第26课:电光石火间从根本上理解Spark中Sort-Based Shuffle产生的内幕及其tungsten-sort 背景解密
第26课:电光石火间从根本上理解Spark中Sort-Based Shuffle产生的内幕及其tungsten-sort 背景解密
Spark Sorted-Based Shuffle 的诞生
为什么 Spark 用 Sorted-Based Shuffle 而放弃了 Hash-Based Shuffle?在 Spark 里为什么最终是 Sorted-Based Shuffle 成为了核心,有基本了解过 Spark 的学习者都会知道,Spark会根据宽依赖把它一系列的算子划分成不同的 Stage,Stage 的内部会进行 Pipeline,Stage 与 Stage 之间进行 Shuffle,Shuffle 的过程包含三部份。
第一部份是 Shuffle 的 Write;第二部份是网络的传输;第三部份就是 Shuffle 的 Read,这三大部份设置了内存操作、磁盘IO、网络IO以及 JVM 的管理。而这些东西影响了 Spark 应用程序在 95%以上效率的唯一原因,假设你程序代码的质素本身是非常好的情况下,你性能的95%都消耗在 Shuffle 阶段的本地写磁盘文件,网络传输数据以及抓取数据这样的生命周期中。
在 Shuffle 写数据的时候,内存中有一个缓存区叫 Buffer,你可以想像成一个Map,同时在本地磁盘有相对应的本地文件。如果本地磁盘有文件你在内存中肯定也需要有相对应的管理句柄。也就是说,单是从 ShuffleWrite 内存占用的角度讲,已经有一部份内存空间是用在存储 Buffer 数据的,另一部份的内存空间是用来管理文件句柄的,回顾 HashShuffle 所产生小文件的个数是 Mapper 分片数量 x Reducer 分片数量 (MxR)。比如Mapper端有1万个数据分片,Reducer端也有1万个数据分片,在 HashShuffle 的机制下,它在本地内存空间中会产生 10000 * 10000 = 1,000,00000 个小文件(1 亿个),可想而知的结果会是什么,这么多的 IO,这么多的内存消耗、这么容易产生 OOM、以及这么沉重的 CG 负担。再说,如果Reducer端去读取 Mapper端的数据时,Mapper 端有这么多的小文件,要打开很多网络通道去读数据,打开 1,000,00000 端口(1 亿个)不是一件很轻松的事。这会导致一个非常经典的错误:Reducer 端也就是下一个 Stage 通过 Driver 去抓取上一个 Stage 属于它自己的数据的时候,说文件找不到。其实这个时候不是真的是磁盘上文件找不到,而是程序不响应,因为它在进行垃圾回收 (GC) 操作。
HashShuffle 经典问题 : Reducer 端也就是下一个 Stage 通过 Driver 去抓取上一个 Stage 属于它自己的数据的时候,说文件找不到。其实这个时候不是真的是磁盘上文件找不到,而是程序不响应,因为它在进行垃圾回收 (GC) 操作。HashShuffle:map端文件句柄消耗太多,导致GC时shuffle失败,shuffle从上一个stage抓取数据,默认是3次,每次5秒钟,如果15秒钟内抓不到数据就报错,要找的文件不存在。这个时候其实已经知道文件的位置了,shufflemaptask把数据写到本地的时候,将mapstatus告诉driver,数据放到了什么地方。但找driver的时候,正在GC,导致不响应。
因为 Spark 想完成一体化多样化的数据处理中心或者叫一统大数据领域的一个美梦,肯定不甘心于自己只是一个只能处理中小规模的数据计算平台,所以Spark最根本要优化和逼切要解决的问题是:减少 Mapper 端 ShuffleWriter 所产生的文件数量,这样便可以能让 Spark 从几百台集群的规模中瞬间变成可以支持几千台甚至几万台集群的规模。(一个Task背后可能是一个Core去运行、也可能是多个Core去运行,但默认情况下是用一个Core去运行一个Task)。
Spark shuffle改进的根本在于:减少map端产生的shuffle Writer文件的数量,这就是精髓之所在,所有的学习spark shuffle只能从这个角度出发才能够最直接的理解Spark shufffle不同版本的精髓并进行最大程度的性能调优!
减少Mapper端的小文件所带来的好处是:
Mapper端的内存占用变少了;
Spark可以处理不竟竟是小规模的数据,处理大规模的数据也不会很容易达到性能瓶颈;
Reducer端抓取数据的次数也变少了;
网络通道的句柄也变少;
极大了减少 Reducer 的内存不竟竟是因为数据级别的消耗,而且是框架时要运行的必须消耗。
Spark Sorted-Based Shuffle介绍
Sorted-Based Shuffle 的出现,最显著的优势就是把 Spark 从只能处理中小规模的数据平台,变成可以处理无限大规模的数据平台。可能你会问规模真是这么重要吗?当然有,集群规模意为著它处理数据的规模,也意为著它的运算能力。
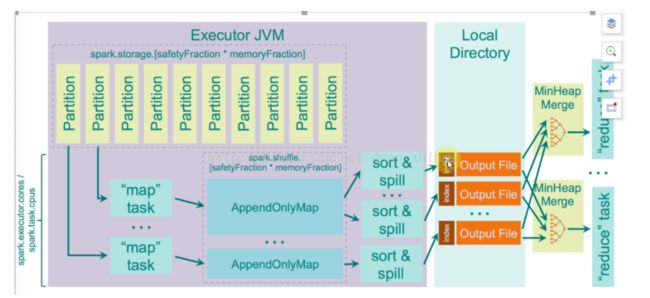
Sorted-Based Shuffle 不会为每个Reducer 中的Task 生产一个单独的文件,相反Sorted-Based Shuffle 会把Mapper 中每个ShuffleMapTask 所有的输出数据Data 只写到一个文件中,因为每个ShuffleMapTask 中的数据会被分类,所以Sort-based Shuffle 使用了index 文件存储具体ShuffleMapTask 输出数据在同一个Data 文件中是如何分类的信息。所以说基于 Sort-based Shuffle 会在 Mapper 中的每一个 ShuffleMapTask 中产生两个文件 (并发度的个数 x 2)!!!

