1. 提升方法
提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能
0x1: 提升方法的基本思路
提升方法基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当(按照一定权重)的综合(例如线性组合加法模型)所得出的判断,要比其中任何一个专家单独的判断好
历史上,Kearns和Valiant首先提出了“强可学习(strongly learnable)”和“弱可学习(weekly learnable)”的概念,指出在概率近似正确(probably approximately correct,PAC)学习的框架中
1. 一个概念(概率规律)如果存在一个多项式的学习算法能够学习它(通过建模抽象拟合),并且正确率很高,那么就称这个概念是强可学习的; 2. 一个概念如果存在一个多项式的学习算法能够学习它,但是学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的
同时,后来Schapire证明强在PAC学习的框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题就转化为了,在算法训练建模中,如果已经发现了“弱可学习算法”(即当前分类效果并不优秀,甚至仅仅比随机预测效果要好),就有可能将其boosting(提升)为强可学习算法,这其中最具代表性的方法就是AdaBoosting(AdaBoosting algorithm)
提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(基本分类器),然后组合这些弱分类器,构成一个强分类器。大多数的提升方法都是改变训练数据的概率分布(训练数据的权重分布)
0x2:提升方法的两个关键要素
对于提升方法来说,有两个非常重要的问题
1. 在每一轮如何改变训练数据的权值或概率分布,修改的策略是什么? 2. 如何将弱分类器组合成一个强分类器?
这2个问题是所有Boosting方法都要考虑和解决的问题,这里以AdaBoost为例,讨论AdaBoost的策略
1. 提高那些被前一轮弱分类器错误分类的样本的权值,而降低那些被正确分类样本的权值。这样一来,那些被分错的数据,在下一轮就会得到更大的关注。所以,分类问题被一系列的弱分类器“分而治之” 2. 对弱分类器的组合,AdaBoost采取加权多数表决的方法。即加大分类误差率小的弱分类器的权值,使其在表决中起较大作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用
Relevant Link:
https://cseweb.ucsd.edu/~yfreund/papers/IntroToBoosting.pdf http://blog.csdn.net/dark_scope/article/details/14103983
2. 前向分步算法
在开始学习AdaBoost算法之前,我们需要先了解前向分步算法思想。实际上,AdaBoost算法是模型为加法模型、损失函数为指数函数、学习算法为前向分步算法时的二类分类学习算法
0x1:加法模型(aditive model)
加法模型是一种线性模型,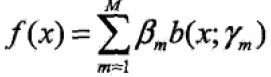 ,其中,
,其中,![]() 为基函数,
为基函数,![]() 为基函数的参数,
为基函数的参数,![]() 为基函数的系数(权重)
为基函数的系数(权重)
在给定训练数据及损失函数![]() 的条件下,学习加法模型
的条件下,学习加法模型![]() 成为经验风险极小化(即损失函数极小化)问题:
成为经验风险极小化(即损失函数极小化)问题: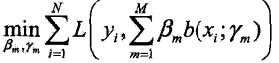
即同时考虑N个样本在整个线性模型组中的损失函数的极小值,通常这是一个十分复杂的优化问题(求极值问题),想要一步到位求出最优解特别困难。前向分步算法(forward stagewise algorithm)求解这一优化问题的思想是:
因为学习的是加法模型(线性模型),如果能够从前向后,每一步只学习一个基函数![]() 及其系数
及其系数![]() ,逐步逼近优化目标函数式,那么就可以极大简化优化的复杂度。
,逐步逼近优化目标函数式,那么就可以极大简化优化的复杂度。
具体地,每步只需要优化如下损失函数: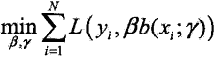 ,即一次只要考虑一个基函数及其系数即可
,即一次只要考虑一个基函数及其系数即可
有一点要注意,前向分步的思想和贝叶斯估计有类似的地方:
它们都假设每一步之间的基函数和系数是独立不相关的(在贝叶斯估计中这叫独立同分布),也因为这一假设才可以把原始的全局最优解求解等价为分步的子项求解过程。
但是这种假设会丢失一部分精确度,即每一步之间的依赖关联会被丢弃
而前向分步算法的思想就是不求一步到位,而是逐步逼近最优解,通过分步求得每一步的最优解来逼近全局最优解。我个人觉得这和SGD梯度下降的求最优思想是一样的
0x2:算法策略
和其他统计机器学习模型一样,前向分布算法的策略也同样是:经验风险最小化。如果在模型中加入了penalty惩罚项,则可以演进为结构风险最小化
0x3: 前向分步算法
给定训练数据集![]()
![]() ,损失函数
,损失函数![]() 和基函数的集合,学习加法模型
和基函数的集合,学习加法模型![]() 的前向分步算法如下
的前向分步算法如下
(1)初始化![]()
(2)对m = 1,2,3...,M(M代表基函数个数)
(a)在上一步得到的最优基函数的基础上,极小化本次单个基函数的损失函数: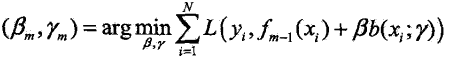 ,得到本轮最优基函数参数
,得到本轮最优基函数参数![]()
(b)更新(线性累加基函数)![]()
(3)得到最终加法模型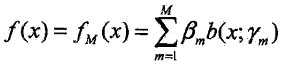
这样,前向分步算法将同时求解从m=1到M所有参数![]() 的全局最优解问题简化为逐次求解各个
的全局最优解问题简化为逐次求解各个![]() 的局部最优化问题
的局部最优化问题
Relevant Link:
https://en.wikipedia.org/wiki/Additive_model https://en.wikipedia.org/wiki/Generalized_additive_model http://www.stat.cmu.edu/~ryantibs/advmethods/notes/addmodels.pdf
3. AdaBoost算法
0x1:算法过程
