【Keras之父】DL用于Text
用于处理序列的2种基本的深度学习算法分别是循环神经网络RNN (recurrent neural network) 和一维卷积神经网络(1D convnet)。这些算法的应用包括:
- 文档分类和时间序列分类,比如识别文章的主题或书的作者;
- 时间序列对比,比如估测两个文档或两支股票行情的相关程度;
- 序列到序列的学习,比如将英语翻译成法语;
- 情感分析,比如将推文或电影评论的情感划分为正面或负面;
- 时间序列预测,比如根据某地最近的天气数据来预测未来天气。
字符序列和单词序列是最常用的序列数据之一,但最常见的是单词级处理。深度学习用于NLP是将模式识别应用于单词、句子和段落。深度学习模型不会接收原始文本作为输入,只能处理数值张量。文本向量化vectorize就是将文本转换为数值张量的过程。常用方法如下:
- 将文本分割为单词,并将每个单词转换为一个向量。
- 将文本分割为字符,并将每个字符转换为一个向量。
- 提取单词或字符的 n-gram,并将每个 n-gram 转换为一个向量。n-gram 是多个连续单词或字符的集合(n-gram 之间可重叠)。
================================================================

词袋是一种不保存顺序的分词方法(生成的标记组成一个集合,而不是一个序列,舍弃了句子的总体结构),因此它往往被用于浅层的语言处理模型,而不是深度学习模型。提取 n-gram 是一种特征工程,深度学习不需要这种死板而又不稳定的方法,并将其替换为分层特征学习。在使用轻量级的浅层文本处理模型时(比如 logistic 回归和随机森林),n-gram 是一种功能强大、不可或缺的特征工程工具。
===============================================================
- 标记token --- 将文本分解而成的单元(单词、字符或n-gram)
- 分词tokenization ---- 将文本分解成标记的过程
===============================================================
所有文本向量化过程都是应用某种分词方案,然后将数值向量与生成的标记相关联。这些向量组合成序列张量,被输入到DNN中。将向量与标记相关联的方法有很多种。其中2种主要的方法:one-hot 编码( one-hot encoding)与标记嵌入(token embedding, 通常只用于单词,为词嵌入)。

1. one-hot编码
One-hot编码是将标记转换为向量的最常用、最基本的方法。定义:将每个单词与一个唯一的整数索引相关联,然后将这个整数索引i转换为长度N的二进制向量(N是词表大小),这个向量只有第i 个元素是1,其余元素都是0,得到的向量是二进制的、稀疏的(绝大部分元素都是0)、维度很高的(维度大小等于词表的单词个数)。同时也有对应的字符级的one-hot编码。Keras的内置函数可以对原始文本数据进行单词或字符级的one-hot编码。
One-hot编码的一种变体是所谓的one-hot散列技巧( one-hot hashing trick) ---将单词散列编码为固定长度的向量,通常用一个非常简单的散列函数来实现。如果词表中唯一标记的数量太大而无法直接处理,就可以使用这种技巧。
优点:避免了维护一个显式的单词索引,从而节省内存并允许数据的在线编码(即在读取完所有数据之前,就可以立刻生成标记向量)
缺点:散列冲突(hash collision)即2个不同的单词可能具有相同的散列值,随后任何机器学习模型观察这些散列值,都无法区分它们所对应的单词。如果散列空间的维度大于散列的唯一标记个数,散列冲突的可能性会减少。
2. 词嵌入word embedding
使用密集的词向量(word vector),低维的浮点数向量。常见的词向量维度是256、512或1024, 而One-hot编码的词向量通常是 >=20000 。

获取词嵌入有2种方法:
1. 在完成主任务(比如文档分类或情感预测)的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同,即利用Keras 中的embedding层来学习词嵌入。
词向量之间的几何关系应该表示这些词之间的语义关系。词嵌入的作用 应该是将人类的语言映射到几何空间中。在真实的词嵌入向量中,常见的有意义的几何变换的例子包括“性别”向量和“复数”向量。词嵌入空间通常具有几千个这种可解释的、并且可能很有用的向量。语言是特定文化和特定环境的反射。但是从更实际的角度来说,一个好的词嵌入空间在很大程度上取决于要解决的任务。

