seaweedfs 部署使用
seaweedfs是一个非常优秀的由 golang 开发的分布式存储开源项目。它是用来存储文件的系统
seaweedfs的特点:
1 可以成存储上亿的文件(根据你硬盘大小变化)
2 速度快
weed-fs自身可以在两种模式下运行,一种是Master,另外一种则是Volume。集群的维护以及强一致性的保证由master们保 证,master间通过raft协议实现强一致性。Volume是实际管理和存储数据的运行实例。数据的可靠性则可以通过weed-fs提供的 replication机制保证。
master可以有一个或多个,master 存储映射关系,文件和fid的映射关系 weed master
Node 系统抽象的结点,抽象为datacenter、rack、datanode
datacenter 数据中心,包含多个rack,类似一个机房
rack :属于一个datacenter,类似机房中的一个机架
datanode : 存储节点,存储多个volume,类似机架中的一个机器 weed volume
volume :逻辑卷,存储needle
needle: 逻辑卷中的object,对应存储的文件
collection:文件集,默认所有文件都属于""文件集。如果想给某些文件单独分类,可以在申请id的时候指定相同的文件集
filer :指向一个或多个master的file服务器,多个使用逗号隔开。 weed filer
weed volume会创建一个 datanode ,可以指定所属的 datacenter rack和master ,会根据配置存储文件,默认一开始没有volume,当开始存储文件的时候才会创建一个volume,当这一个volume大小超过了volumeSizeLimitMB 就会新增一个volume,当volume个数超过了max则该datanode就不能新增数据了。那就需要在通过weed volume命令新增一个datanode。
和master一样,volume本身就是靠master管理的,volume server之间没有什么联系,增加一个volume server要做的就是启动一个新的volume server就好了,新volume server节点启动后,同样会自动加入集群,后续master就会自动在其上存储数据了。
volume个数和最大存储
默认最大7个,你可以设置100等等。。。
volume的备份机制 Replication
默认000 不备份
defaultReplication
000 不备份, 只有一份数据
001 在相同的rackj里备份一份数据
010 在相同数据中心内不同的rack间备份一份数据
100 在不同的数据中心备份一份数据
200 在两个不同的数据中心各复制2次
110 在不同的rack备份一份数据, 在不同的数据中心备份一次
如果数据备份类型是 xyz形式
各自的意义
x 在别的数据中心备份的份数
y 不相同数据中心不同的racks备份的份数
z 在别的服务器相同的rack的备份份数
filer的使用
直接往weed filer中拷贝目录或者文件(-include是文件模式通配符前使用??)
weed filer.copy nginxdir http://localhost:8888/aaa 把nginxdir拷贝到aaa目录下
weed filer.copy -include *.go . http://localhost:8888/github/
开始部署:centos7,安装go语言
yum -y install epel*
yum -y install golang
下载seeweedfs
wget https://github.com/chrislusf/seaweedfs/releases/download/0.76/linux_amd64.tar.gz
tar -C /usr/local/ -xzf linux_amd64.tar.gz
进入解压目录,以守护进程启动seaweedfs的主服务及集群(在启动前,先要创建相应的目录,/data/fileData,/data/t_v1,/data/t_v2,/data/t_v3)
mkdir -p /data/fileData
mkdir /data/t_v1
mkdir /data/t_v2
mkdir /data/t_v3
启动master:
cd /usr/local
nohup ./weed master -mdir=/data/fileData -port=9333 -defaultReplication="001" -ip="10.24.45.14" >>/data/fileData/server_sfs.log &
挂载卷volume
./weed volume -dir=/data/t_v1 -max=5 -mserver="10.24.45.14:9333" -port=9080 -ip="10.24.45.14" >>/data/t_v1_sfs.log &
./weed volume -dir=/data/t_v2 -max=5 -mserver="10.24.45.14:9333" -port=9081 -ip="10.24.45.14" >>/data/t_v2_sfs.log &
./weed volume -dir=/data/t_v3 -max=5 -mserver="10.24.45.14:9333" -port=9082 -ip="10.24.45.14" >>/data/t_v3_sfs.log &
1、-mdir和-dir表示该DataNode数据存储的目录;
2、-max表示volume个数最大值;
3、-mserver表示Master地址;
4、-port该DataNode监听的端口;
#将上面的ip地址换为具体的ip即可,默认可设为10.24.45.14。volume多少可以根据自己的情况添加。
#一个 MasterServer 对应三个 VolumeServer ,设置复制模式为 “001” , 也就是在相同 Rack 下复制副本为一份,也就是总共有两份
查看主服务和volume端口:

浏览器访问:http://ip:9333
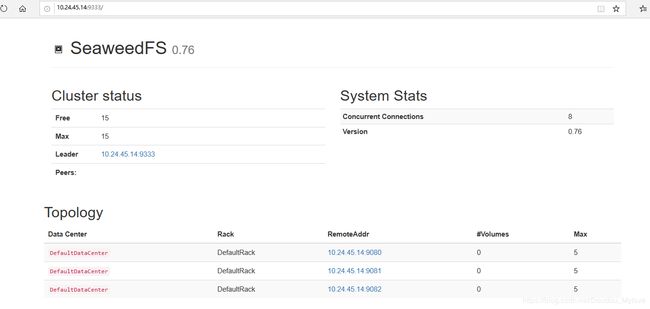
使用接口
申请一个fid
(1)获取fid,使用GET或POST访问路径http://10.24.45.14:9333/dir/assign获取fid和上传文件地址,如下:
curl -X POST http://10.24.45.14:9333/dir/assign
seaweedfs会返回json的结果:
{"fid":"1,08e684f060","url":"10.24.45.14:9080","publicUrl":"10.24.45.14:9080","count":1}
#fid就是上传的标志
使用url或者publicUrl加上fid,就是文件上传的地址。如下:
#http://localhost:9080/1,08e684f060
接着就可以发起一个PUT或POST请求到上面的地址,把文件上传上去。
curl -X PUT -F file=@/root/t017dd6c89c1d818a2d.jpg http://10.24.45.14:9080/1,02977c9e1b
结果如下:
{
"name": " t017dd6c89c1d818a2d.jpg ",
"size": 64300
}(2)如果要更新一个文件,直接发起POST或者PUT请求到url+fid的地址即可。fid就是保存图片使用的fid。
(3)删除图片发起一个DELETE请求即可。
curl -X DELETE http://10.24.45.14:8080/1,08e684f060
(4)查看文件,需要fid。就是刚刚上传图片得到的fid。可以将其保存在数据库当中,查找文件时再调用。
当有多个Volume集群时,可以通过参数指定查看某个卷。
curl http://10.24.45.14:9333/dir/lookup?volumeId=2
得到具体的地址:
{"volumeId":"2","locations":[{"url":"10.24.45.14:9081","publicUrl":"10.24.45.14:9081"}]}
然后访问具体的路由:
#http:// 10.24.45.14:9081/fid
比如:http://10.24.45.14:9080/1,02977c9e1b

SeaweedFS命令集:
benchmark
backup
compact
filer
fix
server
master
filer
s3
upload
download
shell
version
volume
export
mount
查看数据目录:
