win7下eclipse插件连接linux下hdfs单机伪集群 hadoop 2.6
1、首先在linux上搭建好单击伪集群,这里是参考教程:点击打开链接
2、下载好eclipse连接hdfs的插件,要统一版本,这里linux使用的是64位的centos 6.4,hadoop是2.6,所所以的插件是hadoop-eclipse-plugin-2.6.0.jar,下载地址:点击打开链接
3、重启eclipse,会出现这个:
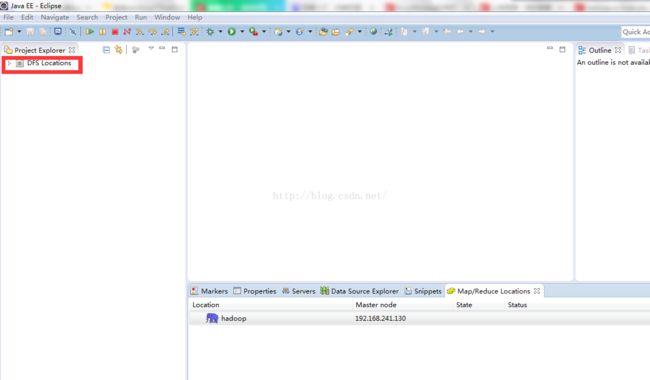
4、hadoop在windows上也要有一份,然后就是linux,windows上jdk的版本最好统一,现在开始配置eclipse,在上图中的Mapreduce Loccations窗口,点击小象,窗口在window-》show view-》other里面可以找到,就是在视图里找。
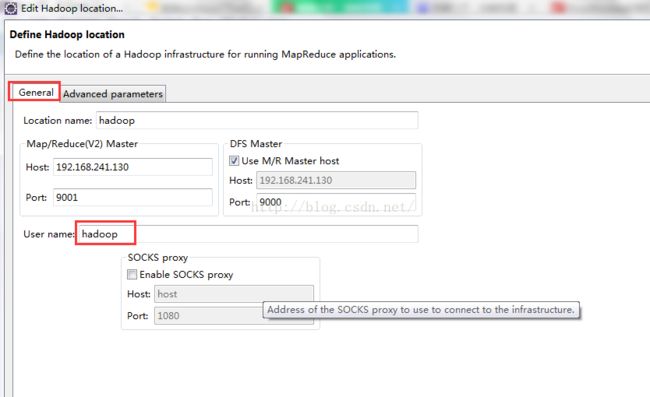
5、首先设置general选项卡,Location name无所谓,可以随便写,Map/Reduce (V2)Master和DFS Master里面设置好IP和端口,分别对应配置文件mapred-site.xml、core-site.xml,User name使用搭建hadoop使用的用户,这里我用的是hadoop这个用户。然后点完成,重启eclipse。这里需要注意的是,主机eclipse连接虚拟机上的hdfs,一定要保证hdfs启动成功,可以先通过主机浏览器,查看http:IP:50070,如果没有连接上,则检查linux防火墙是否关闭,(使用root用户关闭防火墙,有时候用普通用户关闭防火墙的时候,没有任何提示,还以为i是正常关闭了)。
6、然后设置advanced选项卡:
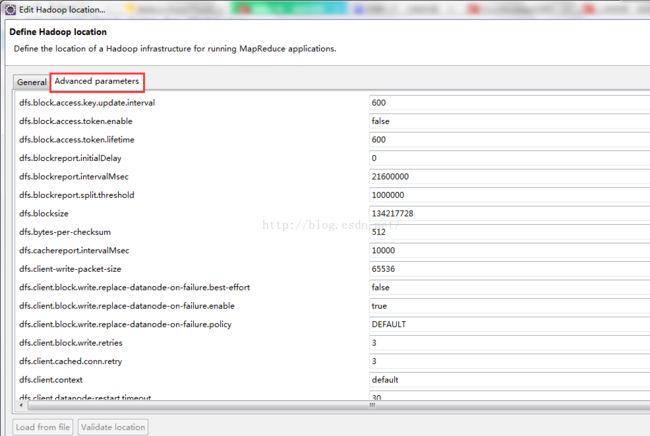
这里大部门属性都已经自动填写上了,读者可以看到,这里其实就是把 core-defaulte.xml,hdfs-defaulte.xml,mapred-defaulte.xml里面的一些配置属性展示在这,因为我们安装hadoop的时候,还在site系列配置文件里有改动,所以这里也要弄成一样的设置。
主要关注的有以下属性
fs.defualt.name:这个在General tab页已经设置了。
mapred.job.tracker:这个在General tab页也设置了。
dfs.replication:这个这里默认是3,因为我们再hdfs-site.xml里面设置成了1,所以这里也要设置成1
hadoop.tmp.dir:这个默认是/tmp/hadoop-{user.name},因为我们在ore-defaulte.xml 里hadoop.tmp.dir设置的是/usr/local/hadoop/hadooptmp,所以这里我们也改成/usr/local/hadoop/hadooptmp,其他基于这个目录属性也会自动改
hadoop.job.ugi:这里要填写:root,Tardis,逗号前面的是连接的hadoop的用户,逗号后面就写死Tardis。
然后点击finish,然后就连接上了。
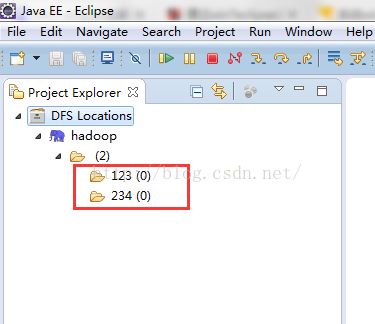
7、虚拟机上的hdfs上的文件夹有两个,连接如下:
8、新建mapreduce项目:
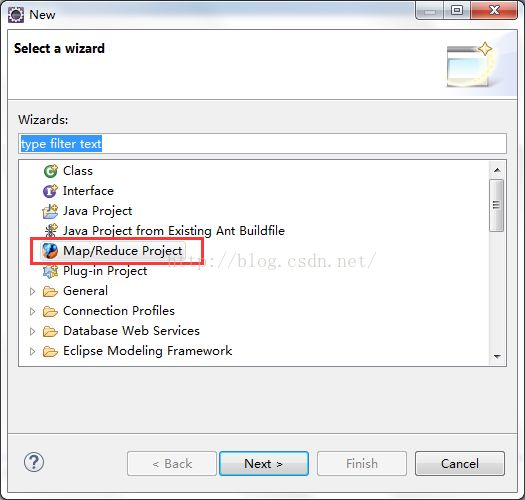
因为项目是关联了windows上hadoop文件目录,所以会有很多引入库:
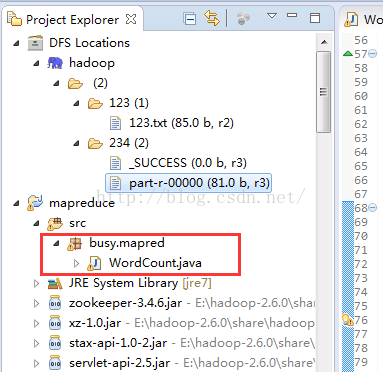
9、新建一个WordCount测试程序,代码如下:
package busy.mapred;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends
Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken().toLowerCase());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
这里需要注意:为了防止hdfs文件系统的权限问题,需要在hdfs-site.xml配置文件中:
dfs.permissions
false
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
其次就是单机伪集群的hadoop安装文件的conf配置文件,三个core-site.xml mapred-site.xml hdfs-site.xml,最好linux虚拟机里的hadoop文件夹和windows里的hadoop文件夹要相统一。
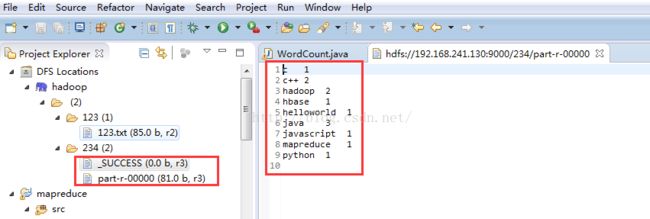
10、在虚拟机hdfs中新建一个输入文件夹123,下面新建一个文本文件123.txt,输出文件夹234不需要新建,程序会自动建立(自己新建会报错),然后配置一下WordCount的参数:

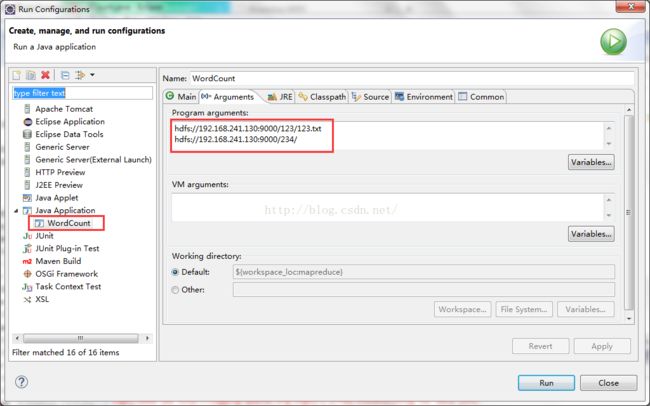
这里需要注意的是:网上有一些WordCount例程可能不是读取绝对路径,所以如果运行结果不对,可以试着直接用根目录下的文件路径比如:/123/123.txt /234/这样。
11、因为在windows下编译和运行hdfs相关程序需要一些库文件和运行文件,主要是两个:hadoop.dll和winutils.exe,第一个放在c://windows/system32里面(可以消除NULL指针报错),第二个放到windows的hadoop文件夹下的bin目录下,同时在windows环境变量中加入HADOOP_HOME路径,和%HADOOP_HOME%\bin。这里提供windows7 64位系统下编译的,hadoop2.6版本的这两个编译和运行文件的下载地址:点击打开链接
如果版本不同请不要下载,请下载对应版本的这两个文件。
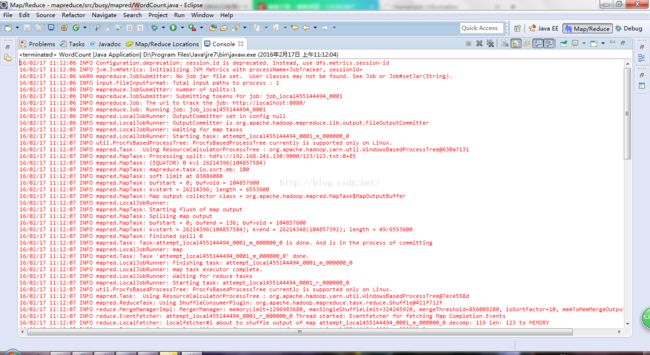
12、run application或者run on hadoop,理论上应该是能正常运行的,运行结果如下:
13、关于log4j日志的警告问题:

结果运行正确,但是没有信息打印,只有log4j的警告信息,因为项目中没有log4j.properties 文件,直接拷贝hadoop/etc目录下的该文件到WordCount的项目src目录下,然后更新即可。
14、如果需要保存日志在本地项目目录,就把log4j.properties 文件的内容改为:
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=DEBUG
15、最近在32位linux上测试程序顺便也弄了个插件调试,结果发现还是有些问题:
第一个:
DEBUG - Failed to detect a valid hadoop home directory
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.
at org.apache.hadoop.util.Shell.checkHadoopHome(Shell.java:302)
at org.apache.hadoop.util.Shell.(Shell.java:327)
at org.apache.hadoop.util.GenericOptionsParser.preProcessForWindows(GenericOptionsParser.java:438)
at org.apache.hadoop.util.GenericOptionsParser.parseGeneralOptions(GenericOptionsParser.java:484)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:170)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:153)
at com.busymonkey.WordCount.main(WordCount.java:54)
ERROR - Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370)
at org.apache.hadoop.util.Shell.(Shell.java:363)
at org.apache.hadoop.util.GenericOptionsParser.preProcessForWindows(GenericOptionsParser.java:438)
at org.apache.hadoop.util.GenericOptionsParser.parseGeneralOptions(GenericOptionsParser.java:484)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:170)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:153)
at com.busymonkey.WordCount.main(WordCount.java:54) 我发现即使我设置了环境变量依然无法运行程序,并且提示以上错误。这时只能在main函数里加上一句话,直接指向根目录:
System.setProperty("hadoop.home.dir", "D:\\hadoop-2.6.4");
这里还是很奇葩,好像还是要设置环境变量,并且重启计算机。
第二个:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z我发现hadoop.dll这个文件之前测试的时候放在system32下可以用,现在不行了,于是放在windows的hadoop/bin目录下又可以,好奇葩。
想要查看文件系统或者mr应用日志(50070,8088,19888端口):
yarn-site.xml 添加:
yarn.nodemanager.aux-services
mapreduce_shuffle
mapreduce.framework.name
yarn
yarn.log-aggregation-enable
true
mapreduce.jobhistory.address
192.168.75.129:10020
mapreduce.jobhistory.webapp.address
192.168.75.129:19888
开启historyserver:
sbin/mr-jobhistory-daemon.sh start historyserver