大数据Spark “蘑菇云”行动补充内容第69课: Spark SQL案例之分析电影评分系统.
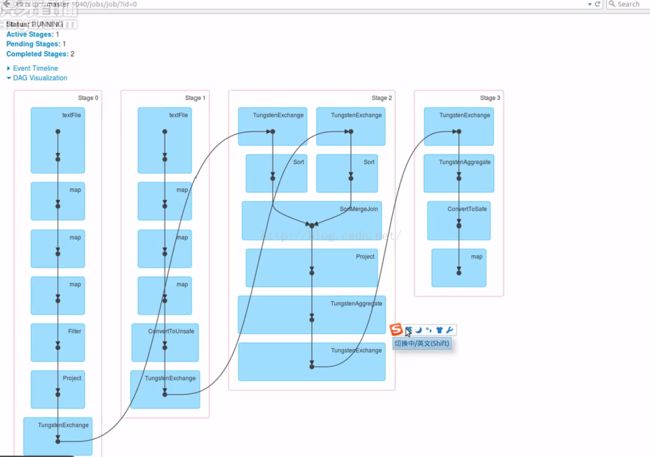 大数据Spark “蘑菇云”行动补充内容第69课: Spark SQL案例之分析电影评分系统.
大数据Spark “蘑菇云”行动补充内容第69课: Spark SQL案例之分析电影评分系统.
昨天的作业dataframe的 算子实现 :
import org.apache.spark.sql.Row
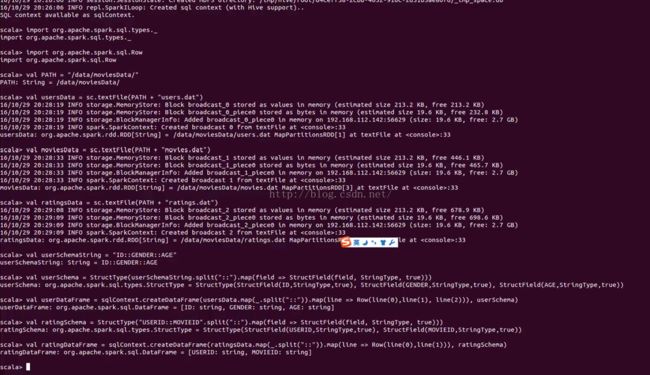
val PATH = "/data/moviesData/"
val moviesData = sc.textFile(PATH + "movies.dat")
val ratingsData = sc.textFile(PATH + "ratings.dat")
val usersData = sc.textFile(PATH + "users.dat")
val userSchemaString = "USERID::GENDER::AGE"
val userSchema = StructType(userSchemaString.split("::").map(field => StructField(field, StringType, true)))
val userDataFrame = sqlContext.createDataFrame(usersData.map(_.split("::")).map(line => Row(line(0),line(1), line(2))), userSchema)
val ratingSchema = StructType("USERID::MOVIEID".split("::").map(field => StructField(field, StringType, true)))
val ratingDataFrame = sqlContext.createDataFrame(ratingsData.map(_.split("::")).map(line => Row(line(0),line(1))), ratingSchema)
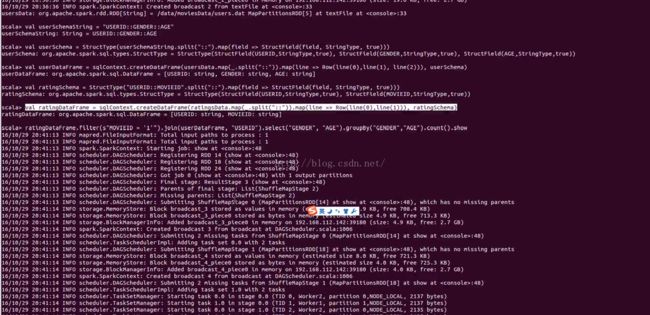
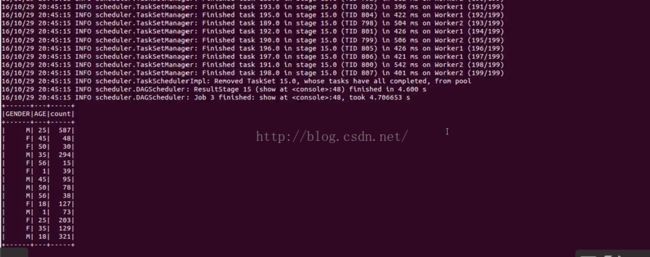
ratingDataFrame.filter(s"MOVIEID = '1'").join(userDataFrame, "USERID").select("GENDER", "AGE").groupBy("GENDER","AGE").count().show
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
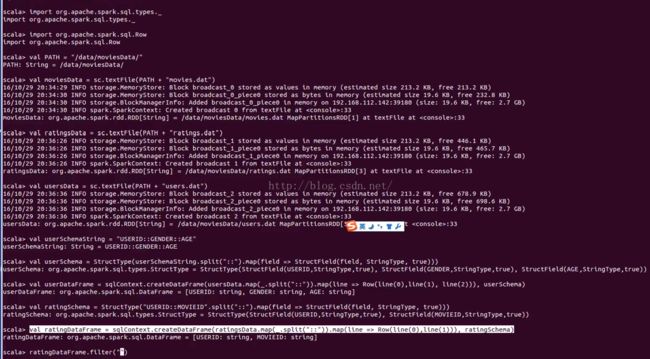
val PATH = "/data/moviesData/"
val moviesData = sc.textFile(PATH + "movies.dat")
val ratingsData = sc.textFile(PATH + "ratings.dat")
val usersData = sc.textFile(PATH + "users.dat")
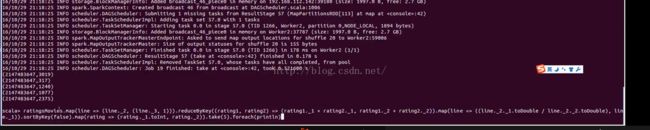
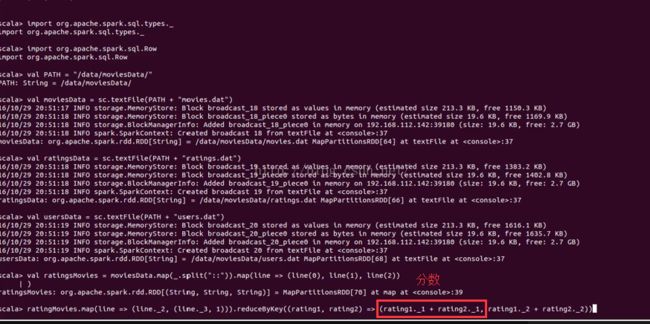
val ratingsMovies = ratingsData.map(_.split("::")).map(line => (line(0), line(1), line(2)))
ratingsMovies.map(line => (line._2, (line._3, 1))).reduceByKey((rating1, rating2) => (rating1._1 + rating2._1, rating1._2 + rating2._2)).map(line => ((line._2._1.toFloat / line._2._2.toFloat), line._1)).sortByKey(false).show
