论文精读及分析:Fully Convolutional Networks for Semantic Segmentation
本文主要内容为论文《Fully Convolutional Networks for Semantic Segmentation》 的阅读笔记,在原始论文的基础上加入了自己的一些理解,内容和图片主要参考该论文。其中一部分的翻译参考了 “一生不可自决” 的博客《Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)》
1. 作者介绍
在论文中声明 Jonathan Long 和 Evan Shelhamer 为共同一作,随后是 Trevor Darrell 。
首先介绍 Jonathan Long,通过他的主页我们可以看到,2010年前它在卡耐基梅隆学习计算机、物理和数学,2010年后在 UC Berkeley 攻读计算视觉的博士,导师是 Trevor Darrell。目前就职于 Symbio Robotics ,是这家公司的研究员/工程师,它主要关注将感知输入解码为有用信息,利用机器学习算法操纵物理世界,为工业机器人带来现代感;同时他也是caffe的开发者之一。本篇论文是他的代表作,获得 CVPR 2015 年最佳论文荣誉奖。
其次是 Evan Shelhamer,通过他的主页可以看到,他毕业于麻省大学阿默斯特分校,获得计算机科学(人工智能集中)和心理学双学位,之后在 UC Berkeley 攻读博士学位。caffe 的开发者之一。
最后的 Trevor Darrell 是上面两个人的导师,应该是是传说中的大师级人物了,给出他的主页,大家可以自行去感受一下。没错这三个人是一个师傅和两个徒弟,而且都是 caffe 的开发者,对!就是这么牛~
2. 按论文章节回顾具体内容
Abstract
本文的关键在于建立一种可以接受任意大小图像并输出与输入等大的图像的全卷积神经网络。在这篇文章中,作者定义了全卷积神经网络 (FCN) 的空间结构、解释了 FCN 在空间密集型预测任务上的应用并且给出了他与之前其他网络之间的联系。在这里作者首先将一些分类用的网络 (如 VGG, Google Net等) 改写为 FCN 的形式,之后通过迁移学习的方法进行 finetune,以此来完成所需要的分割任务。然后作者还定义了跳跃结构,通过结合来自于深的、粗糙的层的语义信息和来自浅、细层的表征信息来产生准确和精细的分割。
1. Introduction
卷积网络在识别领域前进势头很猛。卷积网不仅全图式的分类上有所提高 [22,34,35] ,也在结构化输出的局部任务上取得了进步。包括在目标检测边界框 [32,12,19] 、部分和关键点预测 [42,26] 和局部通信 [26,10] 的进步。
在以往的分割方法中,主要有两大类缺点,首先基于图像块的分割常见,但是效率低,往往需要前期或者后期的处理(例如超像素、proposal(检测框) 和对通过随机域事后细化或者局部分类)。其次语义分割面临在语义和位置的内在张力问题:全局信息解决的“是什么”,而局部信息解决的是“在哪里”。
为了解决上面这两个问题,本文主要有三个创新点:
(1) 将分类网络结果重新解释为全卷积神经网络结构,这里面具体包括两点,一个是全连接层转化为卷积层,还有就是通过反卷积进行上采样。
(2) 使用迁移学习的方法进行 finetune ,因为很明显通过第一点可知可以将 VGG 这类有预训练权重的分类网络重新解释为 FCN
