在开发中我们会经常碰到一些资源需要做缓存优化,例如Bitmap,Json等,那么今天我们来学习本地磁盘来做缓存的实现原理
项目地址:DiskLruCache
简介
在姊妹篇中我们分析了LruCache的源码,LruCache的策略是给空间做上限来做缓存,而DiskLruCache的策略是给本地磁盘做空间上限,由于读写本地文件设计IO流操作,效率会比操作内存低一级,一般我们在图片框架做三级缓存策略,在内存中未命中缓存的时候走本地磁盘缓存。
本文分析的DiskLruCache的源码是来自Android界的巨擘JakeWharton,与Glide框架的本地磁盘缓存实现代码几乎一致。
使用
private void test() {
try {
//获取logo
Drawable drawable = ContextCompat.getDrawable(this, R.mipmap.ic_launcher);
Bitmap bitmap = ((BitmapDrawable) drawable).getBitmap();
//写入到外部存储
File dir = new File(Environment.getExternalStorageDirectory(), "test_screenshot");
if (!dir.exists()) {
dir.mkdirs();
}
//开启
DiskLruCache diskLruCache = DiskLruCache.open(dir, 1, 1, 100 * 1024 * 1024);
//当前时间作为名称
DiskLruCache.Editor editor = diskLruCache.edit(Long.toString(System.currentTimeMillis()));
//获取一个输出流
BufferedOutputStream outputStream = new BufferedOutputStream(editor.newOutputStream(0));
//Bitmap压缩,
bitmap.compress(Bitmap.CompressFormat.JPEG, 100, outputStream);
//IO操作完毕
editor.commit();
//确保都写入日志
diskLruCache.flush();
//回收资源
diskLruCache.close();
Toast.makeText(this, "成功", Toast.LENGTH_SHORT).show();
} catch (IOException e) {
e.printStackTrace();
}
}
笔者这里随便写了一个例子,将默认的图片保存到外部存储,方法执行后我们在这个路径可以发现多了2个文件
我们先来瞄一眼这个日志文件
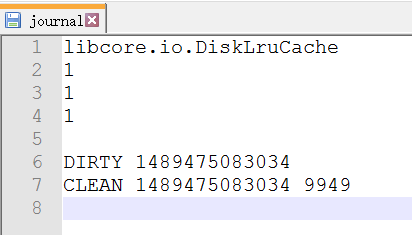
里面记录了我们缓存文件的名字和大小的样子,我们以后再来详细解读它,那么另外一个后缀.0的文件就是我们的图片了,我们把它格式强转一看,果然
分析
由于是随便压缩的,效果惨不忍睹,我们按老套路,来看看DiskLruCache的调用入口:
public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize)
throws IOException {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
if (valueCount <= 0) {
throw new IllegalArgumentException("valueCount <= 0");
}
//日志文件的备份
File backupFile = new File(directory, JOURNAL_FILE_BACKUP);
if (backupFile.exists()) {
File journalFile = new File(directory, JOURNAL_FILE);
//如果已经有新的日志,那就把备份文件删了
if (journalFile.exists()) {
backupFile.delete();
} else {
//将备份文件重命名为journal
renameTo(backupFile, journalFile, false);
}
}
//将缓存文件存放目录,软件版本号,一个key对应缓存文件数目,缓存文件上限传入构造器
DiskLruCache cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
if (cache.journalFile.exists()) {
//日志文件存在的情况下
try {
cache.readJournal();
cache.processJournal();
cache.journalWriter = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(cache.journalFile, true), Util.US_ASCII));
return cache;
} catch (IOException journalIsCorrupt) {
System.out
.println("DiskLruCache "
+ directory
+ " is corrupt: "
+ journalIsCorrupt.getMessage()
+ ", removing");
cache.delete();
}
}
//创建缓存目录
directory.mkdirs();
//重新new,有点迷?
cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
//构建日志文件
cache.rebuildJournal();
return cache;
}
可以看到,open方法对是否有日志文件进行了判断,我们直接先看没日志的情况,将缓存文件存放目录,软件版本号,一个key对应缓存文件数目,缓存文件上限传入DiskLruCache构造器
private DiskLruCache(File directory, int appVersion, int valueCount, long maxSize) {
this.directory = directory;
this.appVersion = appVersion;
this.journalFile = new File(directory, JOURNAL_FILE);
this.journalFileTmp = new File(directory, JOURNAL_FILE_TEMP);
this.journalFileBackup = new File(directory, JOURNAL_FILE_BACKUP);
this.valueCount = valueCount;
this.maxSize = maxSize;
}
构造器中赋值了几个int变量外,为日志相关的File进行了配置,我们来看看日志文件第一次是怎么生成的:
private synchronized void rebuildJournal() throws IOException {
if (journalWriter != null) {
//关闭之前的日志写入流
journalWriter.close();
}
//创建一个日志输出流到临时文件
Writer writer = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(journalFileTmp), Util.US_ASCII));
try {
//拼接信息,版本号等
writer.write(MAGIC);
writer.write("\n");
writer.write(VERSION_1);
writer.write("\n");
writer.write(Integer.toString(appVersion));
writer.write("\n");
writer.write(Integer.toString(valueCount));
writer.write("\n");
writer.write("\n");
for (DiskLruCache.Entry entry : lruEntries.values()) {
//遍历map,将值取出来
if (entry.currentEditor != null) {
writer.write(DIRTY + ' ' + entry.key + '\n');
} else {
writer.write(CLEAN + ' ' + entry.key + entry.getLengths() + '\n');
}
}
} finally {
writer.close();
}
if (journalFile.exists()) {
//再次检验,如果之前有日志文件,将其命名为备份
renameTo(journalFile, journalFileBackup, true);
}
//将这次写入的临时文件转正为日志文件
renameTo(journalFileTmp, journalFile, false);
//删除备份文件
journalFileBackup.delete();
//创建一个流准备下次读写用
journalWriter = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(journalFile, true), Util.US_ASCII));
}
大致意思就是第一次生成日志文件的时候将一些信息写入到文件流中,没什么太大营养,我们来看看lruEntries这个map,
private final LinkedHashMap lruEntries =new LinkedHashMap(0, 0.75f, true);
和姊妹篇:LruCache源码分析中的LinkedHashMap构造器一致,我们来看看Entry是什么
private final class Entry {
//key
private final String key;
//记录缓存文件长度
private final long[] lengths;
//是否可读
private boolean readable;
//用来记录编辑器
private DiskLruCache.Editor currentEditor;
//编辑的序列号
private long sequenceNumber;
private Entry(String key) {
this.key = key;
this.lengths = new long[valueCount];
}
public String getLengths() throws IOException {
StringBuilder result = new StringBuilder();
for (long size : lengths) {
result.append(' ').append(size);
}
return result.toString();
}
private void setLengths(String[] strings) throws IOException {
if (strings.length != valueCount) {
throw invalidLengths(strings);
}
try {
for (int i = 0; i < strings.length; i++) {
lengths[i] = Long.parseLong(strings[i]);
}
} catch (NumberFormatException e) {
throw invalidLengths(strings);
}
}
private IOException invalidLengths(String[] strings) throws IOException {
throw new IOException("unexpected journal line: " + java.util.Arrays.toString(strings));
}
public File getCleanFile(int i) {
return new File(directory, key + "." + i);
}
public File getDirtyFile(int i) {