将一个 Embedding 层实例化时,它的权重(即标记向量的内部字典)最开始是随机的,与其他层一样。在训练过程中,利用反向传播来逐渐调节这些词向量,改变空间结构以便下游模型可以利用。一旦训练完成,嵌入空间将会展示大量结构,这种结构专门针对训练模型所要解决的问题。
2. 在不同于待解决问题的机器学习任务上预计算好词嵌入,然后将其加载到模型中---预训练词嵌入 (pretrained word embedding) 。在NLP中使用预训练的词嵌入,其原理与在Image Classification中使用预训练的CNN是一样的:没有足够的数据来学习真正强大的特征,但是又需要的特征应该是非常通用的,比如常见的视觉特征或语义特征。在这种情况下,重复使用在其他问题上学到的特征是很有道理的。This is举一反三。
常见的算法:1. word2vec算法---Google 13年用无监督的方法计算一个密集的低维词嵌入空间 ;2. GloVe---斯坦福大学 14年基本对词共现统计矩阵进行因式分解,数据来自于维基百科数据和Common Crawl数据。
================================================================
~~~~~~~~~~~~~~RNN系列~~~~~~~~~~~~~~
循环神经网络(RNN,recurrent neural network):它处理序列的方式是遍历所有序列元素并保存一个状态(state),其中包括与已查看内容相关的信息。实际上,RNN是一类具有内部环的神经网络。
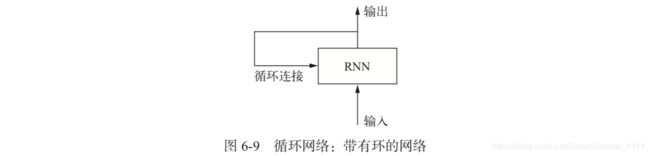

最终输出是一个形状为 (timesteps, output_features) 的二维张量,其中每个时间步是循环在 t 时刻的输出。输出张量中的每个时间步 t 包含输入序列中时间步 0~t 的信息,即关于全部过去的信息。网络的初始状态(initial state)是指 需要将状态初始化为一个全零向量。
Keras中的SimpleRNN层:SimpleRNN 层能够像其他 Keras 层一样处理序列批量,而不是 像 Numpy 示例那样只能处理单个序列。因此,它接收形状为 (batch_size, timesteps, input_features) 的输入,而不是 (timesteps, input_features)。与 Keras 中的所有循环层一样,SimpleRNN 可以在2种不同的模式下运行 ,由 return_sequences 这个构造函数参数来控制。如下:
1. 返回每 个时间步连续输出的完整序列,即形状为 (batch_size, timesteps, output_features) 的三维张量
2. 只返回每个输入序列的最终输出,即形状为 (batch_size, output_ features) 的二维张量。
【缺点】通常过于简化,没有实用价值。最大问题是: 在时刻 t,理论上来说,它应该能够记住许多时间步之前见过的信息,但实际上它是不可能学到这种长期依赖的。其原因在于梯度消失问题(vanishing gradient problem),这一效应类似于在层数较多的非循环网络(即前馈网络)中观察到的效应:随着层数的增加,网络最终变得无法训练。
———————————————————————————————————
下面介绍一下在Keras中其他的循环层应用:
===========================LSTM层和GRU层======================
LSTM (长短期记忆long short-term memory ): 允许过去的消息稍后重新进入,从而解决了梯度消失的问题。
LSTM层是SimpleRNN层的一种变体,它增加了一种携带信息跨越多个时间步的方法。假设有一条传送带,其运行方向平行于所处理的序列。序列中的信息可以在任意位置跳上传送带,然后被传送到更晚的时间步,并在需要时原封不动地跳回来。其原理为:保存信息以便后面使用,从而防止较早期的信号在处理过程中逐渐消失。
|

|

携带carry将与输入连接 和循环连接进行运算(通过一个密集变换,即与权重矩阵作点积,然后加上一个偏置,再应用 一个激活函数),从而影响传递到下一个时间步的状态(通过一个激活函数和一个乘法运算)。剖析LSTM流程如下:

RNN 单元的类型决定了假设空间,即在训练期 间搜索良好模型配置的空间,但它不能决定 RNN 单元的作用,那是由单元权重来决定的。同一 个单元具有不同的权重,可以实现完全不同的作用。因此,组成 RNN 单元的运算组合,最好被解释为对搜索的一组约束,而不是一种工程意义上的设计。
