Linux内核学习笔记——进程通信手段
Linux内核学习笔记——进程通信手段
一.学习内容
1. System V 的 IPC 机制
2. 块设备驱动程序
3. 套接字(socket)
二. 实验工具
工具清单 |
|
代码分析软件 |
source insight 4.0 |
系统环境 |
Windows-10 |
内核版本 |
Linux-2.4.16 |
三.System V 的 IPC 机制
3.1 关于System V
System V是Unix操作系统最早的商业发行版之一。它最初由AT&T(AmericanTelephone & Telegraph)开发,最早在1983年发布。System V主要发行了4个版本,其中SVR4(SystemV Release 4)是最成功的版本。BSD(Berkeley Software Distribution,有时也被称为Berkeley Unix)是加州大学于1977至1995年间开发的。在19世纪八十年代至九十年代之间,System V和BSD代表了Unix的两种主要的操作风格。

图3-1Unix的两种主要操作风格的区别
为与Unix部分操作系统保持兼容性,Linux提供了三种与System V进程间的通信机制:
(1)信号量,用来管理对共享资源的访问
(2)共享内存,用来高效地实现进程间的数据共享
(3)消息队列,用来实现进程间数据的传递。
这三种机制被称为System V IPC 的对象,每个对象都具有一个唯一的IPC标识符,进程可以通过系统调用传递的识别号来存取这些对象,同时要保证不同的进程能够获取同一个IPC对象。
在 Linux 内核中,System V IPC 的对象创被建时由一个公共的数据结构 pc_perm来定义相应的存取权限,相关代码在 linux/ipc.h定义如下:
1. struct ipc_perm
2. {
3. __kernel_key_t key; /* 键 */
4. __kernel_uid_t uid; /* 对象拥有者对应进程的有效用户识别号和有效组识别号 */
5. __kernel_gid_t gid;
6. __kernel_uid_t cuid; /* 对象创建者对应进程的有效用户识别号和有效组识别号 */
7. __kernel_gid_t cgid;
8. __kernel_mode_t mode; /* 存取模式 */
9. unsigned short seq; /* 序列号 */
10. };

图3-2 实现进程间通信的一些方法
3.2 关于信号量
信号量及信号量上的操作作为一种解决同步、互斥问题的较通用的方法,目前已经在很多操作系统中得以实现,而Linux在应用的同时改进了这种机制。
3.2.1 信号量的数据结构
Linux 中信号量是通过内核提供的一系列数据结构实现的,存在于include/linux/sem.h中:
n 系统中每个信号量的数据结构(sem)
1. struct sem {
2. int semval; /* 信号量的当前值 */
3. int sempid; /*在信号量上最后一次操作的进程识别号 *
4. };
n 系统中表示信号量集合(set)的数据结构(semid_ds)
1. struct semid_ds {
2. struct ipc_perm sem_perm; /* IPC 权限 */
3. __kernel_time_t sem_otime; /* 最后一次对信号量操作(semop)的时间 */
4. __kernel_time_t sem_ctime; /* 对这个结构最后一次修改的时间 */
5. struct sem *sem_base; /* 在信号量数组中指向第一个信号量的指针 */
6. struct sem_queue *sem_pending; /* 待处理的挂起操作*/
7. struct sem_queue **sem_pending_last; /* 最后一个挂起操作 */
8. struct sem_undo *undo; /* 在这个数组上的 undo 请求 */
9. unsigned short sem_nsems; /* 在信号量数组上的信号量号 */
10. };
n 系统中每一信号量集合的队列结构(sem_queue)
1. struct sem_queue {
2.
3. struct sem_queue * next; /* 队列中下一个节点 */
4. struct sem_queue ** prev; /* 队列中前一个节点, *(q->prev) == q */
5. struct wait_queue * sleeper; /* 正在睡眠的进程 */
6. struct sem_undo * undo; /* undo 结构*/
7. int pid; /* 请求进程的进程识别号 */
8. int status; /* 操作的完成状态 */
9. struct semid_ds * sma; /*有操作的信号量集合数组 */
10. struct sembuf * sops; /* 挂起操作的数组 */
11. int nsops; /* 操作的个数 */
12.