return new File(directory, key + "." + i + ".tmp");
}
}
看到这里我们好像已经看出点什么了,在Entry用来记录长度为什么是一个数组,其实在DiskLruCache#open方法中我们传入了一个int类型的valueCount,其实就是代表一个对应的key可以有几个文件,如果我们传入的参数大于1,那么缓存文件后缀就是.0,.1等等。
接下来我们来看看DiskLruCache#edit的操作过程
public DiskLruCache.Editor edit(String key) throws IOException {
return edit(key, ANY_SEQUENCE_NUMBER);
}
private synchronized DiskLruCache.Editor edit(String key, long expectedSequenceNumber) throws IOException {
//校验日志读写器
checkNotClosed();
//校验key命名是否合法,正则表达式匹配Pattern.compile("[a-z0-9_-]{1,64}")
validateKey(key);
//LinkedHashMap#get中将数据点移到末尾
Entry entry = lruEntries.get(key);
if (expectedSequenceNumber != ANY_SEQUENCE_NUMBER && (entry == null
|| entry.sequenceNumber != expectedSequenceNumber)) {
//安全校验
return null;
}
if (entry == null) {
//新增一个Entry并放到map中
entry = new Entry(key);
lruEntries.put(key, entry);
} else if (entry.currentEditor != null) {
//多线程时校验
return null;
}
Editor editor = new Editor(entry);
entry.currentEditor = editor;
//日志中写入一条操作记录
journalWriter.write(DIRTY + ' ' + key + '\n');
journalWriter.flush();
return editor;
}
完成了对读写流和key的校验后,实例化了一个Entry放到map集合中,并实例化了一个编辑器Editor,放到了Entry的currentEditor中,相互持有引用,然后往日志写入了一条操作记录,我们来看看Editor这个类
public final class Editor {
private final Entry entry;
private final boolean[] written;
private boolean hasErrors;
private boolean committed;
private Editor(Entry entry) {
this.entry = entry;
//默认不可读,新建一个数组
this.written = (entry.readable) ? null : new boolean[valueCount];
}
public InputStream newInputStream(int index) throws IOException {
synchronized (DiskLruCache.this) {
if (entry.currentEditor != this) {
throw new IllegalStateException();
}
if (!entry.readable) {
//不可读的状态
return null;
}
try {
//返回一个文件输入流,真实文件路径
return new FileInputStream(entry.getCleanFile(index));
} catch (FileNotFoundException e) {
return null;
}
}
}
public String getString(int index) throws IOException {
//将流以字符串的形式输出
InputStream in = newInputStream(index);
return in != null ? inputStreamToString(in) : null;
}
public OutputStream newOutputStream(int index) throws IOException {
synchronized (DiskLruCache.this) {
if (entry.currentEditor != this) {
throw new IllegalStateException();
}
if (!entry.readable) {
//标记状态
written[index] = true;
}
//获取缓存文件的临时路径
File dirtyFile = entry.getDirtyFile(index);
FileOutputStream outputStream;
try {
outputStream = new FileOutputStream(dirtyFile);
} catch (FileNotFoundException e) {
//创建
directory.mkdirs();
try {
outputStream = new FileOutputStream(dirtyFile);
} catch (FileNotFoundException e2) {
// We are unable to recover. Silently eat the writes.
return NULL_OUTPUT_STREAM;
}
}
//返回一个catch异常的输出流
return new DiskLruCache.Editor.FaultHidingOutputStream(outputStream);
}
}
public void set(int index, String value) throws IOException {
Writer writer = null;
try {
//向流中写入字符串
writer = new OutputStreamWriter(newOutputStream(index), Util.UTF_8);
writer.write(value);
} finally {
Util.closeQuietly(writer);
}
}
public void commit() throws IOException {
//完成编辑
if (hasErrors) {