(3) 使用跳跃结构使得,使得深的粗的语义信息可以结合浅的细的表征信息,产生准确和精细的分割。
上面的 (1) (2) 主要解决第一个问题,(3) 主要解决第二个问题。
2. Related work
前几段主要介绍了全卷积神经网络和全卷积计算在各种任务中的应用。
以往的方法主要有以下的缺点:
(1) 限制容量和感受野的小模型;
(2) 分块训练;
(3) 超像素投影的预处理,随机场正则化、滤波或局部分类;
(4) 对于密集输出采用输入移位和输出交错的方法;
(5) 多尺度金字塔处理;
(6) 饱和双曲线正切非线性;
(7) 集成
基于 FCN 的方法没有以上缺点,但是我们从 FCN 的角度在 3.2 节中研究了 “shift-and-stitch(移动与缝合)”的密集输出问题,在 3.4 节中研究了基于块训练的问题。
传统的基于CNN的分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
3. Fully convolutional networks
介绍了卷积神经网络为什么叫卷积神经网络以及 loss 的计算。在接下来的 3.2 节介绍引出快速扫描 (fast scanning) 的技巧,3.3 节介绍用于上采样的去卷积层,在3.4节,我们考虑通过patchwise取样训练,便在4.3节证明我们的全图式训练更快且同样有效。
3.1. Adapting classifiers for dense prediction
说明了全连接层和卷积层在结构上实际上是等价的。通过比较发现,将一张图有重叠地分块输入和直接输入整张图像这两种方式相对比,可以发现后者的前向传播时间和反向传播时间均更短,论文中有讲述其中的道理,在我的另一篇博客《卷积神经网络入门详解》中的 2.4.1. 和 2.4.2. 部分有更为详细的解释。在实际操作中,每次全连接到卷积的变换都需要把全连接层的权重W重塑成卷积层的滤波器。
如下图所示,是将全连接层转化为卷积层的示意图
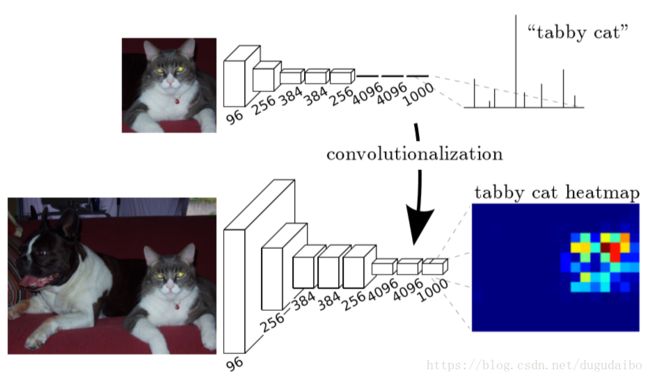
在上图中可以看到原始的带有全连接层的神经网络输出的对该图像的分类结果,上图中的第二行将更大尺寸的图像输入全卷积神经网络,会输出一个 ( H / 32 ) × ( W / 32 ) × 1000 (H/32)\times(W/32)\times1000 (H/32)×(W/32)×1000 的 featureMap,这个 featureMap 也就是 heatMap。
这部分虽然在一定程度上完成了创新点(1)的需求,但是实际上通过全卷积神经网络输出的结果大小与原始图像相比小了很多,所以这个时候需要解决 “下采样” 引出的问题。
3.2. Shift-and-stitch is filter rarefaction
没有看懂,但是作者说没用,就先挖一个坑,等有空再回来填。
3.3 Upsampling is backwards strided convolution
从某种意义上,伴随因子f的上采样是对步长为1/f的分数式输入的卷积操作。只要f是整数,一种自然的方法进行上采样就是向后卷积(有时称为去卷积)伴随输出步长为f。这样的操作实现是不重要的,因为它只是简单的调换了卷积的顺推法和逆推法。所以上采样在网内通过计算像素级别的损失的反向传播用于端到端的学习。
需要注意的是去卷积滤波在这种层面上不需要被固定不变(比如双线性上采样)但是可以被学习。一堆反褶积层和激励函数甚至能学习一种非线性上采样。在我们的实验中,我们发现在网内的上采样对于学习dense prediction是快速且有效的。
