Cannot allocate memory /Resource temporarily unavailable 故障分析
前言:
Linux 内核有个机制叫OOM killer(Out-Of-Memory killer),该机制会监控那些占用内存过大,尤其是瞬间很快消耗大量内存的进程,为了防止内存耗尽而内核会把该进程杀掉。典型的情况是:某天一台机器突然ssh远程登录不了,但能ping通,说明不是网络的故障,原因是sshd进程被OOM killer杀掉了(多次遇到这样的假死状况)。重启机器后查看系统日志/var/log/messages会发现Out of Memory: Kill process 1865(sshd)类似的错误信息。
客户工单详情如下:
![]()
首先思考限制一个进程的创建条件涉及哪些方面资源的问题
进程无法创建了,可能原因,pid耗尽、open files等资源耗尽、内存耗尽、有充足的内存,但还是会触发OOM(是因为该进程可能占用了特殊的内存地址空间)
下面逐一展开分析
一、pid耗尽类
1、问题分析
查看当前进程数:ps -eLf | wc -l
查看pid_max数目:# sysctl kernel.pid_max
通过上述数值比较可确定是否是pid耗尽导致进程fork失败
2、解决方案
修改数目:sysctl -w kernel.pid_max=65535(适加较上次增加,64位系统上pid_max最大值为2^22,32位系统上最大值为32768)
#echo 1000000 > /proc/sys/kernel/pid_max 临时生效
#echo "kernel.pid_max=1000000 " >> /etc/sysctl.conf
#sysctl -p 永久生效
3、故障复现
a、查询pid_max值并修改(原来值挺大,为了测试改小点,模拟pid资源不足)
# sysctl kernel.pid_max
kernel.pid_max = 32768
# sysctl -w kernel.pid_max=500
kernel.pid_max = 500
b、创建自动fork进程脚本
 f
f
c、编译后运行
# gcc test.c; #./a.out
![]()
再用其他终端试图ssh该测试环境,发现无法登录。
d、 在其他已经连接该测试环境的终端(运行a.out之前就连接好)试图执行free或者其他命令,结果报错

e、增大pid数目:
# sysctl -w kernel.pid_max=32768,count is 2046,明显看到count数目提升
二、内存耗尽类
1、问题分析
内存耗尽主要是因为内核系统进程、用户业务程序在大量占用内存、或者是内存泄漏
进程fork失败,在小内存的进程上做一个fork,不需要太多资源,但当这个进程的内存空间以G为单位时,fork就成为一件很恐怖的操作。比如在16G内存的主机上fork 14G内存的进程呢?肯定会报内存无法分配的。
首先可以通过free、top命令判断是否是内存资源不足,再 通过meminfo查看内存的使用情况以及通过cat /proc/slabinfo 查看具体的mem使用情况。以上三个方法可以初步的排查,是否是因为内核或者用户程序在占用内存,达到初步定为问题的目的