假设给定一个二类分类的训练数据集(adaboost不限于二类分类)![]() ,其中,每个样本点由实例与标记组成。实例
,其中,每个样本点由实例与标记组成。实例![]() ,
,![]() 是实例空间,
是实例空间,![]() 是标记集合。AdaBoost利用以下算法,从训练数据集中学习一系列弱分类器或基本分类器,并将这些弱分类器线性组合成一个强分类器
是标记集合。AdaBoost利用以下算法,从训练数据集中学习一系列弱分类器或基本分类器,并将这些弱分类器线性组合成一个强分类器
- (1)初始化训练数据的权值分布(N代表样本数量):
 (初始等概率分布体现了最大熵原理,在没有任何先验知识的前提下作等概率假设是最合理的)。这一步假设数据集具有均匀的权值分布,即每个训练样本在基本分类器的学习中作用相同,这一假设保证第一步能够在原始数据上学习基本分类器
(初始等概率分布体现了最大熵原理,在没有任何先验知识的前提下作等概率假设是最合理的)。这一步假设数据集具有均匀的权值分布,即每个训练样本在基本分类器的学习中作用相同,这一假设保证第一步能够在原始数据上学习基本分类器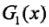
- (2)假设训练轮次为M(直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数),则对m = 1,2,....,M
(2.1)使用具有权值分布![]() 的训练数据集(对应本轮权值分布的数据集)学习,得到本轮次的基本分类器:
的训练数据集(对应本轮权值分布的数据集)学习,得到本轮次的基本分类器:![]()
(2.2)计算![]() 在本轮训练数据集上的分类误差率(权重误差函数):
在本轮训练数据集上的分类误差率(权重误差函数):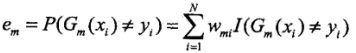 ,
,![]() 在加权的训练数据集上的分类误差率是被
在加权的训练数据集上的分类误差率是被![]() 误分类样本的权值之和,注意,权重误差函数关注的是本轮数据集的权重(概率)分布,而不关注弱分类器内部的参数。即我们对本轮高概率分布(重点关注的数据)的错误会给与更大的惩罚,这样就体现了模型Adding组合过程中根据权重误差进行模型组合选择的策略了
误分类样本的权值之和,注意,权重误差函数关注的是本轮数据集的权重(概率)分布,而不关注弱分类器内部的参数。即我们对本轮高概率分布(重点关注的数据)的错误会给与更大的惩罚,这样就体现了模型Adding组合过程中根据权重误差进行模型组合选择的策略了
(2.3)根据本轮的弱分类器对数据集的分类误差计算![]() 的模型系数:
的模型系数: ,代表了本轮得到的弱分类器的重要程度。由左式可知,当
,代表了本轮得到的弱分类器的重要程度。由左式可知,当![]() 时,
时,![]() ,并且
,并且![]() 随着
随着![]() 的减小而增大,所以在本轮分类误差率越小的基本分类器在最终分类器中的作用越大
的减小而增大,所以在本轮分类误差率越小的基本分类器在最终分类器中的作用越大
(2.4)更新下一轮训练数据集的权值分布: ,
,![]() 是规范化因子:
是规范化因子: ,它使得
,它使得![]() 成为一个概率分布(每一轮的权值总和都为1,
成为一个概率分布(每一轮的权值总和都为1,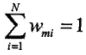 )。由此可知,被基本分类器
)。由此可知,被基本分类器![]() 误分类样本的权值得以扩大,而被正确分类样本的权值却在下一轮得以缩小。两相比较,误分类样本的权值被放大了
误分类样本的权值得以扩大,而被正确分类样本的权值却在下一轮得以缩小。两相比较,误分类样本的权值被放大了![]() 倍,因此误分类样本在下一轮学习中起更大作用。不改变所给的训练数据本身,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用,一次优化一个弱分类模型,或者理解理解为一次优化全局复杂问题中的一次子问题(分而治之)
倍,因此误分类样本在下一轮学习中起更大作用。不改变所给的训练数据本身,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用,一次优化一个弱分类模型,或者理解理解为一次优化全局复杂问题中的一次子问题(分而治之)
从数学的角度看,这也是一个平滑单调递增函数和 log 指数函数组合得到的动态增减平衡得到的神奇效果
- (3)构建基本分类器的线性组合:
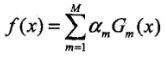 ,得到最终分类器:
,得到最终分类器: 。线性组合
。线性组合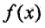 实现M个基本分类器的加权表决。系数
实现M个基本分类器的加权表决。系数 表示了基本分类器
表示了基本分类器 的重要性
的重要性
可以看到,在每轮的训练中,训练样本的权值分布不断在变动,同时 1. 权值分布对本轮的弱分类器在最终线性分类器组合中重要程度起正比例作用; 2. 对下一轮的样本权值调整起反比例作用
0x2:算法策略
毫无疑问是经验风险最小化策略
0x3:AdaBoost的一个例子
分析一下书上给的例子的计算过程,体会adaboost的思想

初始化训练数据的权值分布: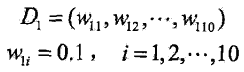 ,在第一轮输入原始数据本身
,在第一轮输入原始数据本身
1. 迭代过程 m = 1
要确定本轮的权重误差率,首先要"确定"出本轮的模型内部参数(但是最终误差损失的评估同时也受本轮数据集的权重分布影响,所以同一份数据每一轮的模型最优参数解都不一样),题目所给的模型是一个离散而分类模型,离散代表着模型的最优解是有一个区间的,最优解并不唯一(例如v取1.5和v取1.2都是等价的)。我们遍历【-0.5,0.5,1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5,10.5】比较模型误差率最小的模型内部参数,经过计算可得,对于m=1,在权值分布为D1(10个数据,每个数据的权值皆初始化为0.1)的训练数据上
- 阈值v取2.5时误差率为0.3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.3),
- 阈值v取5.5时误差率最低为0.4(x < 5.5时取1,x > 5.5时取-1,则3 4 5 6 7 8皆分错,误差率0.6大于0.5,不可取。故令x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.4),
- 阈值v取8.5时误差率为0.3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.3)。
- ...其他类推可自己计算
可以看到,无论阈值v取2.5,还是8.5,总得分错3个样本,故可任取其中任意一个如2.5,弄成第一个基本分类器为:

从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类样本“6 7 8”的权值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3
然后根据误差率e1计算G1的系数: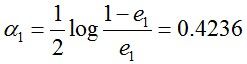
接着更新训练数据的权值分布,用于下一轮迭代: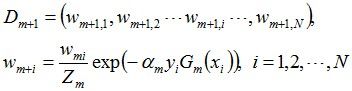
第一轮迭代后,最后得到各个数据新的权值分布D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。由此可以看出
1. 因为样本中是数据“6 7 8”被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666 2. 反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)
从上述第一轮的整个迭代过程可以看出:被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重,每轮被误分类的样本的调整幅度是一致的。
2. 迭代过程 m = 2
对于m=2,在权值分布为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1666*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1666*3),
- 阈值v取5.5时误差率最低为0.0715*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0715*3 + 0.0715),
- 阈值v取8.5时误差率为0.0715*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.0715*3)
所以,阈值v取8.5时误差率最低,故第二个基本分类器为: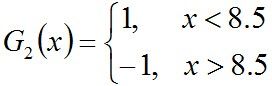
G2(x)把样本“3 4 5”分错了,根据D2可知它们的权值为0.0715, 0.0715, 0.0715,所以G2(x)在训练数据集上的误差率e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143。
计算G2的系数: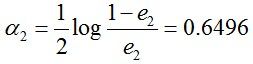
更新训练数据的权值分布:
D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小
f2(x)=0.4236G1(x) + 0.6496G2(x)
3. 迭代过程 m = 3
对于m=3,在权值分布为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1060*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1060*3),
- 阈值v取5.5时误差率最低为0.0455*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0455*3 + 0.0715),
- 阈值v取8.5时误差率为0.1667*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.1667*3)
所以阈值v取5.5时误差率最低,故第三个基本分类器为: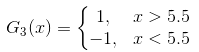
此时,被误分类的样本是:0 1 2 9,这4个样本所对应的权值皆为0.0455,所以G3(x)在训练数据集上的权重误差率e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820
计算G3的系数: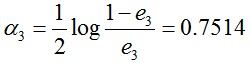
更新训练数据的权值分布:D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分错的样本“0 1 2 9”的权值变大,其它被分对的样本的权值变小
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
此时,得到的第三个基本分类器sign(f3(x))在训练数据集上有0个误分类点。至此,整个训练过程结束
从上述过程中可以发现:如果某些个样本被分错,它们在下一轮迭代中的权值将被增大(让模型倾向于在下一轮把这些样本点分对),同时,其它被分对的样本在下一轮迭代中的权值将被减小。就这样,分错样本权值增大,分对样本权值变小,而在下一轮迭代中,总是选取让误差率最低的阈值来设计基本分类器,所以每轮的误差率e(所有被Gm(x)误分类样本的权值之和)不断降低。看起来就是最终线性模型组合的总体误差率在每一轮的训练中不断降低
综上,将上面计算得到的a1、a2、a3各值代入G(x)中,G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ],得到最终的分类器为:
G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]
可以看到,每一轮迭代中阈值的选择是通过一个类似learning rate的学习率,可以理解为步长,去限制弱学习器的迭代次数
(scikitlearn的AdaBoostClassifier 中的learning_rate参数)
书中例子只有一个变量x,因此梯度为1可以忽略,可看成在原数据上学习率(步长)为0.5,去进行弱分类器的迭代,一次单变量的梯度下learning rate看起来和for循环遍历形式上是一样的
.... n_step = 0.5 features_min = min(features) features_max = max(features) # 步长 n_step = (features_max - features_min + self.learning_rate) // self.learning_rate for i in range(1, int(n_step)): v = features_min + self.learning_rate * i # 加入条件:阈值与数据点不重合 if v not in features: # 误分类计算 ....
0x4: 前向分布算法与AdaBoost的关系
在前面的章节中,我们讨论了加法模型(aditive model)与它的一个最优解近似求解算法前向分步算法。其实本质上说,AdaBoost还有另外一种解释,即可以认为:
AdaBoost是模型为加法模型、损失函数为指数函数、学习算法为前向分步算法的二类分类学习方法,AdaBoost算法就是前向分步算法的一个特例
AdaBoost中,各个基本分类器就相当于加法模型中的基函数,且其损失函数为指数函数
换句话说,当前向分步算法中的基函数为Adaboost中的基本分类器时,加法模型等价于Adaboost的最终分类器
Relevant Link:
http://blog.csdn.net/v_july_v/article/details/40718799 http://blog.csdn.net/dark_scope/article/details/14103983 https://www.zhihu.com/question/65357931 http://blog.csdn.net/v_july_v/article/details/40718799
4. 提升树(GBDT Gradient Boostring Decision Tree)
提升树是一种以分类树或回归树为基本分类器的提升方法
0x1: 提升树模型
提升树实际采用加法模型(基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树(boosting tree),对二分类问题决策树是二叉树,对回归问题决策树是二叉回归树。提升树模型可以表示为决策树的加法模型: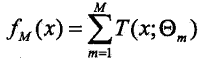 ,其中
,其中![]() 表示决策树;
表示决策树;![]() 表示决策树内部参数(选哪个特征作为切分点;阈值多少);M 为整个模型的个数
表示决策树内部参数(选哪个特征作为切分点;阈值多少);M 为整个模型的个数
0x2: 提升树算法
提升树算法采用前向分步算法,首先确定初始提升树![]() ,第m步的模型是:
,第m步的模型是:![]() ,其中
,其中![]() 为上一轮训练得到的单个基本分类器,通过经验风险极小化确定下一棵决策树的参数
为上一轮训练得到的单个基本分类器,通过经验风险极小化确定下一棵决策树的参数![]() ,
,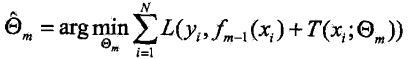
如果抽象来看,把每个基分类器的权重概率看作模型的参数,即每一轮的模型都接收上一步模型的参数作为输入,这一点很像深度神经网络的层一层之间的关系。
区别在于Boosting方法每轮得到的模型参数在输入下一轮迭代时是固定不变的,在每轮跌倒之间变动的只有:1)数据的概率权重;及2)模型的决策权重,而DNN会在每轮迭代中不断调整模型自身内部的所有神经元(对应基分类器)的内部参数。
打个不巧当的比喻:DNN坚信自己就是最棒的,不断提升自己。而Boostring认为众人拾柴火焰高,一个人不行我们就用祖父子->祖父子代代之间不断去优化,然后大家一起来参与决策
由于树的线性组合可以很好地拟合训练数据中存在的概率规则分布(可能是多峰的),即使数据中的输入与输出之间的关系很复杂也是如此,所以提升树是一个高效地学习算法。
下面讨论针对不同问题的提升树学习算法,其主要区别在于使用的损失函数不同:
1)用平方误差损失函数的回归问题:用平方误差求导更平滑可微; 2)用指数损失函数的分类问题; 3)用一般损失函数的一般决策问题;
1. 二分类问题提升树
对于二分类问题,提升树算法只需要将AdaBoost算法中的基本分类器(阶跃分类器)限制为二类分类树即可,可以说这时的提升树算法是AdaBoost算法的特殊情况
这里插一句:前面例子中看到的基本分类器 x < v 或 x > v,可以看作是由一个根节点直接连接的两个叶节点的简单决策树,即所谓的决策树桩(decision stump)
2. 回归问题的提升树
已知一个训练数据集![]() 为输入空间,
为输入空间,![]() 为输出空间。如果将输入空间
为输出空间。如果将输入空间![]() 划分为 J 个互不相交的区域 R1,R2,...,Rj,并且在每个区域上确定输出的常量Cj(连续区间的离散采样值),那么树可以表示为:
划分为 J 个互不相交的区域 R1,R2,...,Rj,并且在每个区域上确定输出的常量Cj(连续区间的离散采样值),那么树可以表示为: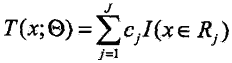 ,其中,参数
,其中,参数 ![]() 表示树的区域划分和各区域上的常数。J 是回归树的复杂度即叶节点个数(采样粒度)
表示树的区域划分和各区域上的常数。J 是回归树的复杂度即叶节点个数(采样粒度)
回归问题提升树使用以下前向分步算法:
在前向分步算法的第 m 步,给定当前模型 ![]() (上一轮训练得到的模型),需求解
(上一轮训练得到的模型),需求解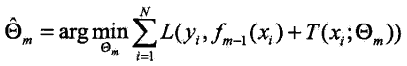 ,得到
,得到![]() ,即第 m 棵树的参数
,即第 m 棵树的参数
当采用平方误差损失函数时,![]() ,其损失变为:
,其损失变为:
这里,![]() 是当前模型拟合训练数据的残差(residual),所以,对回归问题的提升树算法来说,只需简单地拟合当前模型的残差即可。算法流程如下
是当前模型拟合训练数据的残差(residual),所以,对回归问题的提升树算法来说,只需简单地拟合当前模型的残差即可。算法流程如下
(1) 初始化![]()
(2)对 m = 1,2,...,M,M代表该加法模型总共有M个基本模型进行线性组合,在每一轮的训练中都进行如下步骤
(a)计算残差![]()
(b)拟合残差![]() (残差最小化)学习一个回归树,得到
(残差最小化)学习一个回归树,得到![]()
(c)更新![]()
(3)得到回归问题提升树: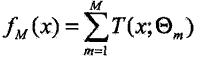
0x3: 提升树算法的一个例子
来一步步推导下书上的例子加深理解和印象

1. 第一次迭代 m = 1
对第一次迭代来说,提升树输入的是原始数据,残差等于原始样本输入
求![]() 即回归树
即回归树![]() 。首先通过以下优化问题:
。首先通过以下优化问题: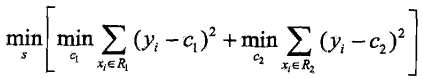 求解训练数据的切分点s:
求解训练数据的切分点s:![]()
容易求得在R1,R2内部使平方误差达到最小的C1,C2为: (离散采样点取子集的均值可以使得平方误差最小),这里N1,N2是R1,R2的样本个数
(离散采样点取子集的均值可以使得平方误差最小),这里N1,N2是R1,R2的样本个数
每一轮迭代训练中要计算的就是训练数据的切分点,这里可以采取遍历所有可能值的策略求得最优切分点s,s及m(s)的计算结果如下

可知当s = 6.5时m(s)达到最小值,此时![]() ,
,![]() ,所有回归树
,所有回归树![]() 为:
为: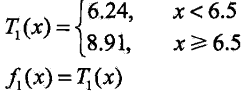
用![]() 拟合训练数据的残差用于输入下一轮迭代训练(从第二轮开始模型的输入就是残差了,这是GBDT区别于普通回归决策树的一个区别),
拟合训练数据的残差用于输入下一轮迭代训练(从第二轮开始模型的输入就是残差了,这是GBDT区别于普通回归决策树的一个区别),![]() 如下表所示
如下表所示

用![]() 拟合训练数据的平方损失误差:
拟合训练数据的平方损失误差: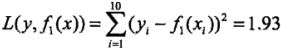
仔细看这个结果,我们会发现:从第二轮开始,输入下一轮的就不再是原始数据,而是数据的“离心距离”,即距离最佳分类面的距离。
2. 第二次迭代 m = 2
提升树和AdaBoost的核心思想是一样的,即:分而治之,每一轮迭代的“误报量”会被传递到下一轮,在下一轮的迭代中通过调整基本函数内部参数对那部分“误报量“进行重点解决
在AdaBoost中,上一轮误报的样本点会在下一轮按照一定的比例被提高权重,而在提升树中。这种思想通过残差得以体现,上一轮分类错误的残差被作为样本点传入进行模型训练,这一轮的目的就是尽力消弭这部分残差
这一轮的训练样本是上一轮的残差
通过遍历所有可能分界点s,可以得到: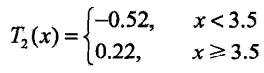 ,-0.52、0.22分别是左右分类子集的均值(满足平方误差最小)
,-0.52、0.22分别是左右分类子集的均值(满足平方误差最小)
至此,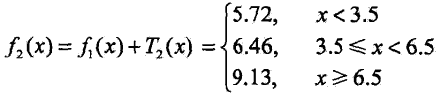 ,
,![]() 是
是![]() 和
和![]() 两个不等式线性相加的结果
两个不等式线性相加的结果
注意到这里和普通回归决策树的不同:GBDT每一轮得到的基分类器线性组合都同时包括此前的基分类器结果以及本轮的训练拟合结果,而普通回归决策树每轮迭代得到的区间基分类器都仅仅取决于原是样本
用![]() 拟合原始训练数据的平方损失误差是:
拟合原始训练数据的平方损失误差是: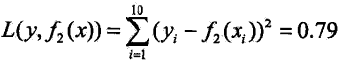 (比第一轮的损失函数在下降)
(比第一轮的损失函数在下降)
# -*- coding:utf-8 -*- import math def f2_fuc(x): if x < 3.5: return 5.72 elif x < 6.5: return 6.46 else: return 9.13 if __name__ == "__main__": loss = 0 train_data = { 1: 5.56, 2: 5.7, 3: 5.91, 4: 6.4, 5: 6.8, 6: 7.05, 7: 8.9, 8: 8.7, 9: 9.0, 10: 9.05 } for i in train_data: loss += (train_data[i] - f2_fuc(i)) ** 2 print loss
3. 继续往下迭代
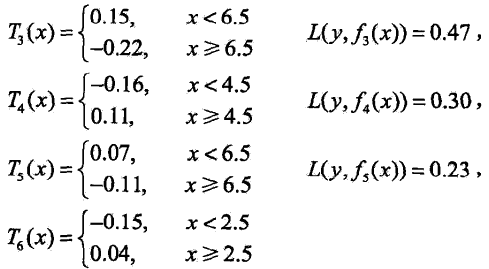
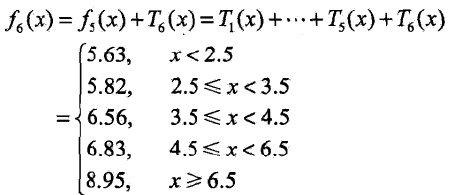
用![]() 拟合原始训练数据的平方损失误差是:
拟合原始训练数据的平方损失误差是: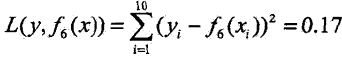
假设此时已经满足停止条件,则![]() 即为所求提升树(它的区间离散采样值是由多课决策树线性组合而成决定的)
即为所求提升树(它的区间离散采样值是由多课决策树线性组合而成决定的)
0x4: 更加general泛化的残差求解方式 - 梯度提升
提升树利用加法模型与前向分步算法实现学习的优化过程。当损失函数是平方损失和指数损失函数时,每一步优化是相对简单的(我们都可以通过求导得到最佳离散化采样值c1/c2),但对一般泛化的损失函数而言,往往每一步的优化并不容易(针对连续回归函数的复杂函数的拟合场景)。针对这一问题,Freidman提出了梯度提升(gradient boosting)算法,梯度提升的关键是利用损失函数的负梯度(负导数)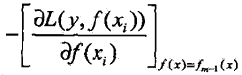 作为回归问题提升树算法中的残差的近似值(负梯度同样体现了该区间内样本数据和最佳分界面的“离心程度”),拟合一个回归树
作为回归问题提升树算法中的残差的近似值(负梯度同样体现了该区间内样本数据和最佳分界面的“离心程度”),拟合一个回归树
(1)初始化: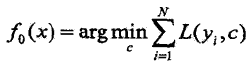
(2)对 m = 1,2,...,M,M代表该加法模型总共有M个基本模型进行线性组合,在每一轮的训练中都进行如下步骤
(a)对 i = 1,2,...,N(N个样本),计算: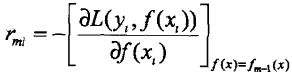 (计算损失函数的负梯度在当前模型的值,将它作为残差的估计,对于平方损失函数它就是残差;对于一般的损失函数,它就是残差的近似值)
(计算损失函数的负梯度在当前模型的值,将它作为残差的估计,对于平方损失函数它就是残差;对于一般的损失函数,它就是残差的近似值)
(b)对![]() 拟合一个回归树,得到第 m 棵树的叶节点区域
拟合一个回归树,得到第 m 棵树的叶节点区域![]() ,j = 1,2,...,J(叶节点不一定等于2)
,j = 1,2,...,J(叶节点不一定等于2)
(c)对 j = 1,2,...,J,计算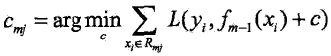 (利用线性搜索估计叶节点区域的值,寻找使得误差梯度最小的离散采样值c)