3.4. Patchwise training is loss sampling
结论没有发现对于dense prediction,分块有更快或是更好的收敛效果,全图式训练是有效且高效的。
但是我的问题是没有搞懂这个题目,为什么分块是有损失的采样。
4. SegmentationArchitecture
介绍 FCN 的三大特点:将卷积层转化为全连接层,使用 fine-tuning 的方法进行训练和跳跃连接。
在训练的时候使用逐像素的多项式逻辑回归损失,在评价验证机上的效果时使用标准的指标——平均像素IoU,这里计算的平均值是相对于所有类别的平均值,包括背景在内。
4.1 From classifier to dense FCN
对于大多数的分类网,去掉最后一层分类层,将全连接层改为卷积层最后将输出进行反卷积,得到一个与输入图像大小相同,但是通道数多很多的结果,如下图所示
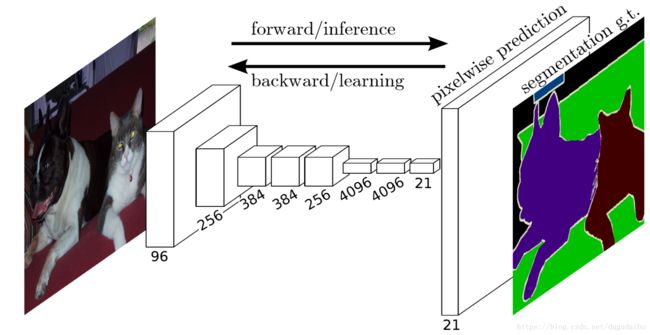
我们可以看到,最后的输出层(即 pixelwise prediction)的通道数为21,这并不是最后的分割结果,分割的结果应该是对每个像素所在的位置,输出该位置 21 个通道中数值最大的那个,即输出每个位置像素点的分类结果。
之后作者给出了如下的实验结果
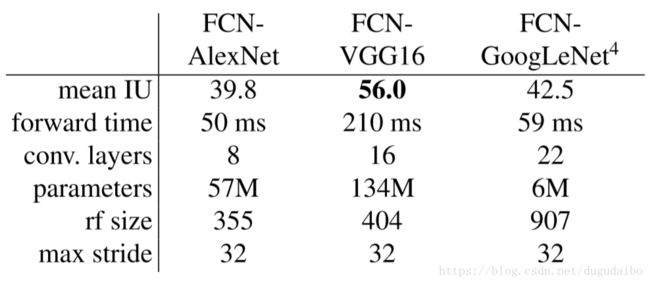
作者表示效果很好。但是对于具有相似分类效果的 GoogleNet 和 VGG ,对于分割的结果相差的去比较多
4.2 Combining what and where
虽然使用 4.1 的方法在指标上获得了较好的结果,但是分割结果看起来依旧很粗糙,所以采用跳跃连接结构对分割结果进行细化,即如下图所示
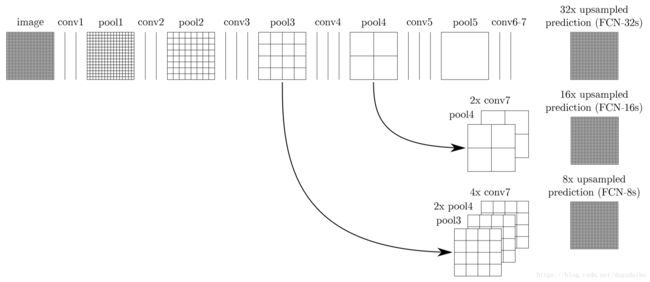
其中我们看到第一行的 pool4 画了一个箭头直接指向第二行的 pool4,这不是直接拿过来用,而是在第一行的 pool4 上面增加一个 1x1 的卷积层使其产生一个额外的分类预测。这里需要注意了,第二行的这个pool4 实际是一个分类预测,所以他的通道数和 conv7 是相同的。之后将 conv7 进行两倍的上采样,这里采用双线性插值的方法(实际上是反卷积),插值的权重是可学习的。然后将第二行的 pool4 与 2x conv7 相加,在进行 16 倍的上采样(反卷积)就可以得到最后的结果。这里 1x1 的卷积初始化为 0,保持其认识原来的分割结果,即 FCN-16s。我理解的,上采样的过程都是使用双线性插值的方法进行初始化的。使用类似的方法可以得到 FCN-8s。
实验结果如下图所示
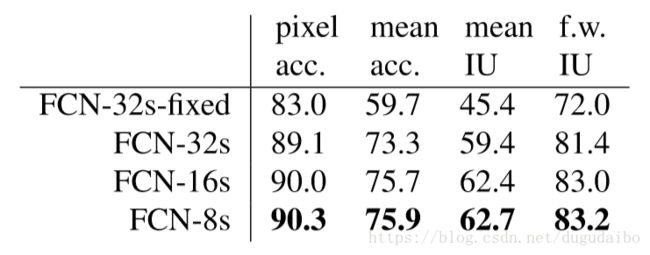
通过上面的实验结果可以发现,FCN-8s 的效果最好;当上采样的步长降低到 8 的时候,效果提升已经不是很明显了。即收益递减,可以不用融合更多的浅层特征了。
4.3 实验框架
其中讲述微调的部分需要注意,整个网络都在使用微调这种技术。**对于分类层采用零初始化,而不是随机初始化。**并且说明了整体微调的效果比只对分类层微调的效果要好;花费了三天的时间微调 FCN-32s,花费了1 的时间更新到 FCN-16s,FCN-8s 也是花费了一天的时间。
5. Result
略
3. 实现细节 [ 4 ] ^{[4]} [4]
3.1 为什么首层卷积层要pad 100像素?