// 转换成为userId,movieId,rating 即 用户ID,电影ID,评分数
val ratingsMovies = ratingsData.map(_.split("::")).map(line => (line(0), line(1), line(2)))
//转换为电影ID,元组(评分数,计数为1)
ratingsMovies.map(line => (line._2, (line._3, 1)))
//按电影ID聚合计算,value是元组(评分数,计数为1),value的计算方式:评分相加累计,计数累加
即某部电影, 用户给它评分总分是多少,共评了多少次。
.reduceByKey((rating1, rating2) => (rating1._1 + rating2._1, rating1._2 + rating2._2))
//再次转换,分数的总分值 除以 总次数,就是某部电影的平均评分数,形成key value对,key是评分,value是某部电影ID
.map(line => ((line._2._1.toFloat / line._2._2.toFloat), line._1))
//按评分的分数排序 // take(5)请前五名,显示
.sortByKey(false).show
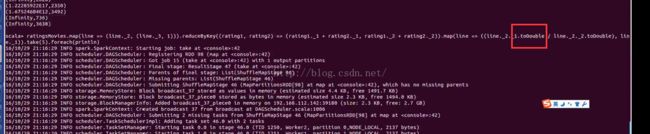
import org.apache.spark.sql.Row
val PATH = "/data/moviesData/"
val moviesData = sc.textFile(PATH + "movies.dat")
val ratingsData = sc.textFile(PATH + "ratings.dat")
val usersData = sc.textFile(PATH + "users.dat")
val ratingsMovies = ratingsData.map(_.split("::")).map(line => (line(0), line(1), line(2)))
ratingsMovies.map(line => (line._2, (line._3, 1))).reduceByKey((rating1, rating2) => (rating1._1 + rating2._1, rating1._2 + rating2._2)).map(line => ((line._2._1.toFloat / line._2._2.toFloat), line._1)).sortByKey(false).show
http://files.grouplens.org/datasets/movielens/ml-20m-README.html
Content and Use of Files
Formatting and Encoding
The dataset files are written as comma-separated values files with a single header row. Columns that contain commas (,) are escaped using double-quotes ("). These files are encoded as UTF-8. If accented characters in movie titles or tag values (e.g. Mis茅rables, Les (1995)) display incorrectly, make sure that any program reading the data, such as a text editor, terminal, or script, is configured for UTF-8.
