Flume+Kakfa+Spark Streaming整合(运行WordCount小例子)
环境版本:Scala 2.10.5; Spark 1.6.0; Kafka 0.10.0.1; Flume 1.6.0
Flume/Kafka的安装配置请看我之前的博客:
http://blog.csdn.net/dr_guo/article/details/52130812
http://blog.csdn.net/dr_guo/article/details/51050715
1.Flume 配置文件 kafka_sink.conf(监听文件1.log sink到kafka)
agent.sources = r1
agent.channels = c2
agent.sinks = k2
####define source begin
##define source-r1-exec
agent.sources.r1.channels = c2
agent.sources.r1.type = exec
agent.sources.r1.command = tail -F /home/drguo/flumetest/1.log
####define sink begin
##define sink-k2-kafka
agent.sinks.k2.channel = c2
agent.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k2.topic = test
agent.sinks.k2.brokerList = DXHY-YFEB-01:9092,DXHY-YFEB-02:9092,DXHY-YFEB-03:9092
agent.sinks.k2.requiredAcks = 1
agent.sinks.k2.batchSize = 20
#agent.sinks.k2.serializer.class = Kafka.serializer.StringEncoder
agent.sinks.k2.producer.type = async
#agent.sinks.k2.batchSize = 100
####define channel begin
##define channel-c2-memory
agent.channels.c2.type = memory
agent.channels.c2.capacity = 1000000
agent.channels.c2.transactionCapacity = 100
2.启动Flume
flume-ng agent --conf conf --conf-file ./kafka_sink.conf --name agent -Dflume.root.logger=INFO,console
3.运行Spark Streaming(word count)
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 单词统计 | Spark Streaming 接收并处理Kafka中数据
* Created by drguo on 2017/11/21.
*/
object KafkaWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(50))//方块长度
//ssc.checkpoint("checkpoint")
val topics = "test"
val numThreads = "2"
val zkQuorum = "DXHY-YFEB-01:2181,DXHY-YFEB-02:2181,DXHY-YFEB-03:2181"
val group = "TestConsumerGroup"
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
// Create a direct stream
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
/**
reduceByKeyAndWindow(_ + _, _ - _, Seconds(15), Seconds(10), 2)
总的来说SparkStreaming提供这个方法主要是出于效率考虑。
比如每10秒计算一下前15秒的内容,(每个batch 5秒),
那么就是通过如下步骤:
1.存储上一个window的reduce值
2.计算出上一个window的begin 时间到 重复段的开始时间的reduce 值 =》 oldRDD
3.重复时间段的值结束时间到当前window的结束时间的值 =》 newRDD
4.重复时间段的值等于上一个window的值减去oldRDD
这样就不需要去计算每个batch的值, 只需加加减减就能得到新的reduce出来的值。
*/
val wordCounts = words.map((_, 1)).reduceByKeyAndWindow(
(v1: Int, v2: Int) => {
v1 + v2
},
//十分钟 窗口长度
//Minutes(10),
//每五秒 窗口移动长度 统计十分钟内的数据
Seconds(50))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
4.插入测试数据
[root@DXHY-YFEB-03 flumetest]# echo "hadoop spark hello world world hh hh" >> 1.log
5.查看运行结果
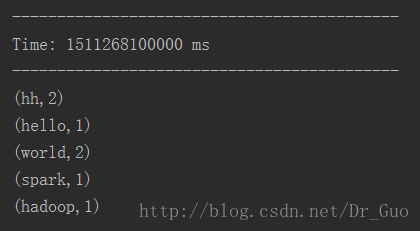
Flume简单的命令行操作
#创建topic
[root@DXHY-YFEB-01 KAFKA]# bin/kafka-topics --create --zookeeper DXHY-YFEB-01:2181,DXHY-YFEB-02:2181,DXHY-YFEB-03:2181 --replication-factor 3 -partitions 1 --topic test
#查看topic
[root@DXHY-YFEB-01 KAFKA]# bin/kafka-topics --list --zookeeper DXHY-YFEB-01:2181,DXHY-YFEB-02:2181,DXHY-YFEB-03:2181
#使用生产者向topic生产消息 可以有多个生产者
[root@DXHY-YFEB-01 KAFKA]# bin/kafka-console-producer --broker-list DXHY-YFEB-01:9092,DXHY-YFEB-02:9092,DXHY-YFEB-03:9092 --topic test
[root@DXHY-YFEB-02 KAFKA]# ~
[root@DXHY-YFEB-03 KAFKA]# ~
#使用消费者消费topic里的消息 可以有多个消费者
[root@DXHY-YFEB-01 KAFKA]# bin/kafka-console-consumer --zookeeper DXHY-YFEB-01:2181,DXHY-YFEB-02:2181,DXHY-YFEB-03:2181 --from-beginning --topic test
[root@DXHY-YFEB-02 KAFKA]# ~
[root@DXHY-YFEB-03 KAFKA]# ~
#查看消费者组
[root@DXHY-YFEB-01 KAFKA]# bin/kafka-consumer-groups --bootstrap-server DXHY-YFEB-01:9092,DXHY-YFEB-02:9092,DXHY-YFEB-03:9092 --list