13. };
通过观察源代码分析可知信号量与信号量集合是不同的概念,分别用“sem”和“semid_ds”结构描述,其中关于信号量数据结构之间关系的描述可由下图表示:
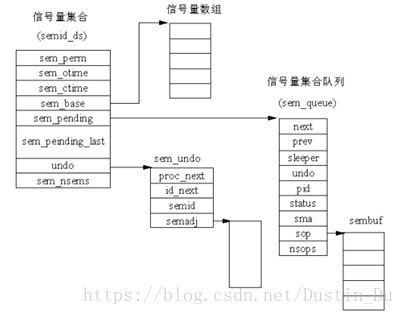
图3-3 System V IPC 信号量数据结构之间的关系
3.2.2 三种系统调用
为了创建一个新的信号量集合,或者存取一个已存在的集合,要使用 segget()系统调用,函数定义如下:
n 系统调用:semget()
原型:int semget( key_t key, int nsems, int semflg );
semget()中的第 1 个参数是键值,这个键值要与已有的键值进行比较,已有的键值指在内核中已存在的其他信号量集合的键值。对信号量集合的打开或存取操作依赖于 semflg 参数的取值:
• IPC_CREAT :如果内核中没有新创建的信号量集合,则创建它。
• IPC_EXCL :当与 IPC_CREAT 一起使用时,如果信号量集合已经存在,则创建失败。
n 系统调用: semop()
原型: int semop ( int semid, struct sembuf *sops,unsigned nsops);
semop()中的第1 个参数(semid)是集合的识别号(可以由 semget()系统调用得到)。第2个参数(sops)是一个指针,它指向在集合上执行操作的数组。而第3个参数(nsops)是在那个数组上操作的个数。
n 系统调用 :semctl(),反映集合上执行控制操作的情况
原型:int semctl( int semid, int semnum, int cmd, union semun arg );
semctl()的第 1 个参数semid是集合的标识号,第 2 个参数semnum是将要操作的信号量个数,从本质上说,它是集合的一个索引,对于集合上的第一个信号量,则该值为0。
3.2.3 死锁
当某个进程修改了信号量而进入临界区之后,却因为崩溃或被“杀死(kill)”而没有退出临界区,这时其他被挂起在信号量上的进程永远得不到运行机会,这就是所谓的死锁。Linux 通过维护一个信号量数组的调整列表(semadj)来避免这一问题。其基本思想是,根据调整列表按步执行,让信号量的状态退回到操作实施前的状态。实现该功能的关键数据结构sem_undo在include/linux/sem.h 描述如下:
1. struct sem_undo {
2. struct sem_undo * proc_next; /*在这个进程上的下一个 sem_undo 节点 */
3. struct sem_undo * id_next; /* 在这个信号量集和上的下一个 sem_undo 节点*/
4. int semid; /* 信号量集的标识号*/
5. short * semadj; /* 信号量数组的调整,每个进程一个*/
6. };
Linux 将为每一个信号量数组的每一个进程维护至少一个 sem_undo 结构。如果请求的进程没有这个结构,当必要时则创建它,新创建的 sem_undo 数据结构既在这个进程的 task_struct 数据结构中排队,也在信号量数组的 semid_ds 结构中排队。
当进程被删除时,Linux完成了对sem_undo 数据结构的设置及对信号量数组的调整。如果一个信号量集合被删除,sem_undo 结构依然留在这个进程的 task_struct 结构中,但信号量集合的识别号变为无效。
3.3 关于消息队列
Linux 中的消息可以被描述成在内核地址空间的一个内部链表,每一个消息队列由一个
IPC的标识号唯一地标识。Linux 为系统中所有的消息队列维护一个msgque 链表,该链表
中的每个指针指向一个 msgid_ds 结构,该结构完整描述一个消息队列。
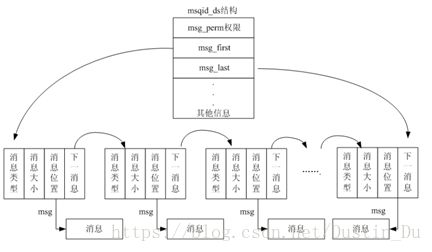
图3-4 消息队列结构示意图
3.3.1 消息队列的数据结构
n 消息缓冲区(msgbuf)
该数据结构可以看成一个存放消息数据的模板,它在 include/linux/msg.h 中声明,描述如下:
1. /* msgsnd 和 msgrcv 系统调用使用的消息缓冲区*/
2. struct msgbuf {
3. long mtype; /* 消息的类型,必须为正数 */
4. char mtext[1]; /* 消息正文 */
5. };
对于消息数据元素(mtext),实际上,这个域不仅能保存字符数组,而且能保存任何形式的任何数据。这个域本身是任意的,因为这个结构本身可以由应用程序员重新定义
1. struct my_msgbuf {
2. long mtype; /* 消息类型 */
3. long request_id; /* 请求识别号 */
4. struct client info; /* 客户消息结构 */
5. };
n 消息结构(msg)
内核把每一条消息存储在以 msg 结构为框架的队列中,它在 include/ linux/msg.h 中
定义如下:
1. struct msg_msg {
2. struct list_head m_list;
3. long m_type; /*消息类型*/
4. int m_ts; /* 消息正文的大小 */
5. struct msg_msgseg* next; /* 队列上的下一条消息 */
6. };
其中msg_next是指向下一条消息的指针,它们在内核地址空间形成一个单链表
n 消息队列结构(msgid_ds)
当在系统中创建每一个消息队列时,内核创建、存储及维护这个结构的一个实例,即系统中的每一个消息队列对应一个msqid_ds 结构
1. struct msqid_ds {
2. struct ipc_perm msg_perm;
3. struct msg *msg_first; /* 队列上第一条消息,即链表头 */
4. struct msg *msg_last; /* 队列上最后一条消息,即链表尾 */
5. __kernel_time_t msg_stime; /* 发送给队列的最后一条消息的时间 */
6. __kernel_time_t msg_rtime; /* 从接受队列中接收到最后一条消息的时间 */
7. __kernel_time_t msg_ctime; /* 最后修改队列的时间 */
8. unsigned long msg_lcbytes;
9. unsigned long msg_lqbytes;
10. unsigned short msg_cbytes; /* 队列上所有消息总的字节数 */
11. unsigned short msg_qnum; /* 在当前队列上消息的个数 */
12. unsigned short msg_qbytes; /* 队列上最大的字节数 */
13. __kernel_ipc_pid_t msg_lspid; /* 发送最后一条消息的进程的 pid */
14. __kernel_ipc_pid_t msg_lrpid; /* 接收最后一条消息的进程的 pid */
15. };
3.3.2 三种系统调用
为了创建一个新的消息队列,或存取一个已经存在的队列,要使用 msgget()系统调用。
n 原型: intmsgget ( key_t key, int msgflg );
semget()中的第一个参数是键值,这个键值要与现有的键值进行比较,现有的键值指在
内核中已存在的其他消息队列的键值。对消息队列的打开或存取操作依赖于 msgflg 参数的取值。
n 系统调用:msgsnd()已知队列识别号后,可以在这个队列上执行操作。要把一条消息传递给一个队列,必须用 msgsnd()系统调用
原型:int msgsnd( int msqid, struct msgbuf *msgp, int msgsz, int msgflg);
msgsnd()的第 1 个参数是队列识别号,由 msgget()调用返回。第 2 个参数 msgp 是一个指针,指向我们重新声明和装载的消息缓冲区。msgsz 参数包含了消息以字节为单位的长度,其中包括了消息类型的 4 个字节。
msgflg 参数可以设置成 0(忽略),或者设置或 IPC_NOWAIT :如果消息队列满,消息不写到队列中,并且控制权返回给调用进程(继续执行);如果不指定 IPC_NOWAIT,调用进程将挂起(阻塞)直到消息被写到队列中。
n 系统调用:msgrcv()
原型:int msgrcv( int msqid, struct msgbuf *msgp, int msgsz, longmtype, int msgflg );
第 1 个参数用来指定要检索的队列(必须由 msgget()调用返回)
第 2 个参数(msgp)是存放检索到消息的缓冲区的地址
第 3 个参数(msgsz)是消息缓冲区的大小,包括消息类型的长度(4 字节)。
第 4 个参数(mtype)指定了消息的类型。内核将搜索队列中相匹配类型的最早的消息,
并且返回这个消息的一个拷贝,返回的消息放在由 msgp 参数指向的地址。这里存在一个特殊的情况,如果传递给 mytype 参数的值为 0,就可以不管类型,只返回队列中最早的消息。
3.4 关于共享内存
共享内存可以被描述成内存一个区域(段)的映射,这个区域可以被更多的进程所共享。由于不需要中间环节,而是把信息直接从一个内存段映射到调用进程的地址空间,因此这是 IPC 机制中最快的一种形式。当内存被共享之后,对共享内存的访问同步还需要由其他IPC 机制例如信号量来实现。像所有的 System V IPC 对象一样,Linux 对共享内存的存取是通过对访问键和访问权限的检查来控制的
3.4.1 共享内存的数据结构
与消息队列和信号量集合类似,内核为每一个共享内存段(存在于它的地址空间)维护着一个特殊的数据结构 shmid_ds,这个结构在 include/linux/shm.h 中定义如下:
1. struct shmid_ds {
2. struct ipc_perm shm_perm; /* 操作权限*/
3. int shm_segsz; /* 段的大小(以字节为单位) */
