RCNN系列之Faster RCNN详解
转载。 https://blog.csdn.net/u010725283/article/details/79020198
RCNN系列:RCNN,SPPNet,Fast RCNN,Faster RCNN,R-FCN。这一系列是个递进关系,也是目标检测使用two-stage方法的一个发展过程。想要更好的理解Faster RCNN和R-FCN,只能把这些算法都梳理清楚了,才能明白算法的整个优化过程。
本篇讲解的是Faster RCNN。2016年,发表在CVPR。
理解了SPPNet之后,我们知道了RCNN已经进化到了SPPNet阶段,那么,Fast RCNN又更进一步提高了速度。那么耗时最多的几乎都来自selective search了。
为了解决这个问题,Faster RCNN终于来了。
多说几句,起初我看论文的时候是从Faster RCNN开始看的,但是怎么都看不太明白,为什么要这样?为什么要那样?都不太清楚,将RCNN的一系列梳理了一遍之后,
才有些恍然大悟的一点感觉。
但是,基础还是不够扎实,有些理解还是会出现问题,之后随着理解的加深,慢慢再更新。
希望看到博客的读者,也能这样从头开始学RCNN,并不会浪费时间,反而会理解的更加深刻。
再看Fast RCNN过程:
- 使用selective search算法为每一张待检测的图片提取出2000左右的候选框,这一点和RCNN相同;
- 特征提取阶段,同样是提取出整张图片的feature map,然后将原图上的候选框映射到feature map上。然后对各个候选框对应的feature map上的块做ROI pooling,提取出固定长度的特征向量;
- 对于上一步的每一个ROI,网络输出每个类的概率和每个bounding box;
- 最后,使用NMS算法。
经过两次迭代优化,原始RCNN算法训练过程的三步走,现在只有两步,但是最终还是要使用selective search来做region proposal(候选框的生成)。
那么能不能使用CNN来做候选框的生成呐?
答案是可以!
由此,RPN(Region Proposal Network)被设计出来了。中文名就是区域生成网络。
Faster RCNN 可以看作是RPN 和 Fast RCNN的结合。
意味着我们把RPN理解透彻就能够很好的理解Faster RCNN了。
题外话:
这一段算是我的个人总结吧,在起初学习RPN的时候,很不明白,为什么RPN就能提取物体的候选框了,为什么要使用Anchor?
这些问题即使看了别人讲解RPN的博客也是一头雾水,根本不明白。
要理解这些问题,我们要学会用CNN做两件事情。
第一件:分类,这个问题是只要接触了CNN,我们就能基本知道怎么做,LeNet就是一个10分类,到了后来的AlexNet,VGG是1000分类。
如果这块还是不明白的话,只能好好推推CNN了。
第二件:回归,使用CNN做回归,我是开始没有搞明白。也就是怎么才能用CNN提取出来物体的bounding box呐?
bounding box 不就是学到目标的(x,y,h,w)四个参数吗?其中(x,y)是目标的在图片上面的中心坐标或者是左上角的坐标,h和w是目标框的长宽。
由于这四个参数都是连续的,所以是个回归问题。
为了弄明白这个道理,我们从最简单的开始,比如一张图中只有一个目标,且这一个目标只有三个种类比如是猫,狗,鼠。
我们只需要利用CNN计算出这一个目标的四个坐标参数和类别即可。
那么我们利用CNN需要得到什么信息呐?
首先需要一个参数p来确定这张图片是否含有目标,p=1代表有目标,p=0代表不含有目标。
如果图中存在目标,那么我们还要指定这个目标是三类中哪一个?
这时用SoftMax的方法一般是给出三个种类的概率即用c,d,m分别代表猫狗鼠在图中出现的概率。
然后存在目标后,我们还要标出目标的位置,也是上文所说的(x,y,h,w)。
那么我们需要CNN最后输出的结果即是:(p,c,d,m,x,y,h,w)维的向量即可。
更准确点就是让CNN的全连接层的最后输出是8维的向量,其中每一个输出单元代表了以上含义。
以上过程可以看作是CNN的前向传播过程,从输入一张图片,到输出这8维向量。
后向传播最主要的就是设计合理的loss函数,一般常用的loss函数可以按照以下:
loss=SoftMax(p,c,d,m)+s*L2((x,y,h,w)-GT)
以上,SoftMax就不用讲了,L2范数其实就是欧氏距离(两点距离),其中s是两者的权重。
这样有了loss函数,我们就可以使用后向传播来反复迭代了,直到收敛。
这样单目标的提取目标检测框的过程就完成了。
理解了CNN做这两件事的过程,我们再来理解RPN网络,就会变得轻松一些了。
在正式开始RPN之前,还是先熟悉一下RPN的基础网络VGG16:

上图中D网络就是VGG16,如果你不太理解上图的含义,请移步:http://blog.csdn.net/u010725283/article/details/78967498
我们可以看到,VGG16拥有13个conv,3个FC层。RPN用到的是conv3最后一层输出的feature map。
RPN网络:

有了以上基础后,我们再看Faster论文中的上图就很清晰了。
从下到上来看,
conv feature map是VGG16最后一层conv3的输出。
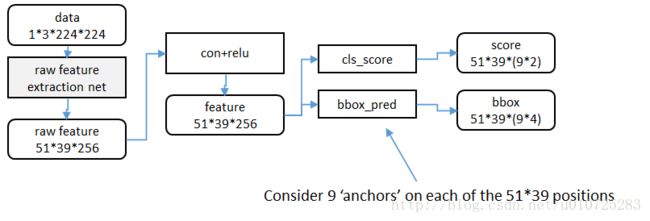
然后RPN在这个feature map上使用3*3的卷积核来进行卷积。
详细理解一下这个过程,在这里我们先不考虑 anchor的存在。假设feature map的大小的是40*60,那么使用3*3,pading=1,stride=1进行卷积后,输出依然是40*60。
那么针对这40*60个点,每一个点都输出一个6维的向量,如我们刚才理解的用CNN做回归的过程一样。那么最后输出的特征图应该是
40*60*6的feature map。
再换个思路理解就是,RPN将输入图片分成了40*60格子(要理解的是,这些格子的感受野在原图上是重叠的),每个格子都会输出一个用来分类和做回归的6维向量。
这样我们每个格子就会提出一个bounding box,一张图就可以提出2400个bounding box。这就代替了selective search 来做候选框的生成了。
那还为什么会有anchor呐?
其实这是由于一些问题出现了。
先考虑一种情况,
如果一个格子中出现了不止一个物体,而我们的RPN在格子中却只提出了一个bounding box,
那么带来的结果必定是漏检了,这个格子里面的目标只能找到一个或者都找不到。
再考虑另外一种情况,

比如上面这张图中,我们假设一个格子中既有人也有马,人是竖长的格子,马是横向比较长的格子,我们的框又该怎么找呐?
针对这些情况,作者提出了Anchor 的概念,就是在一个格子中,我们不仅仅提取一个box,我们提取出9个尺度,横纵比不同的box,
这样会在一个格子中存在9种不同的box,然后我们利用CNN来回归这些box。
怎么做回归呐?
RPN的前向传播过程:
在一个格子中,RPN会提取出来一个9*(2+4)的向量,其中2代表是否存在目标,4即是bounding box的四个坐标。
在前向过程中,RPN在一个格子中提取了9个框,以及每个框的置信度。
Anchor在这里起的作用,按照我的理解就是初始化上面提取的9个框。
这样每个格子的9个框就会有了初始的大小。
起初在这里我也有疑问,为什么要用Anchor初始化啊,不加上Anchor也是可以提取出来9个框的啊?
但是,CNN的训练过程我们是不可控的,虽然在一个格子中是可以提取到9个框,但是我们不能确定这9个框可能是回归到了同一个呐?
那就还是会出现马和人在一个格子中,我们可能只能找到一个目标。当然也可能可以找到两个。这些是不确定的。
但是,我们要增大我们能同时找到所有目标的概率。
这就是Anchor了。
其中按照一定的规则来抛弃一些box。规则可以参考以下:

再啰嗦一句,起初RPN提取的9个框和置信度的偏差肯定很大,所以需要后向传播的迭代优化。
RPN的后向传播过程:
CNN的后向传播最关键的就是要找到合适的loss,在有了合适的loss函数后,CNN就能迭代优化了。
RPN的loss函数:

其中具体字母代表的含义可以参考论文,只要明白了是分类和回归坐标的结合就可以了。
这样在每一张图片中就可以得到了40*60*9个bounding box,经过以上的分析,这些框是可以基本覆盖所有的ground truth。
以上,所有的分析基本回答了Anchor 是什么以及为什么使用Anchor。
再看RPN,这次就是横向对比了,去掉Anchor的RPN其实就是Fast RCNN的变形,
Fast RCNN:
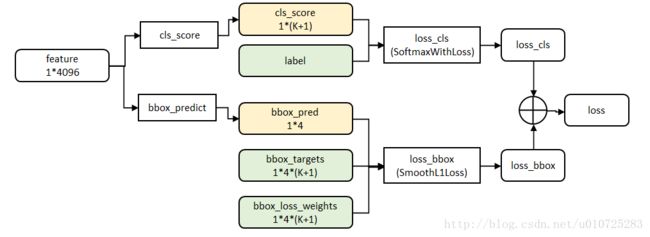
RPN:
唯一不同的就是使用的loss函数不同,网络结构基本可以看作是一样的。
有了以上对比,Faster RCNN使用的共享权值那就是水到渠成了。

训练方法参考下图:

实验结果并不是我太关注的事情,肯定是当时最好。
个人见解:大家都知道Faster RCNN很厉害,速度相当快了,RPN是Faster的核心,而Anchor又是RPN的核心。那么Anchor的思想是来源哪里呐?
还是作者独到见解?
我的猜测,这个思想来源是另一篇2014年的CVPR:
Scalable Object Detection using Deep Neural Networks
论文名字并不出名,但是提出的loss函数可是被Fast RCNN,Faster RCNN,yolo,SSD所使用。结构名字也叫DeepMultibox。
如果你没关注到这篇论文,可以看一下:http://blog.csdn.net/u010725283/article/details/78816916
这篇文章是这系列的目标检测的思想来源(我认为的)。很多内容被扩展后就成为了很牛的算法。
参考:
Faster R-CNN: Towards Real-Time Object Detection
with Region Proposal Networks
Faster RCNN详解:http://blog.csdn.net/shenxiaolu1984/article/details/51152614
deepmultibox:http://blog.csdn.net/u010725283/article/details/78816916
Faster RCNN详解:http://www.360doc.com/content/17/0303/14/10408243_633634497.shtml
vgg16:http://blog.csdn.net/u010725283/article/details/78967498