它会产生一个 Data 文件和一个 Index 文件,其中 Data 文件是存储当前 Task 的 Shuffle 输出的, 而 Index 文件则存储了 Data 文件中的数据通过 Partitioner 的分类信息,此时下一个阶段的 Stage 中的 Task 就是根据这个 Index 文件获取自己所需要抓取的上一个 Stage 中 ShuffleMapTask 所产生的数据;
假设现在 Mapper 端有 10000 个数据分片,Reducer 端也有 10000 个数据分片,它的并发度是100,使用 Sorted-Based Shuffle 会产生多少个 Mapper端的小文件,答案是 100 x 2 = 200 个。它的 MapTask 会独自运行,每个 MapTask 在运行的时候写2个文件,运行成功后就不需要这个 MapTask 的文件句柄,无论是文件本身的句柄还是索引的句柄都不需要,所以如果它的并发度是 100 个 Core,每次运行 100 个任务的话,它最终只会占用 200 个文件句柄,这跟 HashShuffle 的机制不一样,HashShuffle 最差的情况是 Hashed 句柄存储在内存中的。
Sorted-Based Shuffle 主要是在Mapper阶段,这个跟Reducer端没有任何关系,在Mapper阶段它要进行排序,你可以认为是二次排序,它的原理是有2个Key进行排序,第一个是 PartitionId进行排序,第二个是就是本身数据的Key进行排序。看下图,它会把 PartitionId 分成3个,分别是索引为 0、1、2,这个在Mapper端进行排序的过程其实是让Reducer去抓取数据的时候变得更高效,比如说第一个Reducer,它会到Mappr端的索引为 0 的数据分片中抓取数据。
具体而言,Reducer 首先找 Driver 去获取父 Stage 中每个 ShuffleMapTask 输出的位置信息,跟据位置信息获取 Index 文件,解析 Index 文件,从解析的 Index 文件中获取 Data 文件中属于自己的那部份内容。
一个Mapper任务除了有一个数据文件以外,它也会有一个索引文件,Map Task 把数据写到文件磁盘是顺序根据自身的Key写进去的,也同时按照 Partition写进去的,因为它是顺序写数据,记录每个 Partition 的大小。
Sort-Based Shuffle 的弱点:
如果 Mapper 中 Task 的数量过大,依旧会产生很多小文件,此时在 Shuffle 传数据的过程中到 Reducer 端,Reducer 会需要同时大量的记录来进行反序例化,导致大量内存消耗和GC 的巨大负担,造成系统缓慢甚至崩溃!
强制了在 Mapper 端必顺要排序,这里的前提是本身数据根本不需要排序的话;
如果需要在分片内也进行排序的话,此时需要进行 Mapper 端和 Reducer 端的两次排序!
它要基于记录本身进行排序,这就是 Sort-Based Shuffle 最致命的性能消耗;
具体而言,Reducer 首先找 Driver 去获取父 Stage 中每个 ShuffleMapTask 输出的位置信息,跟据位置信息获取 Index 文件,解析 Index 文件,从解析的 Index 文件中获取 Data 文件中属于自己的那部份内容。
一个Mapper任务除了有一个数据文件以外,它也会有一个索引文件,Map Task 把数据写到文件磁盘是顺序根据自身的Key写进去的,也同时按照 Partition写进去的,因为它是顺序写数据,记录每个 Partition 的大小。
Sort-Based Shuffle 的弱点:
如果 Mapper 中 Task 的数量过大,依旧会产生很多小文件,此时在 Shuffle 传数据的过程中到 Reducer 端,Reducer 会需要同时大量的记录来进行反序例化,导致大量内存消耗和GC 的巨大负担,造成系统缓慢甚至崩溃!
强制了在 Mapper 端必顺要排序,这里的前提是本身数据根本不需要排序的话;
如果需要在分片内也进行排序的话,此时需要进行 Mapper 端和 Reducer 端的两次排序!
它要基于记录本身进行排序,这就是 Sort-Based Shuffle 最致命的性能消耗;
spark 2.0之后现在只有一种SortShuffleManager,废弃了HashShuffleManager;后期之秀tungsten-sort并入了SortShuffleManager(根据是否aggregate)。aggregate的情况不适用于tungsten-sort
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager",
"tungsten-sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")