Spark源码解析之任务提交(spark-submit)篇
今天主要分析一下Spark源码中提交任务脚本的处理逻辑,从spark-submit一步步深入进去看看任务提交的整体流程,首先看一下整体的流程概要图:
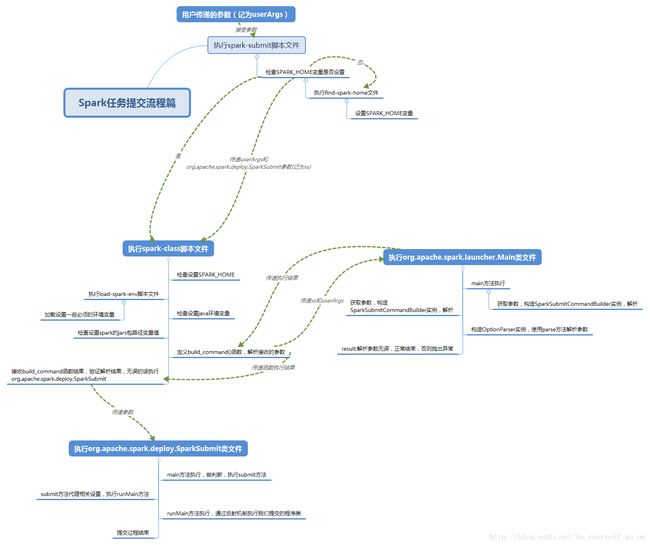
接下来按照图中结构出发一步步看源码:
spark-submit
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# -z是检查后面变量是否为空(空则真) shell可以在双引号之内引用变量,单引号不可
#这一步作用是检查SPARK_HOME变量是否为空,为空则执行then后面程序
#source命令: source filename作用在当前bash环境下读取并执行filename中的命令
#$0代表shell脚本文件本身的文件名,这里即使spark-submit
#dirname用于取得脚本文件所在目录 dirname $0取得当前脚本文件所在目录
#$(命令)表示返回该命令的结果
#故整个if语句的含义是:如果SPARK_HOME变量没有设置值,则执行当前目录下的find-spark-home脚本文件,设置SPARK_HOME值
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
#执行spark-class脚本,传递参数org.apache.spark.deploy.SparkSubmit 和"$@"
#这里$@表示之前spark-submit接收到的全部参数
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"所以spark-submit脚本的整体逻辑就是:
首先 检查SPARK_HOME是否设置;if 已经设置 执行spark-class文件 否则加载执行find-spark-home文件
先看一下find-spark-home文件:
#!/usr/bin/env bash
# Attempts to find a proper value for SPARK_HOME. Should be included using "source" directive.
#定义一个变量用于后续判断是否存在定义SPARK_HOME的python脚本文件
FIND_SPARK_HOME_PYTHON_SCRIPT="$(cd "$(dirname "$0")"; pwd)/find_spark_home.py"
# Short cirtuit if the user already has this set.
##如果SPARK_HOME为不为空值,成功退出程序
if [ ! -z "${SPARK_HOME}" ]; then
exit 0
# -f用于判断这个文件是否存在并且是否为常规文件,是的话为真,这里不存在为假,执行下面语句,给SPARK_HOME变量赋值
elif [ ! -f "$FIND_SPARK_HOME_PYTHON_SCRIPT" ]; then
# If we are not in the same directory as find_spark_home.py we are not pip installed so we don't
# need to search the different Python directories for a Spark installation.
# Note only that, if the user has pip installed PySpark but is directly calling pyspark-shell or
# spark-submit in another directory we want to use that version of PySpark rather than the
# pip installed version of PySpark.
export SPARK_HOME="$(cd "$(dirname "$0")"/..; pwd)"
else
# We are pip installed, use the Python script to resolve a reasonable SPARK_HOME
# Default to standard python interpreter unless told otherwise
if [[ -z "$PYSPARK_DRIVER_PYTHON" ]]; then
PYSPARK_DRIVER_PYTHON="${PYSPARK_PYTHON:-"python"}"
fi
export SPARK_HOME=$($PYSPARK_DRIVER_PYTHON "$FIND_SPARK_HOME_PYTHON_SCRIPT")
fi
可以看到,如果事先用户没有设定SPARK_HOME的值,这里程序也会自动设置并且将其注册为环境变量,供后面程序使用
当SPARK_HOME的值设定完成之后,就会执行Spark-class文件,这也是我们分析的重要部分,源码如下:
spark-class
#!/usr/bin/env bash
#依旧是检查设置SPARK_HOME的值
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
#执行load-spark-env.sh脚本文件,主要目的在于加载设定一些变量值
#设定spark-env.sh中的变量值到环境变量中,供后续使用
#设定scala版本变量值
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Find the java binary
#检查设定java环境值
#-n代表检测变量长度是否为0,不为0时候为真
#如果已经安装Java没有设置JAVA_HOME,command -v java返回的值为${JAVA_HOME}/bin/java
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
#-d检测文件是否为目录,若为目录则为真
#设置一些关联Class文件
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
#执行类文件org.apache.spark.launcher.Main,返回解析后的参数
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# Turn off posix mode since it does not allow process substitution
