一个实例说明Tp,Fp,Fn,Tn,mAP
由于最近在作图像检索。那么就有一个评价指标的问题。在网上一搜,尼玛,跟念经的一样。晦涩难懂。
这里,用一个实例说明。
1、背景
假设现在医院有医生给人测血糖,共100人。为了方便,我们分两类人,不正常(N),正常(P)。
groundtruth: 不正常(30),正常 (70)。
doctor predict: 不正常(40),正常(60)。
实际山,和这个预测的高血糖中真正高的,有24人。那16人不高。
预测正常的人真正正常的有54人,那6个人高血糖。
True Positive:我们把这个词分成两部分,true。说明医生测对了。Positive,说明测试结果是正常。
其余的类似。这两个词都是针对预测结果而言的。
2、建模
现在我们做混淆矩阵(Confusion Matrix)
| 、 | groundtruth=Positive | groundtruth=Negative |
|---|---|---|
| predict=Positive | True Positive | False Positive |
| predict=Negative | False Negative | True Negative |
| 、 | groundtruth=Positive | groundtruth=Negative |
|---|---|---|
| predict=Positive | 54 | 6 |
| predict=Negative | 16 | 24 |
3、PR曲线
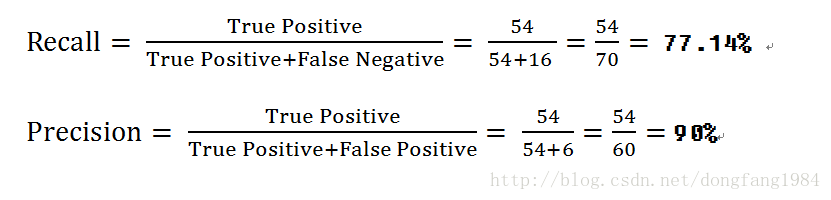
我们看到其实Recall 与Precision 都只关心,【True Positive】 的百分比。有些片面
来看一个极限:【医生预测所有的人都正常】
| 、 | groundtruth=Positive | groundtruth=Negative |
|---|---|---|
| predict=Positive | 70 | 30 |
| predict=Negative | 0 | 0 |
·
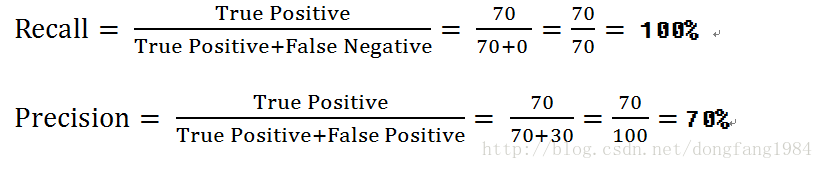
另一端的极限:【医生预测所有人都不正常】
| 、 | groundtruth=Positive | groundtruth=Negative |
|---|---|---|
| predict=Positive | 0 | 0 |
| predict=Negative | 70 | 30 |
由于True Positive =0 ,结果为0。
4小结
Recall , Precision 都只关心 模型对于正样本的的预测情况。
因此还有一个常用的标准:Accuracy (看看100道判断题得了多少分).
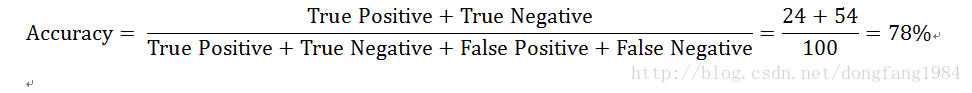
那有没有一个模型或者评判标准,综合考量模型。而不是像上面那样,单看一个评价标准没有实用价值。
有,就是F1 Measure

实际上,我们往往希望得到Precision 与Recall 相差不大的模型。也就是对于一个模型,我们希望F1 Score高。
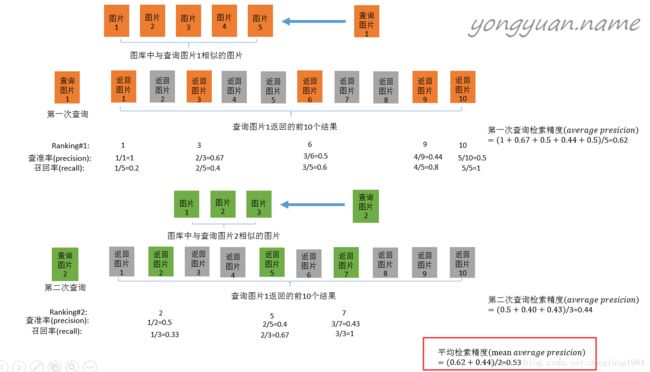
mAP(mean average precision)
这张图片来自于:http://yongyuan.name/blog/evaluation-of-information-retrieval.html 。博主写的很好。这里贴出来。供大家参考。很佩服。