1.前言
本文基于Linux 2.6.32分析其进程模型,包括进程的概念、组织、转换、调度等内容,帮助对操作系统课程及Linux相关知识的理解和学习。
附Linux Kernel 2.6.32源码下载地址:
https://mirrors.edge.kernel.org/pub/linux/kernel/v2.6/linux-2.6.32.tar.gz
2.进程的概念
2.1什么是进程?
在正式开始结合源代码分析进程模型之前,我们首先需要搞清楚进程的究竟是什么。
维基百科上对于进程的定义如下:
进程(英语:process),是计算机中已运行程序的实体。
我们知道,我们的系统仅认识二进制文件,那么当我们要让系统运行某个功能的时候,也就是需要启动一个二进制文件,这个文件就是程序。
而Linux系统中,每个进程拥有三组人的权限(分别为u/g/o,即拥有者/拥有者所属组其他成员/不是拥有者也不是所属组的成员),每组人可能拥有的权限为r/w/x(读/写/执行),所以,不同的用户身份执行同一个程序时,系统给予的权限可能不同,即产生的进程也可能不同。
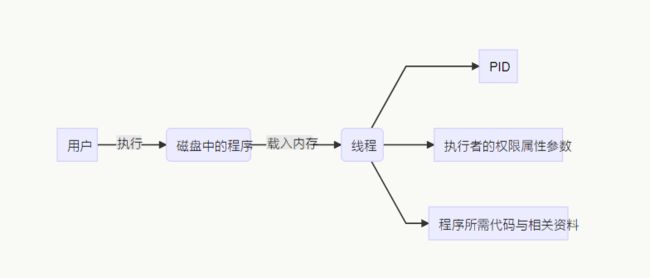
如上图所示,程序一般存储在磁盘中,通过用户的执行来触发,触发后,程序加载到内存中,成为一个个体,那就是进程。操作系统为了管理这个进程,会给予进程执行者的权限/属性等参数,以及进程所需要的数据,最后再给予一个PID,通过PID来识别该进程。
2.2进程与程序、线程的区别
在面向进程设计的系统(如早期的UNIX,Linux 2.4及更早的版本)中,进程是程序的基本执行实体;在面向线程设计的系统(如当代多数操作系统、Linux 2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器。
简单地来说,进程与程序是动态与静止的区别,进程与程序是多对一的,同样,线程与进程也是多对一的。
3.进程的组织
3.1进程描述符
进程描述符是用于描述一个进程的结构体,每个进程只有一个这样的结构体,包含了关于这个进程的所有信息。这个结构体名为task_struct,被定义在源代码包目录下的include/linux/sched.h头文件中,这里截取部分代码进行分析说明。(ps:由于我是在虚拟机下运行linux,为方便代码的拷贝,使用了secureCRT的sftp服务器将虚拟机中的相关代码文件传输到了客户端上,用虚拟机运行linux的朋友可以参考此用法)
struct task_struct{
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
......
int prio, static_prio, normal_prio;
unsigned int rt_priority;
......
pid_t pid;
......
}3.2进程标识符(PID)
文章的第二部分已经提到过,系统通过PID来唯一的标识每个进程。可用如下命令查看系统当前的进程信息:
ps -l
运行结果如图,我们可以看到当前系统中的三个进程,分别为bash,top,ps。其中bash即我们的终端,每运行一个终端,都会生成一个bash进程,可以看到这个bash进程的PID为7275。而ps是在终端下运行的查看进程的指令,它的PID为7287。除了PID外,还有一个PPID,指的是父进程的PID,即执行了这条命令的bash的PID-7275。何为父进程呢?这样说吧, 当我们打开终端时,会获得一个bash进程,然后,我们用这个bash提供的接口去执行另外的命令,例如刚刚所说的ps,这些命令也会被分配PID,这就是“子进程”,而原本的bash环境,自然就是“父进程”了。
3.3进程优先级(PRI)
进程的优先级是指系统在进程调度时用于判决进程是否能够获取CPU资源的依据。进程的优先级越高,则越能在竞争中胜出而获得CPU资源。在Linux中,进程的优先级用一个整数表达,数值越低,优先级越高。在上一小节的截图中,我们能看到每个进程都有一个优先级,默认情况下为80。
在task_struct中,用了几个成员变量来表示优先级。
int prio,static_prio, normal_prio;
unsigned int rt_priority;| 字段 | 描述 |
|---|---|
| prio | 动态优先级 |
| static_prio | 静态优先级,是进程启动时分配的优先级 |
| normal_prio | 普通优先级,即基于进程的静态优先级和调度策略计算出的优先级 |
| rt_priority | 实时优先级 |
为什么会出现这么多优先级呢?这是因为在某些情况下,系统需要暂时改变进程的优先级,但这些改变不是持久的,因此这个优先级会用prio表示(调度器会考虑的优先级也保存在prio),而不改变静态优先级和普通优先级。需要注意的是,当我们用renice命令改变进程的优先级时,改变的是静态优先级。
3.4进程的状态
进程的状态在task_struct中以如下方式定义
struct task_struct{
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */在sched.h头文件中,有着state变量可能拥有的值:
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256通过注释我们可以知道,进程状态分为两类,其中state是关于运行的状态,exit_state是关于退出的状态。代码中定义的各字段所代表的意义如下:
| 字段 | 描述 |
|---|---|
| TASK_RUNNING | 可运行状态,进程要么正在执行,要么准备执行。 |
| TASK_INTERRUPTIBLE | 可中断的等待状态,进程处于睡眠状态,直到某个条件为真而被唤醒。 |
