0x00 注明
合作者:201631062315 201631062310
代码地址:https://gitee.com/c1e4r/word-count2
作业地址:https://edu.cnblogs.com/campus/xnsy/2018softwaretest2398/homework/2187
0x01 互审代码情况
在完成本次作业的期间,同一位同学进行了合作,大概就是相互之间测试对方的程序,已达到软件测试的目的。
发现的问题:
1.在进行文件操作的时候报错,经分析报错后发现是在打开某一文件时未统一编码规范。文件是gbk编码,在打开文件的时候要转化为utf-8。
![]()
2.对代码的缩进,一些变量定义和空间进行了修改。
0x02 代码完善与实现
#Author:c1e4r # -*- coding: UTF-8 -*- import sys,os import getopt #读取指定文件中的字符数 def read_str(output_file,file_name=""): if not file_name: file = sys.argv[-1] else: file = file_name file1 = open(file,'r+',encoding='UTF-8') count = 0 for line in file1.readlines(): count_line = len(line) count += count_line f = open(output_file,'a+') print("[+]"+file+",字符数:"+str(count)) f.write(file+",字符数:"+str(count)+'\n') file1.close() f.close() #读取指定文件中的单词数 def read_word(output_file,file_name=""): if not file_name: file = sys.argv[-1] else: file = file_name file1 = open(file,'r+',encoding='UTF-8') count = 0 for line in file1.readlines(): line = line.replace(","," ") line = line.replace("."," ") line = line.replace("!"," ") line = line.replace("?"," ") line_word = len(line.split( )) count += line_word f = open(output_file,'a+') f.write(file+",单词数:"+str(count)+'\n') print("[+]"+file+",单词数:"+str(count)) file1.close() f.close() #读取指定文件中的行数 def read_line(output_file,file_name=""): if not file_name: file = sys.argv[-1] else: file = file_name file1 = open(file,'r+',encoding='UTF-8') count = 0 for line in file1.readlines(): count += 1 f = open(output_file,'a+') f.write(file+",行数:"+str(count)+'\n') print("[+]"+file+",行数:"+str(count)) file1.close() f.close() #读取目录下符合条件的文件 def read_file(output_file): file_name = sys.argv[-1] file_extension = file_name.split(".")[-1] #file1 = open(file,'r+',encoding='UTF-8') basedir = os.getcwd() pathDir = os.listdir(basedir) for file in pathDir: if file.split('.')[-1] == file_extension: print(file) #获取符合条件的名字 read_word(output_file,file) read_str(output_file,file) read_line(output_file,file) read_data(output_file,file) #read_word_top(output_file,stopList) #返回注释行,代码行,空行数量 def read_data(output_file,file_name=""): if not file_name: file = sys.argv[-1] else: file = file_name file1 = open(file,'r+',encoding='UTF-8') CodeLines = 0 # 代码行数 PoundLines = 0 # 注释行数 Temp = 0 # 空行数 for line in file1.readlines(): type(line) if not line.split(): #判断是否为空行 Temp += 1 elif line.startswith('#') or line.startswith('//') or line.startswith('/*') or line.endswith('*/'): # 判断是否为注释行 PoundLines +=1 else: #代码行 CodeLines +=1 f = open(output_file,'a+') f.write(file+",代码行:"+str(CodeLines)+'\n') print("[+]"+file+",代码行:"+str(CodeLines)) f.write(file+",注释行"+str(PoundLines)+'\n') print("[+]"+file+",注释行"+str(PoundLines)) f.write(file+",空行:"+str(Temp)+'\n') print("[+]"+file+",空行:"+str(Temp)) file1.close() f.close() #返回单词总数(停词表) def read_word_top(output_file,file_stop,file_name=""): if not file_name: file = sys.argv[-1] else: file = file_name file1 = open(file,'r+',encoding='utf-8') file_stop = open(file_stop,'r+',encoding='utf-8') stopList = [] WordCount = 0 #单词数 for line in file_stop.readlines(): for words in line.split(): stopList.append(words) file_stop.close() #print(stopList) for li in file1.readlines(): li = li.replace(","," ") li = li.replace("."," ") li = li.replace("!"," ") li = li.replace("?"," ") line_word = li.split( ) #print(line_word) for word in line_word: if word not in stopList: WordCount += 1 else: pass file1.close() f = open(output_file,'a+') print(WordCount) f.write(file+",单词总数(停词表):"+str(WordCount)+'\n') print("[+]"+file+",单词总数(停词表):"+str(WordCount)) f.close() def main(): try: opts, args = getopt.getopt(sys.argv[1:],"hcwlsae:o:") except getopt.GetoptError: print("test.py [parameter] [input_file_name]") sys.exit(2) finally: pass for o,a in opts: # -o 输出结果的文件 if "-o" in o: output_file = a else: output_file = "result.txt" for opt,arg in opts: if opt == '-h': print("wc.py -choose [input_file_name]") # -h 使用说明 print("-c 返回文件的字符数 -w 返回文件的单词总数") print("-l 返回文件的总行数 -s 递归处理目录下符合条件的文件") print("-a 返回注释行,代码行,空行数量 -e返回单词总数(stopList.txt为停词表) ") print("-o输出结果的文件 -h 获取帮助 ") sys.exit() elif opt == "-c": read_str(output_file) # -c 返回文件的字符数 #print(output_file) elif opt == "-w": read_word(output_file) # -w 返回文件的单词总数 elif opt == "-l": read_line(output_file) # -l 返回文件的总行数 elif opt == "-s": read_file(output_file) # -s 递归处理目录下符合条件的文件 elif opt == "-a": read_data(output_file) # -a 返回注释行,代码行,空行数量 elif opt == "-e": stopList = arg # -e 返回单词总数 read_word_top(output_file,stopList) print("[+]:The result is in "+output_file) # 输出结果的文件 if __name__ == "__main__": main()
0x03 单元测试
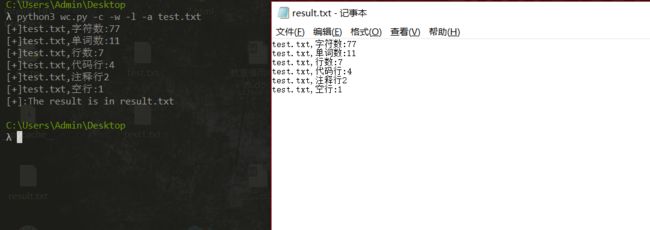

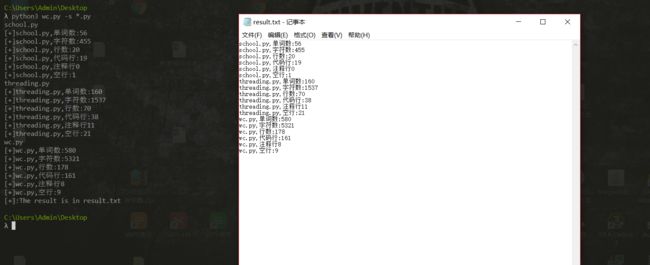
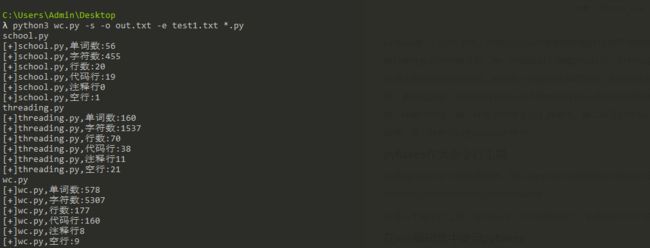
0x04 总结
通过本次的作业,体会到了在软件开发过程中必须保持严谨的态度,也要有一定的“大局观念”,才能在方便在软件测试时对软件的功能进行细化的测试。同时合作也是至关重要的一环,两个人相互之间的思考方式不同,逻辑思维也不同,这样审查代码也能发现一些代码上的逻辑错误,减少BUG的存在。其次代码的规范和风格极其重要,良好的编码习惯不仅会大大地提升整个程序源码的可读性,同时也会减少后期维护的成本,所以要在平时的练习中养成良好的编码习惯。