#将build_command方法解析后的参数赋给CMD
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
# Certain JVM failures result in errors being printed to stdout (instead of stderr), which causes
# the code that parses the output of the launcher to get confused. In those cases, check if the
# exit code is an integer, and if it's not, handle it as a special error case.
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
CMD=("${CMD[@]:0:$LAST}")
执行CMD中的某个参数类org.apache.spark.deploy.SparkSubmit
exec "${CMD[@]}"
spark-class文件的执行逻辑稍显复杂,总体上应该是这样的:检查SPARK_HOME的值-》执行load-spark-env.sh文件,设定一些需要用到的环境变量,如scala环境值,这其中也加载了spark-env.sh文件-》检查设定java的执行路径变量值-》寻找spark jars,设定一些引用相关类的位置变量-》执行类文件org.apache.spark.launcher.Main,返回解析后的参数给CMD-》判断解析参数是否正确(代表了用户设置的参数是否正确)-》正确的话执行org.apache.spark.deploy.SparkSubmit这个类
整体上是这个路线,这其中在执行org.apache.spark.launcher.Main类解析参数时候还涉及到了一些其他的类引用,主要功能也是辅助解析参数是否正确,下面看一下这几个类:
org.apache.spark.launcher.Main
public static void main(String[] argsArray) throws Exception {
checkArgument(argsArray.length > 0, "Not enough arguments: missing class name.");
List<String> args = new ArrayList<>(Arrays.asList(argsArray));
String className = args.remove(0);
boolean printLaunchCommand = !isEmpty(System.getenv("SPARK_PRINT_LAUNCH_COMMAND"));
AbstractCommandBuilder builder;
//这一步做判断,我们在之前传入了org.apache.spark.deploy.SparkSubmit这个参数,所以是正确的
if (className.equals("org.apache.spark.deploy.SparkSubmit")) {
try {
//执行这句话,主要的参数解析核心方法也是这句话,接着看一下SparkSubmitCommandBuilder类,见下面
builder = new SparkSubmitCommandBuilder(args);
} catch (IllegalArgumentException e) {
printLaunchCommand = false;
System.err.println("Error: " + e.getMessage());
System.err.println();
MainClassOptionParser parser = new MainClassOptionParser();
try {
parser.parse(args);
} catch (Exception ignored) {
// Ignore parsing exceptions.
}
List<String> help = new ArrayList<>();
if (parser.className != null) {
help.add(parser.CLASS);
help.add(parser.className);
}
help.add(parser.USAGE_ERROR);
builder = new SparkSubmitCommandBuilder(help);
}
} else {
builder = new SparkClassCommandBuilder(className, args);
}
Map<String, String> env = new HashMap<>();
List<String> cmd = builder.buildCommand(env);
if (printLaunchCommand) {
System.err.println("Spark Command: " + join(" ", cmd));
System.err.println("========================================");
}
//系统类型判断
if (isWindows()) {
System.out.println(prepareWindowsCommand(cmd, env));
} else {
// In bash, use NULL as the arg separator since it cannot be used in an argument.
List<String> bashCmd = prepareBashCommand(cmd, env);
for (String c : bashCmd) {
System.out.print(c);
System.out.print('\0');
}
}
}
SparkSubmitCommandBuilder
SparkSubmitCommandBuilder(List<String> args) {
this.allowsMixedArguments = false;
this.sparkArgs = new ArrayList<>();
boolean isExample = false;
List<String> submitArgs = args;
if (args.size() > 0) {
//解析参数,选择类型,这里我们是SPARK_SHELL
switch (args.get(0)) {
case PYSPARK_SHELL:
this.allowsMixedArguments = true;
appResource = PYSPARK_SHELL;
submitArgs = args.subList(1, args.size());
break;
//执行这一步 ,进行参数截取,去掉第一个类型选择参数
case SPARKR_SHELL:
this.allowsMixedArguments = true;
appResource = SPARKR_SHELL;
submitArgs = args.subList(1, args.size());
break;
case RUN_EXAMPLE:
isExample = true;
submitArgs = args.subList(1, args.size());
}
this.isExample = isExample;
//创建解析器,解析参数,看一下**parse方法**,见下面
OptionParser parser = new OptionParser();
parser.parse(submitArgs);
this.isAppResourceReq = parser.isAppResourceReq;
} else {
this.isExample = isExample;
this.isAppResourceReq = false;
}
}parse方法
//整个过程就是参数解析验证的过程,这里有一个很重要的二维数组用于验证,即opts
//opts具体包含元素见下面
protected final void parse(List args) {
Pattern eqSeparatedOpt = Pattern.compile("(--[^=]+)=(.+)");
int idx = 0;
for (idx = 0; idx < args.size(); idx++) {
String arg = args.get(idx);
String value = null;
Matcher m = eqSeparatedOpt.matcher(arg);
if (m.matches()) {
arg = m.group(1);
value = m.group(2);
}
// Look for options with a value.
String name = findCliOption(arg, opts);
if (name != null) {
if (value == null) {
if (idx == args.size() - 1) {
throw new IllegalArgumentException(
String.format("Missing argument for option '%s'.", arg));
}
idx++;
value = args.get(idx);
}
if (!handle(name, value)) {
break;
}
continue;
}
// Look for a switch.
name = findCliOption(arg, switches);
if (name != null) {
if (!handle(name, null)) {
break;
}
continue;
}
if (!handleUnknown(arg)) {
break;
}
}
if (idx < args.size()) {
idx++;
}
handleExtraArgs(args.subList(idx, args.size()));
} opts数组内容:包含了我们设置了参数名称
final String[][] opts = {
{ ARCHIVES },
{ CLASS },
{ CONF, "-c" },
{ DEPLOY_MODE },
{ DRIVER_CLASS_PATH },
{ DRIVER_CORES },
{ DRIVER_JAVA_OPTIONS },
{ DRIVER_LIBRARY_PATH },
{ DRIVER_MEMORY },
{ EXECUTOR_CORES },
{ EXECUTOR_MEMORY },
{ FILES },
{ JARS },
{ KEYTAB },
{ KILL_SUBMISSION },
{ MASTER },
{ NAME },
{ NUM_EXECUTORS },
{ PACKAGES },
{ PACKAGES_EXCLUDE },
{ PRINCIPAL },
{ PROPERTIES_FILE },
{ PROXY_USER },
{ PY_FILES },
{ QUEUE },
{ REPOSITORIES },
{ STATUS },
{ TOTAL_EXECUTOR_CORES },
};执行完成整个org.apache.spark.launcher.Main在spark-class文件程序会获取一个执行成功与否的结果标志码,成功的情况下会接着执行org.apache.spark.deploy.SparkSubmit这个类,下面看一下它的源码。
org.apache.spark.deploy.SparkSubmit
首先进入main方法
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
执行这一句,转到submit方法
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}submit方法查看:
private def submit(args: SparkSubmitArguments): Unit = {
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
// scalastyle:off println
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
// scalastyle:on println
exitFn(1)
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
可以看到submit方法里面最终执行的是runMain方法,这也是最核心的方法,看一下:
runMain方法查看:
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit = {
// scalastyle:off println
if (verbose) {
printStream.println(s"Main class:\n$childMainClass")
printStream.println(s"Arguments:\n${childArgs.mkString("\n")}")
printStream.println(s"System properties:\n${sysProps.mkString("\n")}")
printStream.println(s"Classpath elements:\n${childClasspath.mkString("\n")}")
printStream.println("\n")
}
// scalastyle:on println
val loader =
if (sysProps.getOrElse("spark.driver.userClassPathFirst", "false").toBoolean) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
for ((key, value) <- sysProps) {
System.setProperty(key, value)
}
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
e.printStackTrace(printStream)
if (childMainClass.contains("thriftserver")) {
// scalastyle:off println
printStream.println(s"Failed to load main class $childMainClass.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
e.printStackTrace(printStream)
if (e.getMessage.contains("org/apache/hadoop/hive")) {
// scalastyle:off println
printStream.println(s"Failed to load hive class.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
}
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
@tailrec
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
try {
mainMethod.invoke(null, childArgs.toArray)
} catch {
case t: Throwable =>
findCause(t) match {
case SparkUserAppException(exitCode) =>
System.exit(exitCode)
case t: Throwable =>
throw t
}
}
}runMain方法中是通过反射机制 mainMethod.invoke(null, childArgs.toArray)执行最后我们提交的类,到这里整个提交执行过程就结束了。