调试从Caffe模型转换过来的Pytorch模型
系列博客目录:Caffe转Pytorch模型系列教程 概述
目录
- 一、检查Pytorch模型是否正确地载入了参数
- 二、检查网络模型是否正确
- 1、对比Pytorch模型与.prototxt可视化结果
- 2、运行两个网络对应的层并对比结果
- 2.1 Caffe模型获取指定层的结果
- 2.2 Pytorch模型获取指定层结果
- 2.3 准备相同的预处理代码
- 2.4 获取conv3的结果
- 3、比对策略
- 4、注意事项
相信看完本系列的前两博客,如果你运气好,你的Pytorch模型说不定已经可以工作了,那么Congratulations,不必往下看了。如果结果不对,那么,你就需要看看我惨痛的调试经历了。
- 本文用的Caffe网络模型文件:SfSNet_deploy.prototxt(右键另存为)。
- SfSNet的Pytorch代码地址:model.py(右键另存为,来源于上一篇博客)。
- SfSNet的权重:SfSNet.caffemodel.h5(右键另存为)。
一、检查Pytorch模型是否正确地载入了参数
这个就很简单了,最简单的思路就是,把网络的参数打印出来,再和从.caffemodel提取出来的对比(这是最容易想到的办法,我一开始也是用的这种方法)。
# coding=utf-8
from __future__ import absolute_import, division, print_function
import pickle
from src.models.model import SfSNet
if __name__ == '__main__':
# 载入提取到的权重
f = open('SfSNet-Caffe/weights.pkl', 'rb')
name_weights = pickle.load(f)
f.close()
# 新建网络实例
net = SfSNet()
# 载入参数
net.load_weights_from_pkl('SfSNet-Caffe/weights.pkl')
# 设置为测试模式
net.eval()
params = dict(net.named_parameters())
# 检查conv1的参数是否载入正确
print(params['conv1.weight'].detach().numpy())
print(name_weights['conv1']['weight'])
但是这种方法,对眼睛真的超超超不友好啊,所以稍微改进下,写函数替我们去判断:
import numpy as np
def same(arr1, arr2):
# type: (np.ndarray, np.ndarray) -> bool
# 判断shape是否相同
assert arr1.shape == arr2.shape
# 对应元素相减求绝对值
diff = np.abs(arr1 - arr2)
# 判断是否有任意一个两元素之差大于阈值1e-5
return (diff < 1e-5).any()
def compare(layer, params, name_weights):
# type: (str, dict, dict) -> tuple[bool, bool]
# 判断权重
w = same(params[layer+'.weight'].detach().numpy(), name_weights[layer]['weight'])
# 判断偏置
b = same(params[layer+'.bias'].detach().numpy(), name_weights[layer]['bias'])
return w, b
然后就可以使用:
print(compare('conv1', params, name_weights))
来检查conv1的参数。其他层的参数检查我就不一一举例了,读者知道怎么办的。
二、检查网络模型是否正确
1、对比Pytorch模型与.prototxt可视化结果
就以本文的例子来说,就是拿着SfSNet_deploy.prototxt的可视化结果(可视化方法参见:把Caffe的模型转换为Pytorch模型)和Pytorch模型的对比。如果幸运,检查到哪里出错了,修改完,模型ok了,那完美;如果还是不行,看下一步。
2、运行两个网络对应的层并对比结果
这一步的目的是检查问题到底出在那一层。知道出在那一层之后,才好解决bug。
2.1 Caffe模型获取指定层的结果
# coding=utf-8
from __future__ import absolute_import, division, print_function
import caffe
if __name__ == '__main__':
# prototxt文件
MODEL_FILE = 'SfSNet-Caffe/SfSNet_deploy.prototxt'
# 预先训练好的caffe模型
PRETRAIN_FILE = 'SfSNet-Caffe/SfSNet.caffemodel.h5'
# 载入网络
net = caffe.Net(MODEL_FILE, PRETRAIN_FILE, caffe.TEST)
...
# 前向传播
out = net.forward(end='conv3')
forward函数有个end参数,设置了此参数时,网络在向前传播到conv3时(遇到第一个conv3就会立即返回结果),就会返回conv3的结果:一个dict,key是’conv3’,值是conv3的结果。还有一种方法是:
# 前向传播
out = net.forward()
# 获取层conv3的结果
conv3 = net.blobs['conv3'].data
可以通过net的blobs属性获得前向传播后的结果。
2.2 Pytorch模型获取指定层结果
这个很简单了,直接修改model.py,在forward函数里返回该层的结果就行。
class SfSNet(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
# C64
super(SfSNet, self).__init__()
# TODO 初始化器 xavier
self.conv1 = nn.Conv2d(3, 64, 7, 1, 3)
self.bn1 = nn.BatchNorm2d(64)
# C128
self.conv2 = nn.Conv2d(64, 128, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(128)
# C128 S2
self.conv3 = nn.Conv2d(128, 128, 3, 2, 1)
...
