Multimodal Unsupervised Image-to-Image Translation 论文小结
本文是自己阅读完Multimodal Unsupervised Image-to-Image Translation后写的小结。因为自己理解不够,所以我选择保留原文中的一些英文单词而不是去翻译。
自己之前虽然做过一些风格转化的工作,但是一直感觉非常懵懂,里面的东西很多自己都不明白,毕竟自己没有太多的理论知识,也不清楚很多模型的具体作用和限制。这篇论文里面有挺多理论上的分析,以及对很多模型作用的阐述。对我这样一个小白来说,有挺大的收获的。
一些实验的细节论文没有提及,需要看代码。
1. 简介
无监督下的图像到图像翻译在计算机视觉领域是一个重要且富有挑战性的问题。给一个source domain下的图片,图像翻译的目标是在看不到任何corresponding image pairs的前提下,学会该图片在target domain下对应图片条件的分布。当这个条件分布内部是multimodal时,现有的模型做出了过于简单的假设,认为图像到图像翻译是一个deterministic(唯一,必然,一成不变的)的one-to-one mapping。这导致了现有模型不能针对单一的输入图像生成不同的输出图像。为了解决这个问题,论文作者们提出了Multimodal Unsupervised Image-to-Image Translation(MUNIT)框架。作者假设图像的representation可以被分解成domain无关的内容信息(content code)和有着某个特定domain属性的风格信息(style code)。为了把一个图像翻译成另一个domain下的图像,MUNIT把图像的内容信息和从target domain中的风格空间中随机取样出的风格信息结合在一起。论文分析了这个框架并确定了理论上的结果。并通过与目前最先进的几个模型的实验结果对比,展示了模型的优点。而且MUNIT允许使用者通过提供style image的方式来控制图像翻译的风格。作者提供了代码和预训练好的模型:https://github.com/nvlabs/MUNIT
我对前面提到的multimodal的理解是多模态分布,即在一个空间下,多个分布共同存在的情况。举个例子,在猫科动物的照片空间中,有普通家猫的照片,也有有大型猫科动物的照片,这两种照片是不同的分布,但同时在一个空间(猫科动物照片)中同时存在,让猫科动物的照片分布形成了一个多峰(多模态)的分布。当然,自身的水平不高,可能理解上还是有很多偏差,而且照片的分布这种东西很难说清,只有在本论文的假设前提下,我们才可以讨论这些照片(或者图片)的分布。
2. 相关工作
3. MUNIT
3.1. 假设
目前还不是很能说明白文章的假设和解决问题间的具体联系(论文附录里的证明自己还没看过),就先随便写一些。
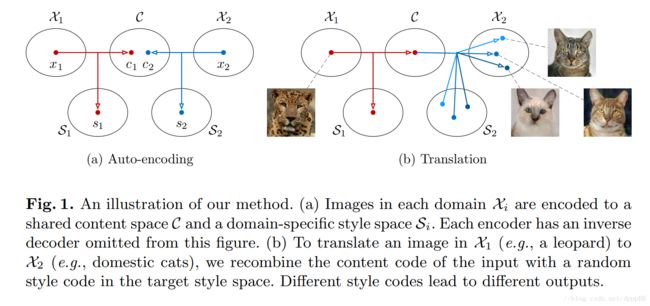
- 假设图像所在的 latent space 可以被分解为 content space 和 style space
- 假设不同domain直接共享 content space的内容,但 style space中的内容只被每个特定的domain独有。即两个对应的图片对 (x1,x2) 是这样被生成的: x1=G∗1(c,s1) , x2=G∗2(c,s2) ,其中 c,s1,s2 来自一些特定的分布, G∗1,G∗2 是underlying(潜在的,根本的) generators。
- 假设 G∗1 和 G∗2 是deterministic generators,并且它们有相对的encoders E∗1=(G∗1)−1 和 E∗2=(G∗2)−1 。论文作者的目标就是通过神经网络学习到对应的generator and encoder functions。值得注意的是虽然encoders and decoders是deterministic的,但是因为 s2 属于一个连续分布的关系,所以 p(x2|x1) 也是一个连续的分布。
- 假设内容编码(content code)是一个有着复杂分布特性的 high-dimensional spatial map,而风格编码(style code)是一个符合高斯分布特性的低维向量
3.2. 模型