completeEdit(this, false);
remove(entry.key);
} else {
completeEdit(this, true);
}
committed = true;
}
public void abort() throws IOException {
//中止编辑
completeEdit(this, false);
}
public void abortUnlessCommitted() {
//未完成则中止编辑
if (!committed) {
try {
abort();
} catch (IOException ignored) {
}
}
}
}
我们从上到下来看,在构造器初始化时Editor的readable是为false的,文件都还没有生成,当然不可读然后初始化了一个记录写入状态的数组,这里我们又见到了valueCount,也印证了我们前文的猜测。
-
newInputStream方法很简单,就是我们要读缓存的时候会用到,直接返回一个按照key+小数点+index拼接的文件输入流。 -
newOutputStream方法,也就是我们向缓存目录写入的时候要调用的方法,在写入缓存的时候,返回一个文件输出流,路径在key+小数点+index+".tmp",也就是临时文件,其中返回的流经过一层封装,将异常catch了。 -
get和set方法是以上2个方法的封装版,例如我们要缓存json字符串的时候就可以方便快捷的读写了 -
commit方法是我们执行完操作一定要调的,例如在写入后文件还是临时文件的状态下是不算成功写入的,如果在写入的时候。封装的输出流catch到异常,那会将临时文件都删除,下面会讲到 -
abort中断方法,如果写入操作是个耗时方法的话,我们在页面关闭的时候可以用来回收资源。
在abort和commit中都调用了completeEdit这个堪称终结的方法,我们来点进去看看:
private synchronized void completeEdit(Editor editor, boolean success) throws IOException {
Entry entry = editor.entry;
if (entry.currentEditor != editor) {
//校验
throw new IllegalStateException();
}
//这里readable还是false的状态
if (success && !entry.readable) {
for (int i = 0; i < valueCount; i++) {
if (!editor.written[i]) {
//简单来说就是valueCount>1的时候,每个索引都要写入操作
editor.abort();
throw new IllegalStateException("Newly created entry didn't create value for index " + i);
}
if (!entry.getDirtyFile(i).exists()) {
//临时文件还不存在的做中断处理
editor.abort();
return;
}
}
}
for (int i = 0; i < valueCount; i++) {
File dirty = entry.getDirtyFile(i);
if (success) {
if (dirty.exists()) {
//将临时文件重命名成正式文件
File clean = entry.getCleanFile(i);
dirty.renameTo(clean);
long oldLength = entry.lengths[i];
long newLength = clean.length();
//记录大小和map的空间大小
entry.lengths[i] = newLength;
size = size - oldLength + newLength;
}
} else {
//失败的话吧临时文件删除
deleteIfExists(dirty);
}
}
redundantOpCount++;
//操作完毕,置为空
entry.currentEditor = null;
if (entry.readable | success) {
//第一次写入成功情况下或者曾经写入成功过
entry.readable = true;
//记录一条日志,格式为 操作符+空格+key+空格+文件大小(数组通过StringBuilder拼接,多个中间用空格拼接)
journalWriter.write(CLEAN + ' ' + entry.key + entry.getLengths() + '\n');
if (success) {
//序列号+1
entry.sequenceNumber = nextSequenceNumber++;
}
} else {
//第一次写入失败
lruEntries.remove(entry.key);
journalWriter.write(REMOVE + ' ' + entry.key + '\n');
}
journalWriter.flush();
if (size > maxSize || journalRebuildRequired()) {
//触发清理操作
executorService.submit(cleanupCallable);
}
}
这个方法有点长,我们一点一点来看。
- 先对编辑器进行了校验,然后进入了一个if-else判断,这里的
readable由于到现在从未有过赋值,并且编辑状态也还没结束,所以一直未false,这里的for循环笔者分析为当我们给DiskLruCache设置一个key可以带多个索引的缓存文件时,写入操作必须对所有对应该key的文件都进行操作,私以为此处设计不太合理,接下来如果临时文件还不存在的话对其中断操作。 - 接下来的for循环对操作成功的临时文件进行了重命名操作,就像临时工变成了正式员工,失败的话把它删除,这些操作完毕了,那自然要在日志文件中留下我们的足迹,这里有个或运算,因为文件可以二次写入,简单来说就是如果我们第一次写入成功了或者这是二次写入操作,就把
readable标志设为true,并且往日志插入一条记录,格式为操作符+空格+key+空格+文件大小(数组通过StringBuilder拼接,多个中间用空格拼接),除此以外的情况就是第一次写入就失败的情况,那就把map中的记录消除,并记录一条日志。 - 最后的if-else则是如果空间满了就进行清除。这里涉及到了一个变量
redundantOpCount,笔者理解为操作次数过多时,日志文件会越来越大,这是也会触发重新写日志。
那么到这里这个方法也被我们扒了个底朝天,我们再来看看最后一句executorService.submit(cleanupCallable),DiskLruCache对清理超出的缓存是怎么处理的呢?