| TASK_UNINTERRUPTIBLE | 不可中断的等待状态,与可中断的等待状态类似,但是不能被信号所唤醒 |
| TASK_STOPED | 暂停状态,当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU信号后进入。 |
| TASK_TRACED | 跟踪状态,进程被另一个进程所监控,如debugger |
| EXIT_ZOMBIE | 僵尸状态,进程已经终止,但父进程还没有获得进程的终止信息 |
| EXIT_DEAD | 进程被终止的最终状态 |
综合以上两部分,我们大致清楚了,系统通过进程标识符(PID)来唯一地标识进程,通过优先级(PRI)来决定哪些进程现在应该被运行,通过进程的状态来有序安排进程在什么时候应该做什么事情,这便是进程的组织了。
4.进程的转换

上图清楚的展示了进程间的转换过程,这里简单说明一下。当我们创建一个任务并运行时,它就是TASK_RUNNING状态,CPU不停地分配时间片给这个进程,当时间片耗尽,进程转为就绪态(仍然为TASK_RUNNING),等待CPU再次分配时间片。如果进程需要进行像写入磁盘文件这样的操作时,进程就会进入TASK_INTERRUPTIBLE状态,等待操作完毕,操作完毕后,进程收到中断告知,则重新回到运行状态。
当硬件条件不满足,比如进程打开一个设备文件,驱动开始探测相应的硬件时,会进入TASK_UNINTERRUPTIBLE状态,此时只能通过特定的方式唤醒。进程需要退出时,会进入僵尸状态,保留其进程描述符供父进程获取信息,当父进程通过wait()系统调用告诉系统后,进程进入EXIT_DEAD状态,运行周期结束。
5.进程的调度
5.1关于调度
无论是在linux下输入ps命令,还是在windows下打开任务管理器,我们通常都能看到一大堆的进程,这给了我们一种错觉:系统同时在执行很多个进程。事实上,我们看到的进程中,绝大部分处在休眠状态,CPU在同一时间只会执行一个进程,这就是调度器面对的情况。调度器需要在进程之间共享CPU时间,创造并行执行的错觉。它不仅要尽可能公平地共享CPU,同时又要考虑不同的任务优先级,以提供良好的用户体验。整个调度系统至少包含两种调度算法,分别针对实时进程和普通进程。最开始的调度器是复杂度为O(n)的始调度算法,每次都会遍历所有任务,效率低下。后来引入了O(1)调度器,大大提高了效率。当然,在全球程序员的智慧下,自linux2.6开始,一个更优秀的调度器取代了O(1)调度器,即CFS调度器。它有着完全公平的思想,将所有的进程统一对待,本文的这一部分主要介绍的就是调度普通进程的CFS调度器。
5.2优先级和nice值
在分析CFS之前,我想先补充一下前面提到过的优先级和nice值。为什么需要优先级呢?我们知道,CPU一秒钟可以运行G级别的微命令次数,通过内核的CPU调度,各进程被CPU切换运行,因此,每个进程在一秒之内可能会被CPU或多或少地执行部分。如果没有优先级的存在,每个进程像游乐场排队一样,玩过一遍还想玩,得去后面继续排队等待,如果前面的任务又臭又长,紧急的任务得不到及时的反馈,用户体验自然会很差了。这就是我们为什么需要优先级来提高紧急任务的执行频率。要注意的是,PRI是由系统内核动态调整的,用户无法直接调整PRI,要想调整进程的优先执行顺序时,我们得通过Nice值(谦让值)。一般来说,PRI与NICE的相关性如下:
PRI(NEW)=PRI(OLD)+nice
Nice是一个从-20~19的值,默认等于0。需要注意,Nice的值为负数时,优先级的数值下降,即代表优先级升高,Nice值越小,代表越不”谦让“,优先级就越高。
5.3CFS算法
task_struct中有一个struct_entity se成员,定义了调度器的实体结构。进程调度算法实际上也就是管理所以进程的这个se成员。
struct_entity 部分代码如下
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;5.3.1关于vruntime
vruntime是CFS的重要概念,简单地说,vruntime是该进程的运行时间,但这个时间是通过优先级等计算过的虚拟运行时间,并非物理时间。之前在进程的转换中提到过CPU分配时间片,在CFS中,已经不再使用时间片,而是按照虚拟运行时间来衡量进程此时是否该被调度。那么,虚拟时间是如何被计算出来的呢?kernel/sched.c中有一个用于处理时钟中断的函数,如下
void scheduler_tick(void)
{
…
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
update_cpu_load(rq);
curr->sched_class->task_tick(rq, curr, 0);
raw_spin_unlock(&rq->lock);
…
}其中,curr->sched_class->task_tick(rq, curr, 0);用于执行调度器,更新vruntime值。task_tike_fair函数则会在循环语句中,对所以有se变量调用entity_tick(),代码如下
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);//Look at this line
}static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq); //Look at this line
#ifdef CONFIG_SCHED_HRTICK
/*
* queued ticks are scheduled to match the slice, so don't bother
* validating it and just reschedule.
