Ceph 撸源码系列(三):Ceph OSDC源码分析 (1 of 2)
转载:Ceph OSDC源码分析
1.OSDC是什么

OSDC其实是一个osd client模块的简称,在rbd和cephfs两个应用中都用到了,这个模块主要用来跟rados交互,这个模块里面完成了几个主要的功能:
(1) 地址空间的转换:从rbd或者cephfs文件的一维地址空间转换到对象的三维地址空间(后面会讲到什么是三维地址空间,objectset,stripeno,stripepos),也简称为对象化
(2) objectcacher:一个object级别的缓存
(3) Crush算法定位osd:在转化为三维地址空间之后,就使用Crush算法进行对象的数据定位
OSDC的再次定位
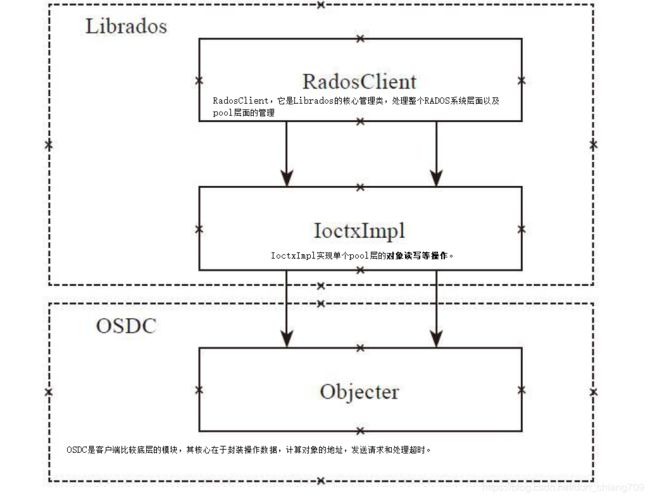
本文主要是介绍前两点(地址转换 和 objectcacher),小甲师兄14年刚开始接触ceph使用的是0.80.5版本(firefly),本文的分析是基于10.2.2(jewel),现在使用的是12.2.10(luminous),虽然版本跨度比较大,但是这部分代码还是比较稳定的,基本大的框架没有变化。这里以cephfs的文件读流程进行分析。
2.介绍一个文件的读
这里使用fuse进行挂载cephfs,因为用户态的客户端才会调用OSDC,如果使用内核态的客户端的话,是不会经过OSDC代码的,会走内核的一个osd client代码,估计功能跟OSDC类似,不过内核的osd client的缓存是使用的内核中的一些缓存机制。
2.1 用户态文件请求
用户态文件请求的流程大致如下:
(1)posix标准:open、read、write
(2)系统调用
(3)vfs虚拟机文件系统
(4)fuse内核模块
(5)fuse的用户态库
(6)cephfs的用户态客户端代码
(7)最终到达client::read()或者client::write()处理函数
2.2 client::read()
从client::read()起的流程图如下
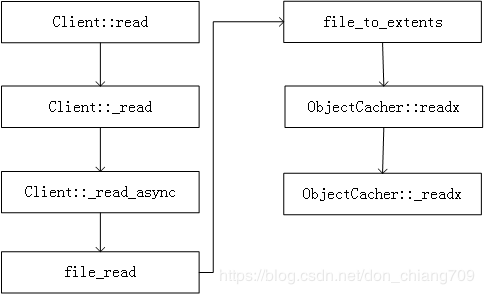
其中file_to_extents函数就是完成OSDC的第一个功能:地址空间的转换
2.3 地址空间的转换
先贴一个对象条带分片图,也就是地址空间转换图,如下图所示:

这个对象分片图,是不是有点像raid0,对,就是将raid0中的磁盘换成了对象,并对对象进行了条带分片。
按上图介绍几个概念
(1)蓝色柱状代表一个个rados底层对象,默认为4M
(2)绿色块su代表条带单元
(3)红色框stripe代表一个个条带
(4)objectset代表对象组,一般一个对象组属于同一个文件(cephfs)
这里要说明一点,Ceph系统默认没有开启对象条带分片
再介绍几个变量
(1)object_size:对象的大小,就是rados底层对象的大小,一般默认是4M
(2)su:对象分片大小,以上面的图为例就是4/3M
(3)stripe_count:条带宽度,也就是一个strip跨多少个对象,也就是一个objectset中对象的个数,以上面的图为例,值为3
(4)stripes_per_object:一个对象包含的对象分片数,以上图为例值为3
file_to_extent
file_to_extent函数就是以raid0的思想来分片,一个个条带连起来可以看成是逻辑上面连续的,相当于线性的一维地址空间。现在要通过file_to_extent函数把一维坐标转化成三维坐标(objectset,stripeno,stripepos),这三维坐标分别表示哪一个objectset,哪一个stripe(条带),条带中的哪一个su(对象分片)。小甲以一个读操作来分析,示例分析如下:

这里假设一个对象大小是3M,一个对象分片大小是1M,假设我们要读的文件占用两个objectset,占用6个rados的对象,18个对象分片,小甲这里要读取这个文件的对象分片的序号是从第1到第6,也就是文件的2M~7M的范围,相应的变量如下所示:
offset = 1M 表示读偏移量
len = 6M 表示要读取的大小
su = 1M
object_size = 3M
stripe_count = 3
stripes_per_object = 3
可以看到上面的地址空间已经从一维转化成了三维:
比如读取su1
一维地址空间:(offset, len) ==>(1M,6M)
三维地址空间:(objectset,stripeno,stripepos) ==> (objectset0,stripe0,object1)
对象名的组成
这里的对象指的是rados底层的对象,也就是使用filestore时,xfs上面一个个4M的小文件,那这个文件的名字是怎么组成的呢,小甲顺便也分析了一下。
这里先说明一个类ObjectExtent,这个是用来保存一个对象内的分片的信息,注意这个类不保存内容,只是保存分片的位置信息:偏移和长度。
//////////////////////////////////////osd_types.h
class ObjectExtent {
/**
* ObjectExtents are used for specifying IO behavior against RADOS
* objects when one is using the ObjectCacher.
*
* To use this in a real system, *every member* must be filled
* out correctly. In particular, make sure to initialize the
* oloc correctly, as its default values are deliberate poison
* and will cause internal ObjectCacher asserts.
*
* Similarly, your buffer_extents vector *must* specify a total
* size equal to your length. If the buffer_extents inadvertently
* contain less space than the length member specifies, you
* will get unintelligible asserts deep in the ObjectCacher.
*
* If you are trying to do testing and don't care about actual
* RADOS function, the simplest thing to do is to initialize
* the ObjectExtent (truncate_size can be 0), create a single entry
* in buffer_extents matching the length, and set oloc.pool to 0.
*/
public:
object_t oid; // object id
uint64_t objectno;
uint64_t offset; // in object
uint64_t length; // in object
uint64_t truncate_size; // in object
object_locator_t oloc; // object locator (pool etc)
vector > buffer_extents; // off -> len. extents in buffer being mapped (may be fragmented bc of striping!)
ObjectExtent() : objectno(0), offset(0), length(0), truncate_size(0) {}
ObjectExtent(object_t o, uint64_t ono, uint64_t off, uint64_t l, uint64_t ts) :
oid(o), objectno(ono), offset(off), length(l), truncate_size(ts) { }
}; 分片的结果会保存在一个map中
map > object_extent
map的key是一个对象的名字,这个名字就是存在磁盘上面每一个对象对应文件的文件名的前缀,比如,磁盘上面一个对象的文件名为:
10000000000.00000000__head_F0B56F30__1
其中10000000000.00000000这个由点号隔成了两部分,点号前面的10000000000是一个文件的元数据inode号,后面00000000是文件内容分配所在的对象号,这个对象号有点特殊代码中叫做objectno,我们来具体讨论一下。
首先每一个文件都是可以分片的对象,按照分片算法,这里分片所对应的对象应该都是从0开始标号的,那这样对象的名字不就重复了吗?不急,我们每一个文件的inode号是一个唯一的这个inode号是由mds中的inodetable维护的,保证唯一,那就可以使用文件的元数据inode号和刚刚可以重复利用的objectno就组成了上面我们看到的由点号分开的对象名前缀,其实这个感觉就像我们的网络,在openstack中我们可以给每一个租户分配一个网络,网络里面可以自己划分子网,不同租户的子网的网段是可以重复的,因为他们就相当于一个局域网,可以重复利用,这里面的objectno就相当于局域网段,可以重复利用,但是和inode号合在一起就是一个全局唯一的,就是存储在磁盘上面的前缀。
下一篇:Ceph 进阶系列(三):Ceph OSDC源码分析 (2 of 2)
参考:
Ceph源码分析