对于僵尸进程导致的内存不足排查,也可以通过查看message里面的日志信息 :cat /var/log/messages|grep -i error。下图是systemd进程发生bug,导致不再wait子进程,不再回收结束进程信息,导致出现大量僵尸进程;用户crontab中,凡是末尾加了“&”,即,以后台进程运行的任务,其父进程都将变成systemd(1号进程),进而导致这些进程全部变成僵尸进程。
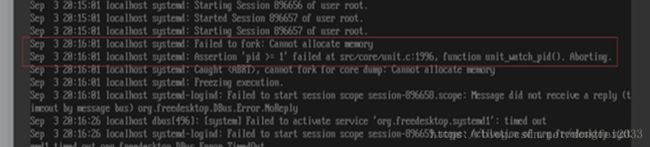
2、解决方案
a、 增大内存条(条件允许,优先选择)或通过手动释放内存缓存的形式来进行释放。
To free pagecache:
- echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes:
- echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes:
- echo 3 > /proc/sys/vm/drop_caches
b、内存不足并且没有启用交换空间,要启用交换,可以使用:
/bin/dd if=/dev/zero of=/var/swap.1 bs=1M count=1024
/sbin/mkswap /var/swap.1
/sbin/swapon /var/swap.1
c、对于僵尸进程问题
僵尸进程增多,无法kill -9,在系统死机的情况下只能重启恢复,升级systemd。如果可以在不重新启动服务器的情况下,停止占用系统资源的进程,则应检查所有必需的系统守护程序是否仍在运行。如果无法正常登录以查看正在进行的操作,请尝试从系统控制台以root用户身份登录。当系统资源不足时,控制台比常规登录略有优势。
d、保护重要进程不被内核杀掉
运维过程中保护的一般是sshd和一些管理agent。保护某进程不被内核杀掉可以这样操作:
# echo -17 > /proc/$PID/oom_adj
比如:防止sshd被杀,可以这样操作:
# pgrep -f "/usr/sbin/sshd" | while read PID;do echo -17 > /proc/$PID/oom_adj;done
可以在计划任务里加入这样一条定时任务,就更安全了:
#/etc/cron.d/oom_disable
*/1**** root pgrep -f "/usr/sbin/sshd" | while read PID;do echo -17 > /proc/$PID/oom_adj;done
为了避免重启失效,可以写入/etc/rc.d/rc.local
echo -17 > /proc/$(pidof sshd)/oom_adj
【还可以通过修改内核参数禁止OOM机制# sysctl -w vm.panic_on_oom=1 vm.panic_on_oom = 1 //1表示关闭,默认为0表示开启OOM # sysctl -p】(非必须情况下不建议修改)
补充:通过echo 1 >/proc/sys/vm/overcommit_memory,修改vm.overcommit_memory值
(修改vm.overcommit_memory参数方法与上述d方法不同,它会产生副作用就是此时cvm上的服务已经不能正常运行了,方法只是保证系统不hang住,而d方法的进程是可运行)
Linux内核会根据参数vm.overcommit_memory参数的设置决定是否放行(默认为0)
vm.overcommit_memory = 1,直接放行。echo 1 >/proc/sys/vm/overcommit_memory
vm.overcommit_memory = 0:则比较 此次请求分配的虚拟内存大小和系统当前空闲的物理内存加上swap,决定是否放行。
vm.overcommit_memory = 2:则会比较 进程所有已分配的虚拟内存加上此次请求分配的虚拟内存和系统当前的空闲物理内存加上swap,决定是否放行。
3、故障复现
a、在没有内存,没有pid限制的情况下编译后运行# gcc test.c; ./a.out,结果如图

b、使用压力测试-memtester工具打压
下载
wget http://pyropus.ca/software/memtester/old-versions/memtester-4.2.2.tar.gz
安装
tar zxvf memtester-4.2.2.tar.gz
cd memtester-4.2.2
make && make install
# nohup memtester 1500M > /tmp/memtest.log &

再行./a.out,结果如图

三、最大文件打开数限制
1、问题分析
意思是说程序打开的文件数过多,不过这里的files不单是文件的意思,也包括打开的通讯链接(比如socket),正在监听的端口等等,所以有时候也可以叫做句柄(handle),这个错误通常也可以叫做句柄数超出系统限制。 引起的原因就是进程在某个时刻打开了超过系统限制的文件数量以及通讯链接数,通过命令ulimit -a可以查看当前系统设置的最大句柄数
2、解决方案
a、命令行输入:#ulimit -n 2048 (临时生效)或通过vi /etc/profile修改,在最后行加入:ulimit -n 32768
b、vim /etc/security/limits.conf (永久修改)
#在最后加入
* - nofile 8192 ( * 表示所有用户,可根据需要设置某一用户)
3、故障复现
初始状态

![]()
执行#./a.out后中端断联,重新开一个终端也登陆不进去
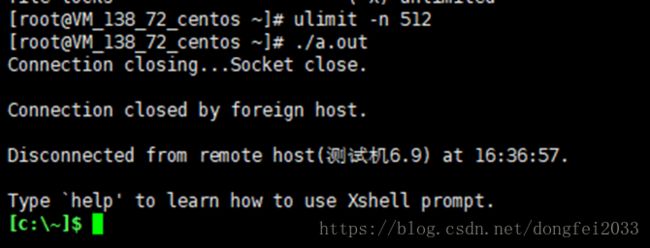

复现现象成功!
补充方法:有时可能是由于服务器本身或特定于您的用户帐户的某些资源限制。可以通过#ulimit -a检查shell中的限制
#ulimit -u检查最大用户进程
四、总结
对于内存泄漏问题,多是由于程序开发时的代码逻辑不好,这里不讨论,还有有时用户业务程序导致业务进程数增多,通过增大进程数解决问题。但是由于在进程数达到很高时,内存已经几乎耗尽,所以增大进程数只是缓解。建议用户优化业务代码!