final ThreadPoolExecutor executorService =
new ThreadPoolExecutor(0, 1, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue());
private final Callable cleanupCallable = new Callable() {
public Void call() throws Exception {
synchronized (DiskLruCache.this) {
if (journalWriter == null) {
return null;
}
trimToSize();
if (journalRebuildRequired()) {
rebuildJournal();
redundantOpCount = 0;
}
}
return null;
}
};
在DiskLruCache类中定义了一个线程池,也对,毕竟在计算缓存上限的时候执行删除文件,写入日志很可能是一个耗时任务,在线程池的设计上选用了单线程的设计,毕竟IO并发读写会发生意想不到的状况。
这里个人理解有设计不太合理,都单线程了,还在call方法中加了同步锁,而且还是Callable
跳过吐槽,我们来看清理缓存的方法trimToSize
private void trimToSize() throws IOException {
while (size > maxSize) {
Map.Entry toEvict = lruEntries.entrySet().iterator().next();
//迭代清理
remove(toEvict.getKey());
}
}
public synchronized boolean remove(String key) throws IOException {
checkNotClosed();
validateKey(key);
DiskLruCache.Entry entry = lruEntries.get(key);
if (entry == null || entry.currentEditor != null) {
//为空或者还在编辑状态中,就先放它一马
return false;
}
for (int i = 0; i < valueCount; i++) {
File file = entry.getCleanFile(i);
//删除文件,并重新计算大小
if (file.exists() && !file.delete()) {
throw new IOException("failed to delete " + file);
}
size -= entry.lengths[i];
entry.lengths[i] = 0;
}
redundantOpCount++;
//插入一条记录
journalWriter.append(REMOVE + ' ' + key + '\n');
lruEntries.remove(key);
//判断荣冗余值?
if (journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
return true;
}
清理和LruCache的原理差不多,因为在DiskLruCache#edit方法中已经刷新了缓存的位置,然后就是将最老的缓存文件删除了,这里的同步锁略多,强迫症的同学可以对其源码进行优化
至此,我们对DiskLruCache的源码快分析完了,让我们再加把劲(๑•̀ㅂ•́)و✧
分析到这里我们还有一个点没有分析,就是关闭App,后续进行二次读写的时候,DiskLruCache的map队列已经被清空了,是怎么获取到之前该目录下的缓存信息呢,来,我们回到最初的DiskLruCache#open方法,其中有这么一个判断:
if (cache.journalFile.exists()) {
try {
//读取日志
cache.readJournal();
//处理日志,二次校验
cache.processJournal();
cache.journalWriter = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(cache.journalFile, true), Util.US_ASCII));
return cache;
} catch (IOException journalIsCorrupt) {
System.out
.println("DiskLruCache "
+ directory
+ " is corrupt: "
+ journalIsCorrupt.getMessage()
+ ", removing");
cache.delete();
}
}
也就是当日志文件存在的情况下会对文件进行解析。
private void readJournal() throws IOException {
StrictLineReader reader = new StrictLineReader(new FileInputStream(journalFile), Util.US_ASCII);
try {
//逐行读取数据
String magic = reader.readLine();
String version = reader.readLine();
String appVersionString = reader.readLine();
String valueCountString = reader.readLine();
String blank = reader.readLine();
if (!MAGIC.equals(magic)
|| !VERSION_1.equals(version)
|| !Integer.toString(appVersion).equals(appVersionString)
|| !Integer.toString(valueCount).equals(valueCountString)
|| !"".equals(blank)) {
//日志格式不规范
throw new IOException("unexpected journal header: [" + magic + ", " + version + ", "
+ valueCountString + ", " + blank + "]");
}
int lineCount = 0;
while (true) {
try {
//遍历读取日志主体部分
readJournalLine(reader.readLine());
lineCount++;
} catch (EOFException endOfJournal) {
break;
}
}
redundantOpCount = lineCount - lruEntries.size();
} finally {
Util.closeQuietly(reader);
}
}
StrictLineReader是一个逐行读取器,感兴趣的同学可以自己去看看,代码不多,这里就不分析了。
当读取的日志格式发生错误时会抛出异常,被open方法拦截下来,然后将这个不符合格式的日志删除掉并新建,比如app版本号更新之类的,接下来我们来看看日志主体部分是怎么读取的,readJournalLine:
private void readJournalLine(String line) throws IOException {
int firstSpace = line.indexOf(' ');
if (firstSpace == -1) {
throw new IOException("unexpected journal line: " + line);
}
//key开始位置
int keyBegin = firstSpace + 1;
//第二个空格位置
int secondSpace = line.indexOf(' ', keyBegin);
final String key;
if (secondSpace == -1) {
//只有一个空格
key = line.substring(keyBegin);
if (firstSpace == REMOVE.length() && line.startsWith(REMOVE)) {
lruEntries.remove(key);
return;
}
} else {
key = line.substring(keyBegin, secondSpace);
}
DiskLruCache.Entry entry = lruEntries.get(key);
if (entry == null) {
entry = new DiskLruCache.Entry(key);
lruEntries.put(key, entry);
}
if (secondSpace != -1 && firstSpace == CLEAN.length() && line.startsWith(CLEAN)) {
//干净的数据,将其赋值到Entry中
String[] parts = line.substring(secondSpace + 1).split(" ");
entry.readable = true;
entry.currentEditor = null;
entry.setLengths(parts);
} else if (secondSpace == -1 && firstSpace == DIRTY.length() && line.startsWith(DIRTY)) {
//脏数据
entry.currentEditor = new DiskLruCache.Editor(entry);
} else if (secondSpace == -1 && firstSpace == READ.length() && line.startsWith(READ)) {
//读就跳过
} else {
throw new IOException("unexpected journal line: " + line);
}
}
通过判断空格的位置和字符串的判断,把信息都存入了map中的Entry中,接着调用DiskLruCache#processJournal
private void processJournal() throws IOException {
deleteIfExists(journalFileTmp);
for (Iterator i = lruEntries.values().iterator(); i.hasNext(); ) {
DiskLruCache.Entry entry = i.next();
if (entry.currentEditor == null) {
//干净数据,计算map大小
for (int t = 0; t < valueCount; t++) {
size += entry.lengths[t];
}
} else {
//清理脏数据
entry.currentEditor = null;
for (int t = 0; t < valueCount; t++) {
deleteIfExists(entry.getCleanFile(t));
deleteIfExists(entry.getDirtyFile(t));
}
i.remove();
}
}
}
最后对map中的脏数据文件进行清理。
总结
那么总体下来我们对DiskLruCache的源码基本分析完毕,整理一下可以分为以下几点:
- 调用
DiskLruCache#open方法会初始化日志相关参数,返回DiskLruCache对象。 - 调用
DiskLruCache#edit方法初始化一个Editor实例,并设置为指定Entry的当前编辑器,此时在日志插入一条脏数据记录,返回Editor对象。 - 通过
Editor来调用方法完成操作,需调用commit方法来通知DiskLruCache将临时文件装换成真正的缓存文件以及插入日志记录。 - 最后调用
DiskLruCache#flush方法计算缓存文件是否超过上限,超过则清理,且这个方法不建议频繁调用,用来保证同步写入日志操作。 -
DiskLruCache#close关闭日志读写器以及最后的回收资源。 -
Editor编辑操作可以中断,写入操作的异常会被拦截,执行完毕后临时文件将会被删除。 -
journal日志内容按照指定格式拼接,主体部分包含操作符+空格+文件名+空格+文件大小数组(空格拼接)。 - 日志文件版本发生冲突时会将老的删除新建一个。
-
DiskLruCache#get获取这个key的所有缓存文件的切片,操作符是READ而不是标记为脏数据DIRTY。 -
DiskLruCache#delete相当于close方法后清除缓存目录下全部文件。 -
DiskLruCache#setMaxSize重新计算缓存空间。 - 之所以叫脏数据是Editor操作后不知道结果,一般在DIRTY的后续会有对应的CLEAN或者REMOVE。
- 不要担心丧心病狂的读写会导致日志文件爆棚(;¬_¬),这个
redundantOpCount变量会控制重新生成日志文件。 - DiskLruCache是线程安全的。
- DiskLruCache和LruCache的相同点是缓存文件都先写入,然后触发计算空间大小来判断是否删除近期时间最少使用的文件,知道缓存文件的大小小于阈值。
文章如有错误,敬请指正!
本文的姊妹篇:LruCache源码分析
因为 神差他的儿子降世,不是要定世人的罪,乃是要叫世人因他得救。信他的人,不被定罪;不信的人,罪已经定了,因为他不信 神独生子的名。 (约翰福音 3:17-18 和合本)