(利用线性搜索估计叶节点区域的值,寻找使得误差梯度最小的离散采样值c)
(d)更新 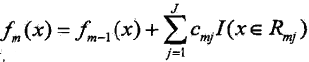 (每个基本函数由该棵树的所有叶节点的离散采样值组成)
(每个基本函数由该棵树的所有叶节点的离散采样值组成)
(3)得到回归树: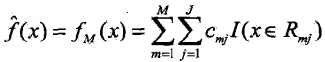
Relevant Link:
https://www.zhihu.com/question/60625492/answer/200165954 http://www.jianshu.com/p/005a4e6ac775
5. xgboost(Scalable and Flexible Gradient Boosting)
0x1:用一个图例说明XGboost模型
我们用一个简单的例子来引入对Xgboost的讨论,我们的目标是根据一些属性特性,判断一个家庭里的成员是否喜欢玩电脑游戏
1. 单个CART树的预测

可以看到,CART树和decision tree有一些不同,CART树的叶节点对应的是一个分值,而不像分类决策树是一个确定的类别,CART树的这个分值我们可以理解为权重
2. 两个CART树的线性加和组合
简单来说,xgboost对应的模型就是一堆CART树的线性组合,和GBDT一样,XGBoost将每棵树的预测值加到一起作为最终的预测值
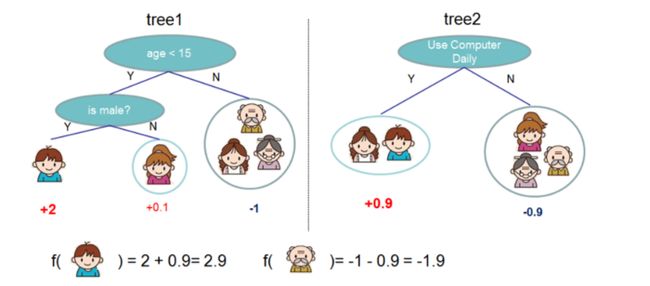
第二图的底部说明了如何用一堆CART树做预测,就是基于“addive model加法线性模型”的思想,将各个树的预测分数相加 。通过这种多基分类器加和(类似DNND中的多神经元)综合判断的方式,各个基模型互相补充,实现对多峰概率分布的拟合。这也体现了ensemble learning集成学习的思想。
0x2:XGBoost数学模型
我们用数学来准确地表示这个模型: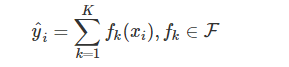
这里的K就是树的棵数,F表示所有可能的CART树,f表示一棵具体的CART树。这个模型由K棵CART树组成。
模型的目标函数如下: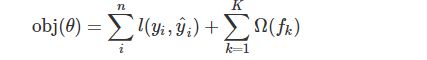
这个目标函数同样包含两部分
1. 第一部分就是损失函数:MSE或指数损失(例如交叉熵损失) 2. 第二部分就是正则项,这里的正则化项由K棵树的正则化项相加而来,体现了整体模型的复杂度
我们希望XGBoost得到的是一个: simple and predictive model
0x3:XGBoost模型训练策略 - 前向分步策略(逐轮加法训练)
几乎对于所有的有监督机器学习模型来说,训练过程就是找到一个目标函数,然后优化求导求极值。
但是XGBoost的模型:是由K棵树以及每棵树中的所有叶节点值组成的加法模型,要对其进行全局求导;或者是进行梯度下降都是很困难的,或者说在计算上非常复杂。
解决这个问题,我们可以使用“加法训练”,即我们一次只训练一棵树,同时把上一轮得到的所有ensemble tree结果作为本轮的输入:
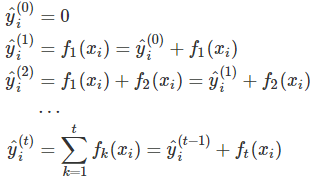
在第t步时,我们添加了一棵最优的CART树ft,这棵最优的CART树ft是怎么得来的呢?就是在现有的t-1棵树的基础上,使得目标函数最小的那棵CART树,如下图所示:
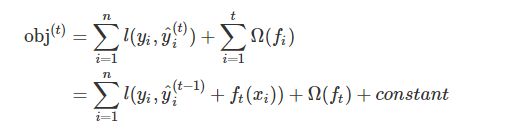
假如我们使用的损失函数时MSE,那么上述表达式会变成这个样子:
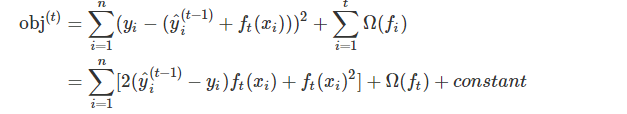
这个式子非常漂亮,因为它含有ft(xi)的一次式和二次式,而且一次式项的系数是残差。注意:这里模型的参数 ft(xi) 就是CART树叶子结点的值
但是对于其他的损失函数(指数损失和一般损失),我们未必能得出如此漂亮的式子,所以,对于一般的损失函数,我们需要将其作泰勒二阶展开,如下所示:
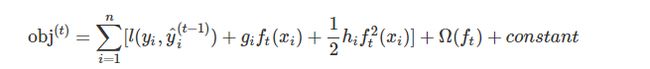
其中:
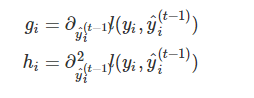