MUNIT的loss function由用来保证编码器和解码器互逆的双向重构loss(bidirectional reconstruction loss)和使翻译得到的图像服从真实图像分布的对抗 loss(Adversarial loss即GAN loss)
Bidirectional reconstruction loss
因为编码器可以把图像分解成相应的编码,对应的编码又可以生成相应的图像,所以可以用两个L1 loss来保证编解码器的互逆性质,即可以通过 image→latent→image 这个过程得到前后两个image之间的L1 loss,以及通过 latent→image→latent 这个过程得到前后两个latent之间的L1 loss。公式见下图,不打出来了:

Adversarial loss
老生常谈GAN那一套 = =,直接贴公式把

Total loss

4. 理论分析
首先论文阐述了其Eq. (5)的一个特性,即当最小化完成时,翻译分布(translated distribution)和数据分布(data distribution)是相匹配的。此时Eq. (5)变成了一个最大化方程:

接下来讨论最小化过程带来的3个特性:
4.1. Latent Distribution Matching
如果一定要我用浅显的理解加上中文来翻译Latent Distribution Matching:隐编码分布匹配
现有的利用编码器和GAN来生成图像的模型要求利用kld loss和gan loss来使decoder接受到的latent distribution和encoded latent distribution匹配,不然的话,auto-encoder training 不会帮助GAN training。(感觉自己对原文中这段话的理解不是很好,貌似理解错了?)
即使MUNIT的loss function没有显性地强迫latent的分布,但依然可以隐式地影响这些分布。
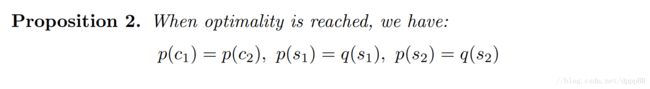
上述性质展示了在优化完成时,encoded style distributions 有了高斯分布的特性,同时,encoded content distribution和生成时的分布相匹配,注意生成时的content分布是来自其他domain的,这就表明了content space 是domain无关的。
4.2. Joint Distribution Matching
联合分布 p(x1,x1→2) 和 p(x2→1,x2) 本质上就是联合分布 p(x1,x2) ,这是图像翻译成功的关键。
![]()
4.3. Style-augmented Cycle Consistency
Cycle Consistency限制条件对多模态图像转换过强了,可以证明如果引入了这个限制,这个模型会从一个概率分布模型变为一个输入与输出永远对应的生成模型。

5. 实验
5.1. 推导细节
因为自己对这里面的很多模型还没有很好的理解,所以先写出模型的名字,具体说明就个人能力有限,不展开了。
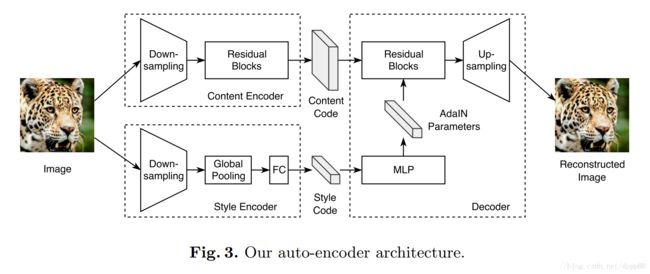
Content encoder所有的卷积层后面都跟着Instance Normalization层。
Style encoder因为Instance Normalization层会从原图的feature中移除风格信息,所以Style encoder中没有使用Instance Normalization层。
Decoder在每个Residual Blocks后面跟着Adaptive Instance Normalization (AdaIN)层,AdaIN层的参数由MLP计算出来。
Discriminator使用了LSGAN objective和multi-scale discriminators。
Domain-invariant perceptual loss域无关感知误差,在计算感知loss之前,对VGG的输出做Instance Normalization,意在去除特定领域下的信息,在大分辨率 (>=512∗512) 下这个方法可以加速收敛。不明白为什么有VGG的感知误差,在模型中没有说明啊。
5.2. Evaluation Metrics
5.3. Baselines
5.4. Datasets
5.5. 实验结果
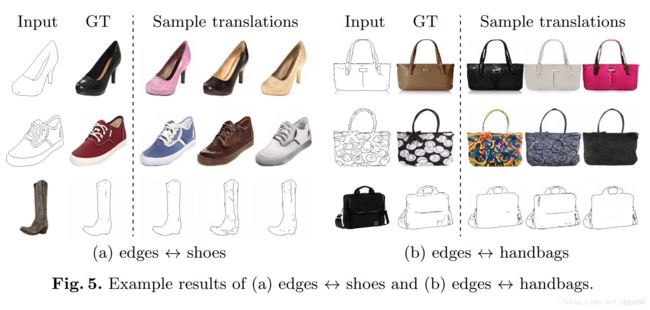
贴图……