perl学习笔记1
perl学习笔记1


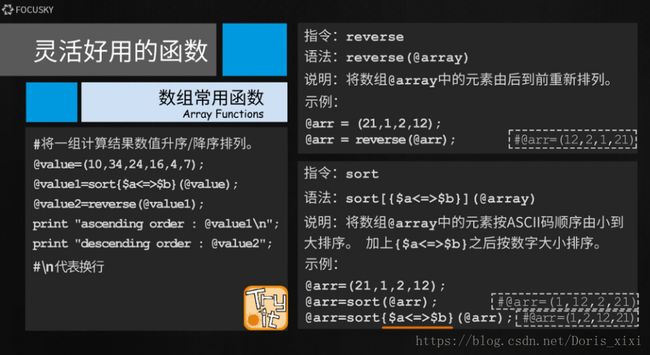






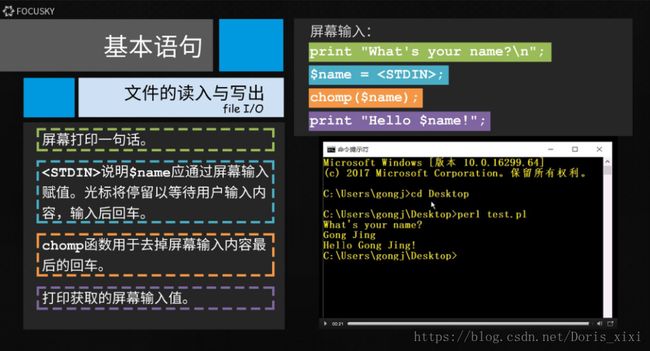

1.perl语言的输入
单行大文件的处理:
my $oneline = <$FL> 或 while($line=){ } 读取全部(小文件的处理)
open (my $in, "path ") or die "open error: $! ";
my @lines = <$in> ;读3行以及大文件的特殊处理
open (my $in, "path ") or die "open error: $! ";
my @lines;
push (@lines, scalar <$in> ) for (1..3); (1)行标准输入:
操作符:
$line =
chomp($line); #去掉结尾的换行符
chomp($line=
另一种写法:
while(
print “I saw $_”;
}
或者可以这样写:
while (defined($_ =
print“I saw $_”;
}
(2)使用<>输入:
while(<>){
chomp;
print “It was $_ that I saw!\n”;
}
<>通常用来处理所有的输入,因此在同一个序中重复使用是不正确的。如果在同一个程序中使用了2次<>,特别是
在while循环内第二次使用<>读入第一次<>的值,其结果通常不是你所希望的。当初学者在程序中使用第二个<>,通常是想使用$_。记住,<>读入输入,但输入内容本身被存储在$_(默认的情形)。
注:如果<>不能打开文件从中读入,它将打印出一些有用的诊断信息,如:
Can’t openwilma: no such file or directory
<>将自动转到下一个文件,这和cat这个标准工具是一致的。
2.perl语言的输出
(1)标准输出:print
print @array; #打印出元素的列表
print“@array”; #打印一个字符串(包含一个内插的数组)
第一个语句打印出所有的元素,一个接着一个,其中没有空格。
第二个打印出一个元素,它为@array的所有元素,其被存在一个字符串中。
例如:@array包含qw /fred barney betty/
第一个例子输出为:fredbarneybetty
第二个例子输出为fred barney betty(由空格分开)。
如果@array为一个unchomped的输入列。即每一个字符串都有一个换行符作为后缀。
第一个例子print语句输出为fred, barney, betty,分别在三行中。
第二个print语句输出为:
fred
barney
betty
(2)使用printf格式化输出:
my @items = qw( wilma dino pebbles );
my $format =“The items are:\n”. (“%10s\n”x @items);
## print“the format is >>$format<<\n”; #用于调试
printf $format, @items;
x操作:确定字符串要重复的次数,此次数由@items中元素的个数确定的本例中为3,因此上述的格式字符串等同于“The items are:\n10s\n10s\n10s\n”。输出的每一个元素占一行,右对齐,长度为10。
另一个方法可以把它们结合起来使用:
printf“The items are:\n”. (“%10s\n”x @items), @items;
本例中使用了@items两次,一次在标量context中,取其元素的个数,一次在列表context中取其元素。
3.perl语言正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
Perl的正则表达式的三种形式,分别是匹配、替换、转化:
匹配:m//(还可以简写为//,略去m)
替换:s///
转化:tr///
这三种形式一般都和 =~ 或 !~ 搭配使用, =~ 表示相匹配,!~ 表示不匹配。
(1)匹配
#!/usr/bin/perl
$bar = "I am runoob site. welcome to runoob site.";
if ($bar =~ /run/){
print "第一次匹配\n";
}else{
print "第一次不匹配\n";
}结果:
第一次匹配模式匹配有一些常用的修饰符,如下表所示:
| 修饰符 | 描述 |
|---|---|
| i | 忽略模式中的大小写 |
| m | 多行模式 |
| o | 仅赋值一次 |
| s | 单行模式,"."匹配"\n"(默认不匹配) |
| x | 忽略模式中的空白 |
| g | 全局匹配 |
| cg | 全局匹配失败后,允许再次查找匹配串 |
perl处理完后会给匹配到的值存在三个特殊变量名:
- $`: 匹配部分的前一部分字符串
- $&: 匹配的字符串
- $': 还没有匹配的剩余字符串
(2)替换
基本格式:
s/PATTERN/REPLACEMENT/;含义:用REPLACEMENT的内容去替换PATTERN。
#!/usr/bin/perl
$string = "welcome to google site.";
$string =~ s/google/runoob/;
print "$string\n";结果:
welcome to runoob site.替换操作修饰符如下表所示:
| 修饰符 | 描述 |
|---|---|
| i | 如果在修饰符中加上"i",则正则将会取消大小写敏感性,即"a"和"A" 是一样的。 |
| m | 默认的正则开始"^"和结束"$"只是对于正则字符串如果在修饰符中加上"m",那么开始和结束将会指字符串的每一行:每一行的开头就是"^",结尾就是"$"。 |
| o | 表达式只执行一次。 |
| s | 如果在修饰符中加入"s",那么默认的"."代表除了换行符以外的任何字符将会变成任意字符,也就是包括换行符! |
| x | 如果加上该修饰符,表达式中的空白字符将会被忽略,除非它已经被转义。 |
| g | 替换所有匹配的字符串。 |
| e | 替换字符串作为表达式 |
(3)转化
转化操作符相关的修饰符:
修饰符
描述
c
转化所有未指定字符
d
删除所有指定字符
s
把多个相同的输出字符缩成一个
#!/usr/bin/perl
$string = 'welcome to runoob site.';
$string =~ tr/a-z/A-z/;
print "$string\n";结果为:
WELCOME TO RUNOOB SITE.运用参数的实例(运用s):
#!/usr/bin/perl
$string = 'runoob';
$string =~ tr/a-z/a-z/s;
print "$string\n";
运行结果:
runob更多实例:
$string =~ tr/\d/ /c; # 把所有非数字字符替换为空格
$string =~ tr/\t //d; # 删除tab和空格
$string =~ tr/0-9/ /cs # 把数字间的其它字符替换为一个空格。(4)更多正则表达式规则
| 表达式 | 描述 |
|---|---|
| . | 匹配除换行符以外的所有字符 |
| x? | 匹配 0 次或一次 x 字符串 |
| x* | 匹配 0 次或多次 x 字符串,但匹配可能的最少次数 |
| x+ | 匹配 1 次或多次 x 字符串,但匹配可能的最少次数 |
| .* | 匹配 0 次或多次的任何字符 |
| .+ | 匹配 1 次或多次的任何字符 |
| {m} | 匹配刚好是 m 个 的指定字符串 |
| {m,n} | 匹配在 m个 以上 n个 以下 的指定字符串 |
| {m,} | 匹配 m个 以上 的指定字符串 |
| [] | 匹配符合 [] 内的字符 |
| [^] | 匹配不符合 [] 内的字符 |
| [0-9] | 匹配所有数字字符 |
| [a-z] | 匹配所有小写字母字符 |
| [^0-9] | 匹配所有非数字字符 |
| [^a-z] | 匹配所有非小写字母字符 |
| ^ | 匹配字符开头的字符 |
| $ | 匹配字符结尾的字符 |
| \d | 匹配一个数字的字符,和 [0-9] 语法一样 |
| \d+ | 匹配多个数字字符串,和 [0-9]+ 语法一样 |
| \D | 非数字,其他同 \d |
| \D+ | 非数字,其他同 \d+ |
| \w | 英文字母或数字的字符串,和 [a-zA-Z0-9_] 语法一样 |
| \w+ | 和 [a-zA-Z0-9_]+ 语法一样 |
| \W | 非英文字母或数字的字符串,和 [^a-zA-Z0-9_] 语法一样 |
| \W+ | 和 [^a-zA-Z0-9_]+ 语法一样 |
| \s | 空格,和 [\n\t\r\f] 语法一样 |
| \s+ | 和 [\n\t\r\f]+ 一样 |
| \S | 非空格,和 [^\n\t\r\f] 语法一样 |
| \S+ | 和 [^\n\t\r\f]+ 语法一样 |
| \b | 匹配以英文字母,数字为边界的字符串 |
| \B | 匹配不以英文字母,数值为边界的字符串 |
| a|b|c | 匹配符合a字符 或是b字符 或是c字符 的字符串 |
| abc | 匹配含有 abc 的字符串(pattern) () 这个符号会记住所找寻到的字符串,是一个很实用的语法.第一个 () 内所找到的字符串变成 $1 这个变量或是 \1 变量,第二个 () 内所找到的字符串变成 $2 这个变量或是 \2 变量,以此类推下去. |
| /pattern/i | i 这个参数表示忽略英文大小写,也就是在匹配字符串的时候,不考虑英文的大小写问题.\ 如果要在 pattern 模式中找寻一个特殊字符,如 "*",则要在这个字符前加上 \ 符号,这样才会让特殊字符失效 |
参考:
正则表达式参考:http://www.runoob.com/perl/perl-regular-expressions.html
输入输出参考:https://blog.csdn.net/mikiah/article/details/8003900
perl教程:http://www.runoob.com/perl/perl-formats.html