4. __kernel_time_t shm_atime; /* 最后一个进程附加到该段的时间 */
5. __kernel_time_t shm_dtime; /* 最后一个进程离开该段的时间 */
6. __kernel_time_t shm_ctime; /* 最后一次修改该结构的时间 */
7. __kernel_ipc_pid_t shm_cpid; /* 创建该共享内存段进程的pid号 */
8. __kernel_ipc_pid_t shm_lpid; /* 上一次操作该段的进程的pid号 */
9. unsigned short shm_nattch; /* 当前附加到该段的进程的个数 */
10. unsigned short shm_unused;
11. void *shm_unused2;
12. void *shm_unused3;
13. unsigned short shm_npages; /*段的大小(以页为单位) */
14. unsigned long *shm_pages; /* 指向 frames -> SHMMAX 的指针数组 */
15. struct vm_area_struct *attaches; /* 对共享段的描述 */
16. };
而表示共享内存的数据结构shmid_ds 与其他相关数据结构的关系可由下图描述
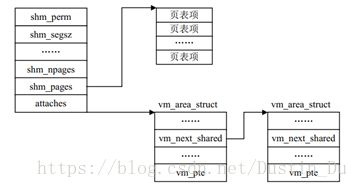
图3-5 共享内存的数据结构
3.4.2 共享内存处理过程
某个进程第 1 次访问共享虚拟内存时将产生缺页异常。这时操作系统找出描述该内存的vm_area_struct结构,该结构中包含用来处理这种共享虚拟内存段的处理函数地址。接着共享内存缺页异常处理函数对 shmid_ds 的页表项表进行搜索,以便查看是否存在该共享虚拟内存的页表项。如果没有,系统将分配一个物理页并建立页表项,该页表项加入 shmid_ds 结构的同时也添加到进程的页表中。这就意味着当下一个进程试图访问这页内存时出现缺页异常,共享内存的缺页异常处理代码则把新创建的物理页给这个进程。因此说,第 1 个进程对共享内存的存取引起创建新的物理页面,而其他进程对共享内存的存取引起把那个页添加到它们的地址空间。
3.4.3 三种系统调用
n 系统调用:shmget()
原型:int shmget ( key_t key, int size, int shmflg );
返回:成功,则返回共享内存段的识别号, 失败返回-1。
shmget()系统调用类似于信号量和消息队列的系统调用。
n 系统调用:shmat()
原型:int shmat(intshmid, char *shmaddr, int shmflg);
返回:成功,则返回附加到进程的那个段的地址,失败返回-1。
其中 shmid 是由shmget()调用返回的共享内存段识别号,shmaddr 是你希望共享段附加的地址,shmflag 允许你规定希望所附加的段为只读(利用 SHM_RDONLY)以代替读写。通常,并不需要规定你自己的 shmaddr,可以用传递参数值零使得系统为你取得一个地址。
n 系统调用:shmctl(),反映共享内存上执行控制操作的结果
原型: int shmctl ( int shmid, int cmd, struct shmid_ds *buf );
返回:成功返回 0 ,失败返回-1。
这个特殊的调用和 semctl()调用几乎相同
当一个进程不再需要共享内存段时,它将调用 shmdt()系统调用取消这个段,但是,这
并不是从内核真正地删除这个段,而是把相关 shmid_ds 结构的 shm_nattch 域的值减 1,当这个值为 0 时,内核才从物理上删除这个共享段。
四. 块设备驱动程序
对于块设备,其读写操作的基本单位为块。缓冲机制的设置减小了高速的cpu与较慢的主存读写操作之间速度不协调带来的影响,而当要读取的数据不在缓存中时,需要动用块设备驱动程序控制块设备完成数据的交换,块驱动程序作为核心内存与其他存储介质之间的管道,也可以认为是虚拟内存子系统的组成部分。
4.1 块设备驱动程序的注册
对于块设备来说,驱动程序的注册不仅在其初始化的时候进行而且在编译的时候也要进
行注册。
在该过程的关键实现函数为
int register_blkdev(unsignedint major, const char * name, struct block_device_operations
*bdops)
第 1 个参数是主设备号
第 2 个参数是设备名称的字符串
第 3 个参数是指向具体设备操作的指针
如果一切顺利则返回 0,否则返回负值。如果指定的主设备号为 0,此函数将会搜索空闲的主设备号分配给该设备驱动程序并将其作为返回值。
当块设备注册到系统后,通过fs/block_dev.c中的file_operations 结构与文件系统建立联系
1. struct file_operations def_blk_fops = {
2. open: blkdev_open,
3. release: blkdev_close,