def forward(self, inputs):
# C64
x = F.relu(self.bn1(self.conv1(inputs)))
# C128
x = F.relu(self.bn2(self.conv2(x)))
# C128 S2
conv3 = self.conv3(x)
# 返回conv3的结果
return conv3
# ------------RESNET for normals------------
# RES1
x = self.n_res1(conv3)
...
return normal, albedo, light
def load_weights_from_pkl(self, weights_pkl):
from torch import from_numpy
with open(weights_pkl, 'rb') as wp:
...
state_dict = {}
...
self.load_state_dict(state_dict)
然后:
if __name__ == '__main__':
# 新建网络实例
net = SfSNet()
# 载入参数
net.load_weights_from_pkl('SfSNet-Caffe/weights.pkl')
# 设置为测试模式
net.eval()
# 预处理图像
image = ...
# 前向传播
out = net(image)
2.3 准备相同的预处理代码
这一步相当重要,数据输入都不一样,你咋让两个网络输出同样的结果呢???定义SfSNet的预处理函数:
import cv2
def read_image(path):
# type: (str) -> np.ndarray
# 读取图像
image = cv2.imread(path)
# 调整大小为SfSNet的代码
image = cv2.resize(image, (128, 128))
# 缩放到0~1
image = np.float32(image)/255.0
# (128, 128, 3) to (3, 128, 128)
image = np.transpose(image, [2, 0, 1])
# (128, 128, 3) to (1, 3, 128, 128)
image = np.expand_dims(image, 0)
return image
不同的模型可能有不同的预处理步骤,这只是SfSNet的预处理步骤。
2.4 获取conv3的结果
- Caffe模型代码:
if __name__ == '__main__':
# prototxt文件
MODEL_FILE = 'SfSNet-Caffe/SfSNet_deploy.prototxt'
# 预先训练好的caffe模型
PRETRAIN_FILE = 'SfSNet-Caffe/SfSNet.caffemodel.h5'
# 定义网络
net = caffe.Net(MODEL_FILE, PRETRAIN_FILE, caffe.TEST)
# 读取并预处理图像
im = read_image('data/1.png_face.png')
# 前向传播
out = net.forward(end='conv3')
print(out.keys())
# 保存
np.save('conv3.caffe.npy', out['conv3'])
- Pytorch模型代码:
先修改model.py的forward函数,然后再运行代码:
if __name__ == '__main__':
# 新建网络实例
net = SfSNet()
# 载入参数
net.load_weights_from_pkl('SfSNet-Caffe/weights.pkl')
# 设置为测试模式
net.eval()
# 读取并预处理图像
image = read_image('data/1.png_face.png')
# 前向传播
out = net(torch.from_numpy(image))
# 保存
np.save('conv3.pytorch.npy', out[0].detach().numpy())
- 比对结果:
if __name__ == '__main__':
caffe_result = np.load('conv3.caffe.npy')
torch_result = np.load('conv3.pytorch.npy')
# same函数之前有提到
print(same(caffe_result, torch_result))
3、比对策略
可以一层一层地比对,也可以抽出中间的某一层来比对,确定不正确的范围。
4、注意事项
一定要结合可视化结果来比对啊,因为Caffe模型里有很多“In-Place”操作,后面的层运行结束之后,会把前面的层的值修改了!!! 举个例子:
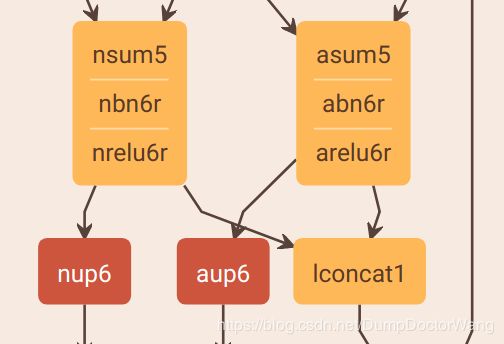
从可视化结果来看,lconcat1的输入是nrelu6r和arelu6r,然而,在.prototxt文件里:
layer {
name: "lconcat1"
bottom: "nsum5"
bottom: "asum5"
top: "lconcat1"
type: "Concat"
concat_param {
axis: 1
}
}
lconcat1的输入是nsum5和asum5。在.prototxt这样写确实是对的,因为nbn6r/abn6r/nrelu6r/arelu6r全是“In-Place层”,修改过的结果又存在nsum5/asum5里面去了。