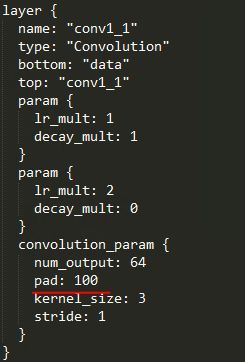
100像素输入填充可确保网络输出可与给定数据集中任何输入大小的输入对齐,例如PASCAL VOC。 [ 5 ] ^{[5]} [5]
至于为什么可以,我们可以看下下面的推导过程。假设是一般的VGG16结构,第一个卷积层只pad 1,并且假设输入图片的高度是h,根据我们的卷积公式
conv1_1: h 1 = ( h + 2 ∗ 1 − 3 ) / 1 + 1 = h h^1=(h+2*1-3)/1+1=h h1=(h+2∗1−3)/1+1=h
conv1_2: h 2 = ( h + 2 ∗ 1 − 3 ) / 1 + 1 = h h^2=(h+2*1-3)/1+1=h h2=(h+2∗1−3)/1+1=h
我们发现,VGG中缩小输出map只在池化层,所以下面我们忽略卷积层:
pool1: h 1 = ( h − 2 ) / 2 + 1 = h / 2 h^1=(h-2)/2+1=h/2 h1=(h−2)/2+1=h/2
pool2: h 2 = ( h 1 − 1 ) / 2 + 1 = h / 2 2 h^2=(h^1-1)/2+1=h/2^2 h2=(h1−1)/2+1=h/22
pool3: h 3 = ( h 2 − 2 ) / 2 + 1 = h / 2 3 h^3=(h^2-2)/2+1=h/2^3 h3=(h2−2)/2+1=h/23
……
pool5: h 5 = ( h 4 − 2 ) / 2 + 1 = h / 2 5 h^5=(h^4-2)/2+1=h/2^5 h5=(h4−2)/2+1=h/25
很明显,feature map的尺寸缩小了32倍,接下来是卷积化的fc6层,如下图
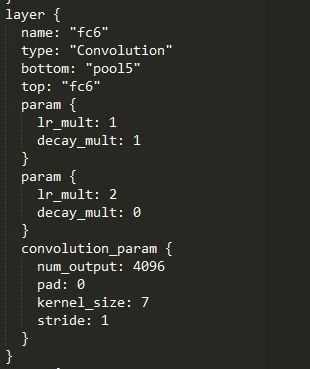
fc6: h 6 = ( h 5 − 7 ) / 1 + 1 = h / 2 5 − 6 = ( h − 192 ) / 2 5 h^6 = (h^5-7)/1+1=h/2^5-6=(h-192)/2^5 h6=(h5−7)/1+1=h/25−6=(h−192)/25
接下来还有两个卷积化的全连接层,fc7以及score_fr,但他们都是1*1的卷积核,对输出的尺寸并不会有影响,所以最终在输入反卷积之前的尺寸就是 h 6 h^6 h6!
推导到这里pad 100的作用已经很明显了,如果不进行padding操作,对于长或宽不超过192像素的图片是没法处理的,而当我们pad 100像素之后,
conv1_1: h 1 = ( h + 2 ∗ 100 − 3 ) / 1 + 1 = h + 198 h^1=(h+2*100-3)/1+1=h+198 h1=(h+2∗100−3)/1+1=h+198
……
fc6: h 6 = ( h 5 − 7 ) / 1 + 1 = ( h + 198 ) / 2 5 − 6 = ( h + 6 ) / 2 5 h^6 = (h^5-7)/1+1=(h+198)/2^5-6=(h+6)/2^5 h6=(h5−7)/1+1=(h+198)/25−6=(h+6)/25
这样就解决了以上问题,但是毋庸置疑,这会引入很多噪声。同样这样的输出会使得上采样得到的图像与输入图像不等大,所以以计算必要的精确 offset参数 并消除这种填充量。
3.2 学习插值是必要的吗?
在我们的原始实验中,插值层被初始化为双线性核,然后学习。在后续实验和该参考实现中,双线性内核是固定的。我们的实验在准确度上没有显着差异,修复这些参数可以略微提高速度。请注意,在我们的网络中,每个输出类只有一个插值内核,并且高维和非线性插值的结果可能不同,为此可以进一步学习。
4. 文章的创新点
实际上理解好这篇文章,只需要理解好一下三点即可
(1) 将分类网改写为用于分割的像素点分类网。具体的包括两个方面,即将全连接层改写为卷积层,和使用反卷积完成上采样的过程;
(2) 使用跳跃连接的结构,将深的粗糙的信息与浅的精细的信息相结合,产生准确和精细的分割;
(3) 使用微调进行实验。
5. 文章的缺点
在这里我们要注意的是FCN的缺点:
(1) 分割结果不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
(2) 是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
参考
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[2] 博客园 一生不可自决《Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)》
[3] 博客园 代码初学者 《全卷积网络 FCN 详解》
[4] 余俊 知乎专栏 - 深度学习:从入门到放弃-《FCN学习:Semantic Segmentation》
[5] shelhamer GitHub https://github.com/shelhamer/fcn.berkeleyvision.org