4. llseek: block_llseek,
5. read: generic_file_read,
6. write: generic_file_write,
7. mmap: generic_file_mmap,
8. fsync: block_fsync,
9. ioctl: blkdev_ioctl,
10. };
与其对应的注销块设备驱动程序的函数是:
int unregister_blkdev(unsigned int majir, const char *name);
4.2 块设备基于缓冲区的数据交换
n 扇区和块的区别
块设备的每次数据传送操作都作用于一组相邻字节,称之为扇区。在大部分磁盘设备中,扇区的大小是 512 字节,但是现在新出现的一些设备使用更大的扇区(1024 和 2014字节)。
所谓块就是块设备驱动程序在一次单独操作中所传送的一大块相邻字节。
区别在于扇区是硬件设备传送数据的基本单元,而块只是硬件设备请求一次 I/O 操作所涉及的一组相邻字节,必须是扇区的整数倍。
n 块驱动程序的体系结构
块设备驱动程序通常分为两部分,即高级驱动程序和低级驱动程序,前者处理 VFS 层,
后者处理硬件设备
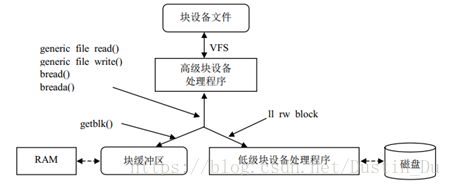
图4-1 块设备驱动程序的体系结构
有些块设备的处理程序需要自己专用的高级设备驱动程序。典型的例子是软驱的设备驱动程序:它必须检查从上次访问磁盘以来,用户有没有改变驱动器中的磁盘;如果已插入一张新磁盘,那么设备驱动程序必须使缓冲区中所包含的旧数据无效。
read和write方法通常最终还会调用generic_file_read( )和 generic_file_write ( )函数。这些函数把对 I/O 设备文件的访 问 请 求 转 换 成 对 相 应 硬 件 设 备 的 块 请 求 。 所 请 求 的 块 可 能已 在 主 存 , 因 此这两个函数调用 getblk( )函数来检查缓冲区中是否已经预取了块。如果块不在缓冲区中,getblk( )就必须调用 ll_rw_block( )继续从磁盘中读取这个块,后面这个函数激活操纵设备控制器的低级驱动程序,以执行对块设备所请求的操作。
n 块设备请求
虽然块设备驱动程序可以一次传送一个单独的数据块,但是内核并不会为磁盘上每个被访问的数据块都单独执行一次 I/O 操作,只要可能,内核就试图把几个块合并在一起,并作为一个整体来处理,这样就减少了磁头的平均移动时间。
块设备驱动程序是中断驱动的,因此,只要高级驱动程序一发出块请求,它就可以终止执行。另外每个块设备驱动程序都维护自己的请求队列,相应的策略程序可以顺序扫描这种队列,并以最少地移动磁头而为所有的请求提供服务。
每个块设备请求都是由一个request结构来描述的,其定义于 include/linux/blkdev.h
1. struct request {
2. struct list_head queue;
3. int elevator_sequence;
4.
5. volatile int rq_status; /* 定义请求的状态*/
6. #define RQ_INACTIVE (-1)
7. #define RQ_ACTIVE 1
8. #define RQ_SCSI_BUSY 0xffff
9. #define RQ_SCSI_DONE 0xfffe
10. #define RQ_SCSI_DISCONNECTING 0xffe0
11.
12. kdev_t rq_dev; /* 指定块设备*/
13. int cmd; /* 数据传送的方向 */
14. int errors;
15. unsigned long sector;
16. unsigned long nr_sectors;
17. unsigned long hard_sector, hard_nr_sectors;
18. unsigned int nr_segments;
19. unsigned int nr_hw_segments;
20. unsigned long current_nr_sectors;
21. void * special;
22. char * buffer; /* 指向实际数据传送所使用的内存区 */
23. struct completion * waiting;
24. struct buffer_head * bh; /* 请求块的所有缓冲区首部所在简单链表中的第一个元素 */
25. struct buffer_head * bhtail;
26. request_queue_t *q;
27. };
n 请求队列
请求队列只是一个简单的链表,其元素是请求描述符。每个请求描述符中的 next 域都
指向请求队列的下一个元素,最后一个元素为空。这个链表的排序通常是:首先根据设备标识符,其次根据最初的扇区号
请求队列拥有request_queue和request_queue_t结构类型。在
创建和初始化请求队列的函数是:
request_queue_t *blk_init_queue(request_fn_proc, spinlock_t *lock);
把请求队列返回给系统,需要调用以下函数void blk_cleanup_queue(reque_queue_t *);
返回队列中下一个要处理的请求的函数是:
struct requeuest *elv_next_request(request_queue_t *queue);
将请求从队列中实际删除,使用以下函数:
void blkdev_dequeue_request(struct request *req);
如果出于某些原因要将拿出队列的请求再返回给队列,使用下面的函数:
void elv_requeue_request(request_queue_t *queue, struct request *req);
4.3 块设备驱动程序的几个函数
n generic_file_read ()和generic_file_write ( )
这两个函数的原型如下:
ssize_tgeneric_file_read(struct file * filp, char * buf, size_t count, loff_t *ppos)
ssize_tgeneric_file_write(struct file *file,const char *buf,size_t count, loff_t*ppos)
其参数的含义如下。
filp:和这个设备文件相对应的文件对象的地址。
Buf:用户态地址空间中的缓冲区的地址。generic_file_read()把从块设备中读出的
数据写入这个缓冲区;反之,generic_file_write()从这个缓冲区中读取要写入块设备的数据。
Count:要传送的字节数。
ppos:设备文件中的偏移变量的地址;通常,这个参数指向filp->f_pos,也就是说,
指向设备文件的文件指针。
n ll_rw_block( )函数
ll_rw_block( )函数产生块设备请求;内核和设备驱动程序的很多地方都会调用这个函
数。该函数的原型如下:
void ll_rw_block(int rw, int nr, structbuffer_head * bhs[])
其参数的含义如下。
• 操作类型 rw,其值可以是READ、WRITE、READA 或者 WRITEA。最后两种操作类型和
前两种操作类型之间的区别在于,当没有可用的请求描述符时后两个函数不会阻塞。
• 要传送的块数 nr。
• 一个 bhs 数组,有nr 个指针,指向说明块的缓冲区首部(这些块的大小必须相同,
而且必须处于同一个块设备)。
4.4 RAM 盘驱动程序的实现
核心思想:利用预先分配的主存来存储数据块,就像普通磁盘一样来使用它。因此不存在像磁盘那样的寻道操作,其读写操作只是在内存间进行的。RAM 盘具有快速存取的优点(没有寻道和旋转延迟的时间),适合于存储需要频繁存取的数据。
实现关键:RAM 盘的驱动程序
由一组函数组成,对 RAM盘的操作实际上是对内存的操作,它不需要中断机制,故 RAM 盘的驱动程序不包括中断服务子程序。
关于RAM 盘操作的结构:
1. s static struct block_device_operations rd_bd_op = {
2. owner: THIS_MODULE,
3. open: rd_open,
4. ioctl: rd_ioctl,
5. };
在 Linux 中,RAM 盘的主设备号是 1。在rd_open ( ) 函数中,它首先检测设备号
INITRD_MINOR,由于 INITRD 是在系统一启动的时候就已经创建,其中映像的是操作系统从偏移地址 0 开始的内容,即内核空间,如果是内核空间,其接口需要相应的发生变换即:filp->f_op= &initrd_fops
1. static struct file_operations initrd_fops = {
2. read: initrd_read,
3. release: initrd_release,
4. };
对于 INITRD 盘的操作用户只有读和释放的权限而无写的权限。initrd_read ( ) 函数
执 行 的 是 从 内 核 区 进 行 的 读 操 作 , 故 而 是 利 用 memcpy_tofs (buf , (char*)initrd_start+file->f_pos,count ) 去完成的。initrd_release ( ) 函数在判断没有用户操作这个设备之后,以页的方式把INITRD 盘所占的内存释放掉。
4.5 磁盘驱动程序的实现
对于硬盘的很大一部分工作,由硬盘控制器就可以完成。而对于软盘来说,其控制器则简单得多,通过编程去完成各种功能,这样软盘驱动程序就变得比较复杂。
Linux 中,硬盘被认为是计算机的最基本的配置,所以在装载内核的时候,硬盘驱动程
序必须就被编译进内核,不能作为模块编译。硬盘驱动程序提供内核的接口为:
1. static struct block_device_operations hd_fops = {
2. open: hd_open,
3. release: hd_release,
