35
no. of unit types : 0
no. of site types : 0
learning function : Quickprop
update function : Topological_Order
unit default section :
| act | bias | st | subnet | layer | act func | out func |
|---|---|---|---|---|---|---|
| 0.00000 | 0.00000 | i | 0 | 1 | Act_Logistic | Out_Identity |
unit definition section :
| no. | typeName | unitName | act | bias | st | position | act func | out func | sites |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Input_1 | 0.81788 | -0.19070 | i | 1,0,0 | Act_Identity | |||
| 2 | Input_2 | -0.09058 | -0.08354 | i | 2,0,0 | Act_Identity | |||
| 3 | Input_3 | 0.82358 | 0.24228 | i | 3,0,0 | Act_Identity | |||
| 4 | Input_4 | 1.07735 | -0.06357 | i | 4,0,0 | Act_Identity | |||
| 5 | Hidden_2_1 | 0.99948 | 1.21595 | h | 1,2,0 | ||||
| 6 | Hidden_2_2 | 0.82239 | -8.10572 | h | 2,2,0 | ||||
| 7 | Hidden_2_3 | 0.00000 | -2.36254 | h | 3,2,0 | ||||
| 8 | Hidden_2_4 | 0.08915 | 2.00512 | h | 4,2,0 | ||||
| 9 | Hidden_2_5 | 0.94264 | -9.13474 | h | 5,2,0 | ||||
| 10 | Output_setosa | 0.06700 | -0.27557 | o | 1,4,0 | ||||
| 11 | Output_versicolor | 0.00570 | 0.99939 | o | 2,4,0 | ||||
| 12 | Output_virginica | 0.99497 | -1.77136 | o | 3,4,0 |
connection definition section :
| target | site | source:weight |
|---|---|---|
| 5 | 4: 2.56254, 3: 3.62335, 2:-1.45458, 1: 0.58201 | |
| 6 | 4: 4.29742, 3: 6.51703, 2:-1.39911, 1:-0.59361 | |
| 7 | 4:-20.43423, 3:-16.46137, 2:14.56812, 1:-9.81231 | |
| 8 | 4:-3.17215, 3:-2.22153, 2:-12.17735, 1:-0.22635 | |
| 9 | 4: 8.62831, 3: 4.17759, 2:-1.51025, 1:-1.14802 | |
| 10 | 9: 0.00000, 8:-0.97029, 7: 3.45525, 6: 0.00000, 5:-2.27275 | |
| 11 | 9:-4.38496, 8: 1.10374, 7:-4.26942, 6:-4.40117, 5: 1.49396 | |
| 12 | 9: 4.44252, 8:-1.34431, 7:-0.69826, 6: 4.36206, 5:-0.59650 |
try my best地来解释一下,其实结果就是创建了长这样的一个模型:
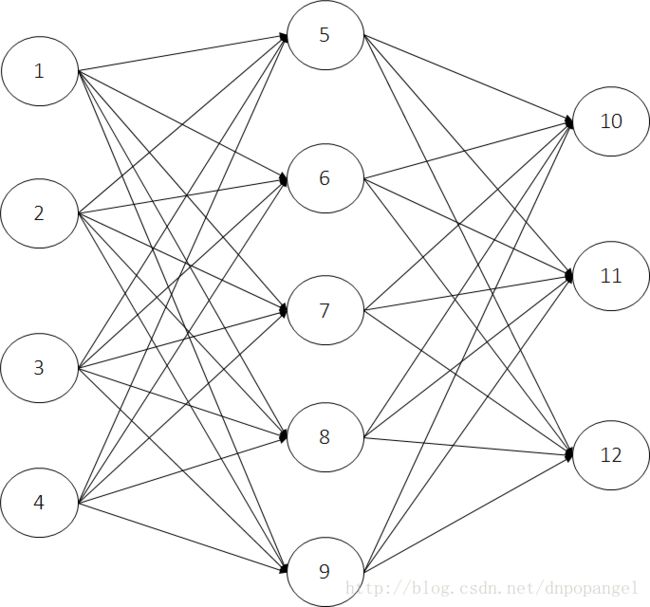
四个输入节点(四维的评价集),自己创建的五个隐藏节点,以及输出的三个节点(三维的结果集)
所以总共是12个节点(no. of units: 12),4*5+3*5=35条连线(no. of connections: 35)。
下面一张表是描述每个节点的基本信息,节点类型、节点位置、节点名字、节点偏差值等。
再下面一张表是在描述线的信息,每条线的权重是多少。例如指向节点5的四条线,权重分别是4: 2.56254, 3: 3.62335, 2:-1.45458, 1: 0.58201
#利用上面的模型进行预测
predictions = predict(model,df$inputsTest)
#生成混淆矩阵,观察预测精度
confusionMatrix(df$targetsTest,predictions)predictions
targets 1 2 3
1 9 0 0
2 0 3 1
3 0 1 9