User Ids
MovieLens users were selected at random for inclusion. Their ids have been anonymized. User ids are consistent between ratings.csv and tags.csv (i.e., the same id refers to the same user across the two files).
Movie Ids
Only movies with at least one rating or tag are included in the dataset. These movie ids are consistent with those used on the MovieLens web site (e.g., id 1corresponds to the URL https://movielens.org/movies/1). Movie ids are consistent between ratings.csv, tags.csv, movies.csv, and links.csv (i.e., the same id refers to the same movie across these four data files).
Ratings Data File Structure (ratings.csv)
All ratings are contained in the file ratings.csv. Each line of this file after the header row represents one rating of one movie by one user, and has the following format:
userId,movieId,rating,timestamp
The lines within this file are ordered first by userId, then, within user, by movieId.
Ratings are made on a 5-star scale, with half-star increments (0.5 stars - 5.0 stars).
Timestamps represent seconds since midnight Coordinated Universal Time (UTC) of January 1, 1970.
Tags Data File Structure (tags.csv)
All tags are contained in the file tags.csv. Each line of this file after the header row represents one tag applied to one movie by one user, and has the following format:
userId,movieId,tag,timestamp
The lines within this file are ordered first by userId, then, within user, by movieId.
Tags are user-generated metadata about movies. Each tag is typically a single word or short phrase. The meaning, value, and purpose of a particular tag is determined by each user.
Timestamps represent seconds since midnight Coordinated Universal Time (UTC) of January 1, 1970.
Movies Data File Structure (movies.csv)
Movie information is contained in the file movies.csv. Each line of this file after the header row represents one movie, and has the following format:
movieId,title,genres
Movie titles are entered manually or imported from https://www.themoviedb.org/, and include the year of release in parentheses. Errors and inconsistencies may exist in these titles.
Genres are a pipe-separated list, and are selected from the following:
- Action
- Adventure
- Animation
- Children's
- Comedy
- Crime
- Documentary
- Drama
- Fantasy
- Film-Noir
- Horror
- Musical
- Mystery
- Romance
- Sci-Fi
- Thriller
- War
- Western
- (no genres listed)
Links Data File Structure (links.csv)
Identifiers that can be used to link to other sources of movie data are contained in the file links.csv. Each line of this file after the header row represents one movie, and has the following format:
movieId,imdbId,tmdbId
movieId is an identifier for movies used by https://movielens.org. E.g., the movie Toy Story has the link https://movielens.org/movies/1.
imdbId is an identifier for movies used by http://www.imdb.com. E.g., the movie Toy Story has the link http://www.imdb.com/title/tt0114709/.
tmdbId is an identifier for movies used by https://www.themoviedb.org. E.g., the movie Toy Story has the link https://www.themoviedb.org/movie/862.
Use of the resources listed above is subject to the terms of each provider.
Cross-Validation
Prior versions of the MovieLens dataset included either pre-computed cross-folds or scripts to perform this computation. We no longer bundle either of these features with the dataset, since most modern toolkits provide this as a built-in feature. If you wish to learn about standard approaches to cross-fold computation in the context of recommender systems evaluation, see LensKit for tools, documentation, and open-source code examples.