4. ioctl: hd_ioctl,
5. };
对硬盘的操作只有 3 个函数。对于hd_open ( ) 和 hd_release ( ) 函数,打开操作首先检测了设备的有效性,接着测试了它的忙标志,最后对请求硬盘的总数加 1,来标识对硬盘的请求个数,hd_release ( ) 函数则将请求的总数减 1。
事实上对于块设备的读写操作是先对缓冲区操作,但是当需要真正同硬盘交换数据的时候,驱动程序也做了大量的工作。在 hd.c 中有一个函数 hd_out ( ) ,它在实际的数据交换中起着主要的作用。它的原形是:
1. static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect,
2. unsigned int head,unsigned int cyl,unsigned int cmd;
3. void (*intr_addr)(void));
其中参数 drive 是进行操作的设备号;nsect 是每次读写的扇区数;sect 是读写的开
始扇区号;head 是读写的磁头号;cmd 是操作命令控制命令字。
通过这个函数向硬盘控制器的寄存器中写入数据,启动硬盘进行实际的操作。同时这个
函数也配合完成 cmd 命令相应的中断服务子程序,通过 SET_INIT(intr_addr) 宏定义将其地址赋给 DEVICE_INTR。
hd_request () 函数就是通过这个函数进行实际的数据交换,同其他驱动程序不同的是
该函数还要根据每个命令的不同来确定一些参数,最基本的是读写方式的确定,关于硬盘的读写方式有两种,一种是单扇区的读写,另一种是多扇区的读写,单扇区的读写是指每次操作只对一个扇区操作,而多扇区则指每次对多个扇区进行操作,不同的方式其中断服务子程序不同,其相应的地址就作为参数传给 hd_out ( ) ,由它设置 DEVICE_INIT。hd_request( )函数确定的其他参数也就是 hd_out()所需要的参数。
五. 套接字(socket)
5.1 套接字简介
为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了称为套接字(Socket)的接口。套接字实质上就是支持TCP/IP网络通信的基本操作单元,是我们进行TCP/IP进行通信的接口。
linux以文件的形式实现套接口,与套接口相应的文件属于sockfs特殊文件系统,创建一个套接口就是在sockfs中创建一个特殊文件,并建立起为实现套接口功能的相关数据结构。换句话说,对每一个新创建的套接字,linux内核都将在sockfs特殊文件系统中创建一个新的inode。
操作系统区分不同应用程序进程间的网络通信和连接,主要有3个参数:通信的目的IP地址、使用的传输层协议(TCP或UDP)和使用的端口号:
5.2 套接字接口类型
Linux 支持多种套接字种类,不同的套接字种类称为“地址族”,这是因为每种套接字
种类拥有自己的通信寻址方法。
表5-1 Linux 支持的套接字地址族

Linux 将上述套接字地址族抽象为统一的 BSD 套接字接口,应用程序关心的只是 BSD 套接字接口,而 BSD 套接字由各地址族专有的软件支持。一般而言,BSD 套接字可支持多种套接字类型,不同的套接字类型提供的服务不同。
表5-2 Linux 所支持的 部分BSD 套接字类型
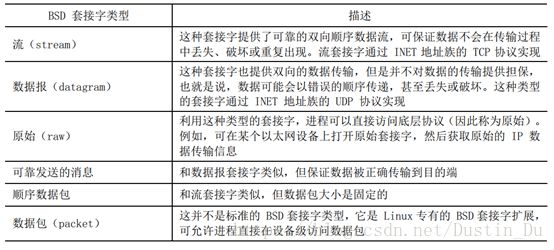
5.3 套接字工作原理
以INET 套接字地址族、流套接字类型为例,概括套接字的工作原理和通信过程。INET 套接字是支持Internet 地址族的套接字,它位于 TCP 之上,BSD 套接字之下,其INET 和BSD 套接字之间的接口通过 Internet 地址族套接字操作集实现,这些操作集实际是一组协议的操作例程,在 include/linux/net.h 中定义为 proto_ops,这个操作集类似于文件系统中的 file_operations 结构。BSD 套接字层通过调用proto_ops 结构中的相应函数执行任务。BSD 套接字层向 INET 套接字层传递 socket 数据结构来代表一个 BSD 套接字,socket 结构在include/linux/net.h 中定义如下:
1. struct socket
2. {
3. socket_state state;
4. unsigned long flags;
5. struct proto_ops *ops;
6. struct inode *inode;
7. struct fasync_struct *fasync_list; /* Asynchronous wake up list */
8. struct file *file; /* File back pointer for gc */
9. struct sock *sk;
10. wait_queue_head_t wait;
11. short type;
12. unsigned char passcred;
13. };