*/
if (queued) {
resched_task(rq_of(cfs_rq)->curr);
return;
}
/*
* don't let the period tick interfere with the hrtick preemption
*/
if (!sched_feat(DOUBLE_TICK) &&
hrtimer_active(&rq_of(cfs_rq)->hrtick_timer))
return;
#endif
if (cfs_rq->nr_running > 1 || !sched_feat(WAKEUP_PREEMPT))
check_preempt_tick(cfs_rq, curr);
}重点是update_curr(cfs_rq);更新了就绪队列的vruntime值。ps:cfs_rq为普通进程的就绪队列,声明如下
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */static inline void __update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr, unsigned long delta_exec)
{
unsigned long delta_exec_weighted;
schedstat_set(curr->exec_max, max((u64)delta_exec, curr->exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);
delta_exec_weighted = calc_delta_fair(delta_exec, curr);
curr->vruntime += delta_exec_weighted;
update_min_vruntime(cfs_rq);
}可以看到,update_curr函数首先累计了实际的运行时间(Line:7),然后调用calc_delta_fair(delta_exec,curr)对delta_exec进行加权计算(Line:9)(至于如何进行加权计算没有再深入研究),然后再将加权计算的结果累计加入vruntime(Line:11),最后更新并保存cfs_rq队列中的的最小虚拟运行时间(Line:12)。由此,我们可以大概看到vruntime产生的整个过程。
5.3.2关于决定下一个进程
CFS用红黑树来调度实体SE,而键值则是虚拟运行时间vruntime,CFS会选择具有最小vruntime值的进程作为下一个进程,而这个进程,实际上就是红黑树中的最左叶子节点。CFS调度器中有pick_next_task_fair()用于选择下一个进程。
static struct task_struct *pick_next_task_fair(struct rq *rq)
{
struct task_struct *p;
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
if (!cfs_rq->nr_running)
return NULL;
do {
se = pick_next_entity(cfs_rq);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
hrtick_start_fair(rq, p);
return p;
}实际上用于选择下一个进程的函数在11行:pick_next_entity(cfs_rq)
/*
* Pick the next process, keeping these things in mind, in this order:
* 1) keep things fair between processes/task groups
* 2) pick the "next" process, since someone really wants that to run
* 3) pick the "last" process, for cache locality
* 4) do not run the "skip" process, if something else is available
*/
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
/*
* If curr is set we have to see if its left of the leftmost entity
* still in the tree, provided there was anything in the tree at all.
*
*/
if (!left || (curr && entity_before(curr, left)))
{
left = curr;
}
se = left; /* ideally we run the leftmost entity */
if (cfs_rq->skip == se)
{
struct sched_entity *second;
if (se == curr)
{
second = __pick_first_entity(cfs_rq);
}
else
{
second = __pick_next_entity(se);
if (!second || (curr && entity_before(curr, second)))
second = curr;
}
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
/*
* Prefer last buddy, try to return the CPU to a preempted task.
*
*
*/
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
/*
* Someone really wants this to run. If it's not unfair, run it.
*/
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
clear_buddies(cfs_rq, se);
return se;
}这段代码实现了选中红黑树中最左叶子节点的进程,并将其从树上移除,更新红黑树。至此,下一个进程已经成功选出了。
6.感想与看法
Linux自0.01版问世以来,就从未停止过变化,发展至今,已经有无数的程序员们为Linux贡献了自己的代码,于是展现在我们眼前的,是一个无比精妙成熟的系统架构。我们无法知道未来的linux会进化成什么模样,至少在今天,我们看到了CFS,利用简单的vruntime机制,就实现了以往复杂度为O(n)的算法才能实现的需求,不得不感叹这个系统背后的人们付出的努力。当然,CFS的完全公平,也并不是所有进程绝对的平等,而是体现在虚拟运行时间上,实际上其更新和增长的速度是并不一样的。能否完全兼顾到效率与公平,答案只能交给时间来告诉我们了。
7.参考资料
1.Linux进程调度CFS算法实现分析
2.进程——维基百科,自由的百科全书
3.TASK_KILLABLE: New process state in Linux
4.《鸟哥的Linux私房菜》,鸟哥,人民邮电出版社