在这个公式中,constant代表的 t -1 棵树的正则化项;l(yi, yi^t-1)也是常数项;剩下的三个变量项分别是第t棵CART树的一次式,二次式;和整棵树的正则化项。
我们的目标在在这轮迭代中,让目标函数最小化,所以可以把常数项去掉,公式整理后如下:
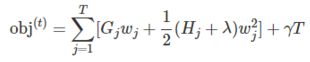
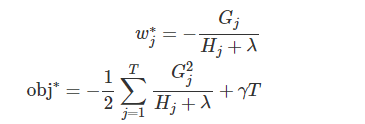

有了评判树的结构好坏的标准,我们就可以先求最佳的树结构,这个定出来后,最佳的叶子结点的值实际上在上面已经求出来了(模型的参数也就得到了)。
问题是:树的结构近乎无限多,一个一个去测算它们的好坏程度,然后再取最好的显然是不现实的。所以,我们仍然需要采取 “逐轮迭代渐进逼近全局最优策略”,我们 每次只优化一层的树结点,得到在这层里最优的树结构,即找到一个最优的切分点,使得切分后的Gain最大(和决策树的基尼指数求解最优分界面的思想是一致的)。我们以上文提到过的判断一个人是否喜欢计算机游戏为例子。最简单的树结构就是一个节点的树。我们可以算出这棵单节点的树的好坏程度obj*。假设我们现在想按照年龄将这棵单节点树进行分叉,我们需要知道:
1、按照年龄分是否有效,也就是是否减少了obj的值 2、如果可分,那么以哪个年龄值来分。
为了回答上面两个问题,我们可以将这一家五口人按照年龄做个排序。如下图所示:
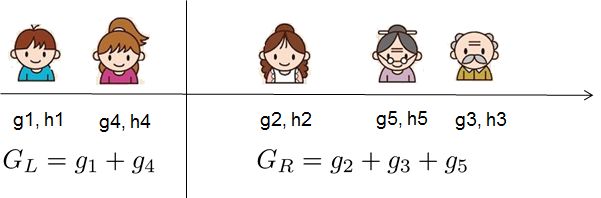
这个Gain实际上就是单节点的obj*减去切分后的两个节点的树obj*,Gain如果是正的,并且值越大,表示切分后obj*越小于单节点的obj*,就越值得切分。
同时,我们还可以观察到,Gain的左半部分如果小于右侧的![]() ,则Gain就是负的,表明切分后obj反而变大了。
,则Gain就是负的,表明切分后obj反而变大了。
![]() 在这里实际上是一个临界值,它的值越大,表示我们对切分后obj下降幅度要求越严。这个值也是可以在xgboost中设定的。这个
在这里实际上是一个临界值,它的值越大,表示我们对切分后obj下降幅度要求越严。这个值也是可以在xgboost中设定的。这个![]() 实际在本质上就起到了剪枝限制的作用,这也是XGboost和决策树的一个不同点:普通的决策树在切分的时候并不考虑树的复杂度,而依赖后续的剪枝操作来控制。xgboost在切分的时候就已经考虑了树的复杂度,就是那个
实际在本质上就起到了剪枝限制的作用,这也是XGboost和决策树的一个不同点:普通的决策树在切分的时候并不考虑树的复杂度,而依赖后续的剪枝操作来控制。xgboost在切分的时候就已经考虑了树的复杂度,就是那个![]() 参数。所以,它不需要进行单独的剪枝操作
参数。所以,它不需要进行单独的剪枝操作
0x4:XGboost的优点
从这个目标函数可以看出XGBoost的优点之处:
1. 目标函数中的一次式,二次式的系数是 gi 和 hi,而 gi 和 hi 是彼此独立的,可以并行的计算,这带来了计算速度上的并发优势
2. 而且,gi 和 hi是不依赖于损失函数的形式,只要这个损失函数是二次可微即可,所以 XGBoost可以自定义损失函数
Relevant Link:
https://www.jianshu.com/p/7467e616f227 https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf https://xgboost.readthedocs.io/en/latest/model.html https://www.cnblogs.com/csyuan/p/6537255.html http://blog.csdn.net/a819825294/article/details/51206410 http://blog.csdn.net/sb19931201/article/details/52557382 http://blog.csdn.net/github_38414650/article/details/76061893
Copyright (c) 2018 LittleHann All rights reserved