~~~~~~~~~为什么 LSTM 不 能表现得更好???~~~~~~~
一个原因是没有花力气来调节超参数,比如嵌入维度或 LSTM 输出维度。另 一个原因可能是缺少正则化。其实主要原因在于,适用于评论分析全局的长期性结构(这正是 LSTM 所擅长的),对情感分析问题帮助不大。对于这样的基本问题,观察每条评论中出现了哪些词及其出现频率就可以很好地解决。这也正是第一个全连接方法的做法。但还有更加困难的自然语言处理问题,特别是问答和机器翻译, LSTM 的优势就明显了。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*********提高循环神经网络的性能和泛化能力的三种高级技巧********
- 循环 dropout(recurrent dropout)。这是一种特殊的内置方法,在循环层中使用 dropout来降低过拟合。
- 堆叠循环层(stacking recurrent layers)。这会提高网络的表示能力(代价是更高的计算负荷)。
- 双向循环层(bidirectional recurrent layer)。将相同的信息以不同的方式呈现给循环网络,可以提高精度并缓解遗忘问题。
3种常见的解决序列文本问题的思路:
一、基于常识的、非机器学习的一种基准方法
一个经典的例子就是不平衡的分类任务,其中某些类别比其他类别更常见。比如:数据集中包含90%的类别A和10%的类别B,那么分类任务的一种基于常见的方法就是对新样本始终预测类别“A”。这种分类器的总体精度为 90%,因此任何基于学习的方法在精度高于 90% 时才能证明其有效性。有时候,这样基本的基准方法可能很难打败。
二、一种基本的机器学习方法
如果从数据到目标之间存在一个简单且表现良好的模型(即基于常识的基准 方法),那为什么训练的模型没有找到这个模型并进一步改进呢?
答:这个简单的解决方案并不是训练过程所要寻找的目标。在模型空间(即假设空间)中搜索解决方案,这个模型空间是具有我们所定义的架构的所有两层网络组成的空间,这些网络已经相当复杂。如果在一个复杂模型的空间中寻找解决方案,可能无法学到简单且性能良好的基准方法,虽然技术上来说它属于假设空间的一部分。通常来说,这对机器学习是一个非常重要的限制:如果学习算法没有被硬编码要求去寻找特定类型的简单模型,那么有时候参数学习是无法找到简单问题的简单解决方案的。
三、第一个循环网络基准
门控循环单元(GRU,gated recurrent unit)层的工作原理与 LSTM 相同。但它做了一些简化,因此运行的计算代价更低(虽然表示能力可能不如 LSTM)。ML中到处可以见到这种计算代价与表示能力之间的折中。
三种RNN 降低Overfitting技巧介绍:
1.循环dropout:
其做法为将某一层的输入单元随机设为0,其目的是打破该层训练数据中的偶然相关性。15年《Uncertainty in deep learning》论文确定在RNN中使用dropout正确方法:对每个时间步应该使用相同的dropout掩码(dropout mask,相同模式的舍弃单元),而不是让dropout掩码随着时间步的增加而随机变化。
为了对GRU、LSTM等循环层得到的表示做正则化,应该将不随时间变化的dropout掩码应用于层的内部循环激活(叫做循环dropout掩码)。对每个时间步使用相同的dropout掩码,可以让网络沿着时间正确的传播其学习误差,而随着时间随机变化的dropout掩码则会破坏这个误差信号,并且不利于学习过程。Keras 的每个循环层都有两个与 dropout 相关的参数: 一是 dropout,它是一个浮点数,指定该层输入单元的 dropout 比率; 二是 recurrent_dropout,指定循环单元的 dropout 比率。
2.循环层堆叠:
再次复习一下ML通用工作流程:增加网络容量通常是一个好主意,直到过拟合变成主要的障碍(假设已经采取基本步骤来降低过拟合,比如使用dropout)。只要过拟合不是太严重,很可能是容量不足的问题。
增加网络容量的通常做法是增加每层单元数或增加层数。循环层堆叠(recurrent layer stacking)是构建更加强大的循环网络的经典方法。例如谷歌翻译算法就是7个大型LSTM层的堆叠。在keras中逐个堆叠循环层,所有中间层都应该返回完整的输出序列(一个3D张亮),而不是只返回最后一个时间步的输出,通过指定return_sequences=True来实现。
3.使用双向/bidirectional RNN:
双向RNN是一种常见的RNN变体,它在某些任务上的性能比普通RNN更好,通常用于NLP。
RNN 特别依赖于顺序或时间,RNN 按顺序处理输入序列的时间步,而打乱时间步或反转时间步会完全改变 RNN 从序列中提取的表示。正是由于这个原因,如果顺序对问题很重要(比如温度预测问题),RNN 的表现会很好。双向 RNN 利用了 RNN 的顺序敏感性:它包含两个普通 RNN,比如 GRU 层和 LSTM 层,每个 RN 分别沿一个方向对输入序列进行处理(时间正序和时间逆序),然后将它们的表示合并在一起。通过沿这两个方向处理序列,双向 RNN 能够捕捉到可能被单向 RNN 忽略的模式,其工作原理如下:

GRU 层通常更善于记住最近的数据,而不是久远的数据, 与更早的数据点相比,更靠后的天气数据点对问题自然具有更高的预测能力(这也是基于常识的基准方法非常强大的原因)。在机器学习中,如果一种数据表示不同但有用,那么总是值得加以利用,这种表示与其他表示的差异越大越好,它们提供了查看数据的全新角度,抓住了数据中被其他方法忽略的内容,因此可以提高模型在某个任务上的性能。
双向 RNN 正是利用这个想法来提高正序 RNN 的性能。如果时间顺序对数据很重要,那么循环网络是一种很适合的方法,与那些先将时间数据展平的模型相比,其性能要更好。
+++++++面对市场时,过去的表现并不能很好地预测未来的收益+++++++++
~~~~~~~~~~用1D Convent 处理序列~~~~~~~~~~~
卷积神经网络(convnet)在计算机视觉上表现出色:原因 在于它能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效地利用数据。这些性质让卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特 别有效。时间可以被看作一个空间维度,就像二维图像的高度或宽度。一维卷积神经网络[与空洞卷积核(dilated kernel)一起使用]已经在音频生成和机器翻译领域取得了巨大成功。
二维卷积是从图像张量中提取二维图块并对每个图块应用相同的变 换;一维卷积可以识别序列中的局部模式,因为对每个序列段执行相同的输入变换,所以在句子中某个位置学到的模式稍后可以在其他位置被识别,这使得一维卷积神经网络具有平移不变性(对于时间平移而言)。

二维池化运算:二维平均池化和二维最大池化,在CNN用于对图像张量进行空间下采样。一维池化运算: 从输入中提取一维序列段(即子序列), 然后输出其最大值(最大池化)或平均值(平均池化)。与2D Convent一样,该运算也是用于降低一维输入的长度(子采样)。两者对比如下:
二维卷积池化:
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
一维卷积池化:
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
【两者不同】一维卷积神经网络可以使用更大的卷积窗口。对于二维卷积层, 3×3 的卷积窗口包含 3×3=9 个特征向量; 但对于一维卷积层,大小为 3 的卷积窗口只包含 3 个卷积向量。
在IMDB上评估1D Convent和LSTM,但是在CPU和GPU上的运行速度都要更快(速度取决于硬件设备配置)。在单词级的情感分类任务上,1D Convent可以替代循环网络,并且速度更快、计算代价 更低。
~~~~~~~~~~~用CNN + RNN处理长序列~~~~~~~~~~
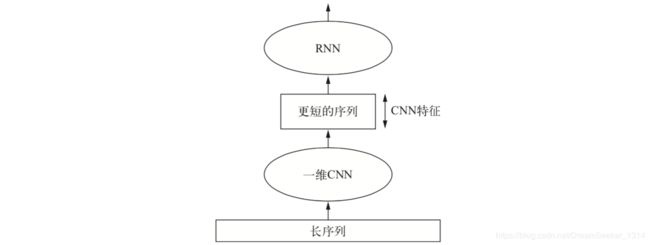
要想结合卷积神经网络的速度和轻量与 RNN 的顺序敏感性,一种方法是在 RNN 前面使用一维卷积神经网络作为预处理步骤。对于那些非常长,以至于 RNN 无法处理的序列 (比如包含上千个时间步的序列),这种方法尤其有用。CNN可以将长的输入序列转换为高级特征组成的更短序列(下采样)。然后提取的特征组成的这些序列成为网络中 RNN 的输入。
~~~~~~~~~~~~怎么选呢?~~~~~~~~~~~~~~~
如果序列数据的整体顺序很重要,那么最好使用循环网络来处理。时间序列通常都是最近的数据可能比久远的数据包含更多的信息量。可以用 RNN 进行时间序列回归(“预测未来”)、时间序列分类、时间序列异常检测和 序列标记(比如找出句子中的人名或日期)。
如果整体顺序没有意义,那么1D Convent可以实现同样好的效果,而且计算代价更小。文本数据通常都是这样,在句首发现关键词和在句尾发现关键词一样都很有意义。可用于机器翻译(序列到序列的卷积模型,比如 SliceNet)、文档分类和拼写校正。