但在 INET 套接字层中,它利用自己的 sock 数据结构来代表该套接字,因此,这两个
结构之间存在着链接关系,sock 结构定义于 include/net/sock.h(此结构有 80 多行,在此不予列出)。在 BSD 的 socket 数据结构中存在一个指向 sock 的指针 sk,而在 sock中又有一个指向 socket 的指针,这两个指针将 BSDsocket 数据结构和 sock 数据结构链接了起来。实际上,sock 数据结构可适用于不同的地址族,它也定义有自己的协议操作集 proto。在建立套接字时,sock数据结构的协议操作集指针指向所请求的协议操作集。如果请求 TCP,则 sock 数据结构的协议操作集指针将指向 TCP 的协议操作集。
进程在利用套接字进行通信时,采用客户/服务器模型。服务器首先创建一个套接字,并将某个名称绑定到该套接字上,套接字的名称依赖于套接字的底层地址族,但通常是服务器的本地地址。对于 INET 套接字来说,服务器的地址由两部分组成,一个是服务器的 IP 地址,另一个是服务器的端口地址。
BSD 套接字上的详细操作与具体的底层地址族有关,底层地址族的不同实际意味着寻址方式、采用的协议等的不同。Linux 利用 BSD 套接字层抽象了不同的套接字接口。在内核的初始化阶段,内建于内核的不同地址族分别以 BSD 套接字接口在内核中注册。然后,随着应用程序创建并使用 BSD 套接字。
5.4 通信过程
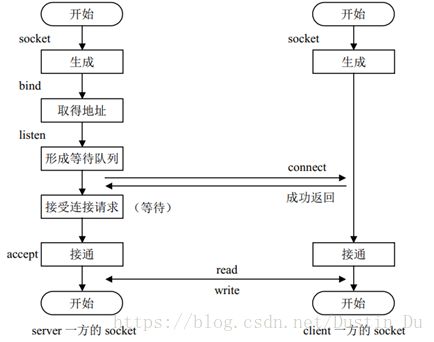
图5-1 socket 的通信过程

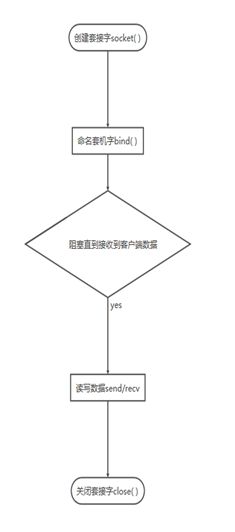
图5-2 TCP服务器端通信过程 图5-3 UDP服务器端通信过程
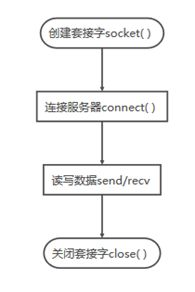

图5-4 TCP客户端通信过程 图5-5 UDP客户端通信过程
5.5 socket操作系统调用
在应用层和协议无关层之间,是一个系统调用接口层。系统调用接口如下:
表5-3 Socket系统调用
类型 |
功能 |
socketcall |
socket系统调用 |
socket |
建立socket |
bind |
绑定socket到端口 |
Connect |
连接远程主机 |
accept |
响应socket连接请求 |
send |
通过socket发送信息 |
sendto |
发送UDP信息 |
recv |
通过socket接收信息 |
recvfrom |
接收UDP信息 |
listen |
监听socket端口 |
select |
对多路同步I/O进行轮询 |
shutdown |
关闭socket上的连接 |
getsockname |
取得本地socket名字 |
getpeername |
获取通信对方的socket名字 |
getsockopt |
取端口设置 |
setsockopt |
设置端口参数 |
sendfile |
在文件或端口间传输数据 |
socketpair |
创建一对已联接的无名socket |
当在应用中调用socket()函数时,就会触发系统调用,跟socket相关的操作函数都会被映射到sys_socketcall的系统调用中,对于32位系统在文件unistd_32.h中有其系统调用号表。对于64位系统,系统调用号表在unistd_64.h中,跟socket相关的系统调用会直接对应。
总结
linux下的进程通信手段基本上是从Unix平台上的进程通信手段继承而来的。而对Unix发展做出重大贡献的两大主力AT&T的贝尔实验室及BSD(加州大学伯克利分校的伯克利软件发布中心)在进程间通信方面的侧重点有所不同。
前者对Unix早期的进程间通信手段进行了系统的改进和扩充,形成了“system V IPC”,通信进程局限在单个计算机内;
而后者则跳过了该限制,形成了基于套接口(socket)的进程间通信机制。
而Linux系统则把两者继承了下来。进程通信手段的发展阶段可总结为:
- 早期UNIX进程间通信
- 基于System V进程间通信
- 基于Socket进程间通信
- POSIX进程间通信。
UNIX进程间通信方式包括:管道、FIFO、信号。
System V进程间通信方式包括:SystemV消息队列、System V信号灯、System V共享内存
POSIX进程间通信包括:posix消息队列、posix信号灯、posix共享内存。
进程间通信各种方式效率比较
类型 |
无连接 |
可靠 |
流控制 |
记录消息类型 |
优先级 |
普通PIPE |
N |
Y |
Y |
|
N |
流PIPE |
N |
Y |
Y |
|
N |
命名PIPE(FIFO) |
N |
Y |
Y |
|
N |
消息队列 |
N |
Y |
Y |
|
Y |
信号量 |
N |
Y |
Y |
|
Y |
共享存储 |
N |
Y |
Y |
|
Y |
UNIX流SOCKET |
N |
Y |
Y |
|
N |
UNIX数据包 SOCKET |
Y |
Y |
N |
|
N |