Python爬虫学习之爬美女图片
最近看机器学习挺火的,然后,想要借助业余时间,来学习Python,希望能为来年找一份比较好的工作。
首先,学习得要有动力,动力,从哪里来呢?肯定是从日常需求之中来。我学Python看网上介绍。能通过Python来编写爬虫,于是,我也的简单的看了一下Python的介绍,主要是Python的一些语法,还有正则表达式。
好了,学习使用Python之前,来给大家看一下我们需要进行爬去的网站: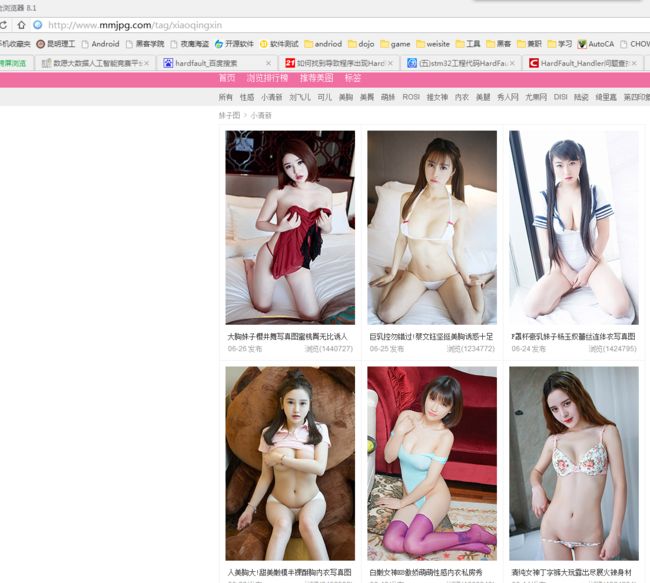
看到这个网站,感谢美女很养眼的同时,网站的图片也不太过,就是比较性感而已。看到这个多的美女,你想不想要将这些爬取到的美女,保存在你的硬盘,或者保存在你的网站,增加流量呢?
好了,目标网站有了,接下来,我们直接真刀真枪的直接开干吧。
考虑到,有很多和我一样的小白,我暂时,不介绍使用Pyspider来做爬虫,我们就使用Python的一些库来做爬虫,一步一步的进阶。
接下来需要大家安装一个IDE来编写Python脚本,我给大家推荐Pycharm编辑器。
恩,接下来直接上代码了,做好准备了没?
第一步:解析美女类别:
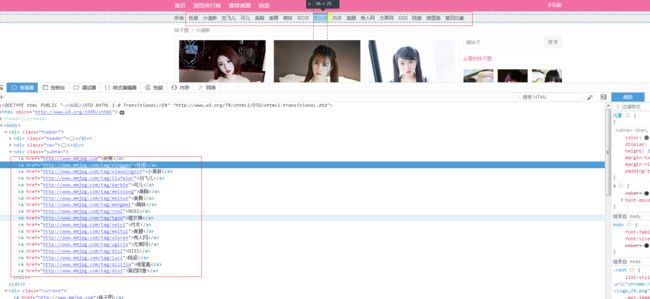
if __name__ == "__main__": # page = 8 url = "http://www.mmjpg.com/" base_url = urlparse(url) #url = "http://cuiqingcai.com/1319.html" #menu = getallAltls(url) ##menu = getparAltls(url, page) #url = "http://www.mmjpg.com/tag/tgod" path = r"E:\image" #path = path + "\\" + "推女神" craw = Crawler() soup = craw.doc(craw.getHtml(url)) total = 0 for each in soup(soup(".subnav")('a[href^="http://www.mmjpg.com/tag"]')).items(): utils.log( "即将下载: " + each.text() + each.attr('href') ) path= r"E:\image" path = path + "\\" + each.text() utils.log( "即将存放在:" + path ) total += 1 if total<=11: # continue pass else: param={"url":each.attr('href'),"path":path} craw.downimgofsite(param )
第二步:下载站点某图集下的所有图片:
def downimgofsite(self , param): url = "" path = "" #path = str(path) if param and "url" in param: url = param["url"] utils.log( "即将下载:" + url) else: utils.log( "线程运行错误,url为空") return if param and "path" in param: path = param["path"] utils.log( "即将保存路径:" + path) else: utils.log( "线程运行错误,路径为空" ) return #获取所有图集的名称和链接 meun_list = self.getallAltls(url) total = 0 directorypath = "" #print os.getcwd() try: for meun in meun_list: try: directoryname = self.str_fomat(meun[0]) if not directoryname: utils.log("获取到的图集为空" + str(directoryname)) continue if path.strip() != "": directorypath = path + "\\" + directoryname else: directorypath = os.getcwd() + "\\" + directoryname if not os.path.exists(directorypath): os.makedirs(directorypath) utils.log( "图集 "+ meun[0]+ " 创建路径:" + directorypath ) utils.log("正在下载第 "+ str(total) + "个图集:" + meun[0] + " 链接:" + url) result = self.getSinglePic(meun[1], directorypath) total += 1 except IOError, param: utils.log("图集:"+ meun[0] +"IO读写错误,原因"+ param) continue except BaseException,param: utils.log("图集:"+ meun[0] + "产生意外错误") continue except: utils.log("图集:"+ meun[0] + "产生意外错误,原因:" + param) continue try: if result: utils.log( "图集:" + meun[0] + " 获取链接:" + meun[1] +" 成功,共下载:" + str(result) + " 张图片" ) else: os.rmdir(directorypath) utils.log( "图集:" + meun[0] + " 获取链接:" + meun[1] +" 失败,即将删除目录:" + directoryname ) #self.cleanDir(directorypath) except WindowsError,parm: utils.log( "操作目录:"+ directoryname + "失败,原因:"+ parm ,logging.ERROR) continue except BaseException,parm: utils.log( "发生错误,错误原因:"+ parm ,logging.ERROR) continue except: utils.log( "发生未知错误" ,logging.ERROR) continue except BaseException,parm: utils.log( "下载站点图片出错,错误原因:" + parm ,logging.ERROR)
获取所有图集:
#function获取所有的图集名称 def getallAltls(self,url): html =self.getHtml(url) if not html: utils.log("获取网页:"+ url +"错误,错误原因:没有获取到网页") return None soup = self.bfs(html) totalpage = int(self.getPageNum(html ,url)) meun = self.getPicNameandLink(url) album_id = re.search( r'\d+', url, re.M|re.I) if not album_id: album_id = str(int(random.random() * 10000)) albm_url = url album_create_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) album_name = soup.find("div",class_="current").find("i").string #循环遍历所有的图集页面,获取图集名称和链接 for pos in range(2,totalpage+1): currenturl = url + "/" + str(pos) #getPicNameandLink()返回的值是一个list。 #当一个list插入到另一个list中时,使用extend。 #若是插入一个值时,可以用append tmenu = self.getPicNameandLink(currenturl) if tmenu: meun.extend(tmenu) utils.log("从链接:" + url +"获取到" + str(len(tmenu)) + "链接") else: utils.log("获取链接:"+ url + "图集失败") # url = nextpage = self.getNextPage(url) # meun.extend(self.getPicNameandLink(nextpage)) return meun
获取整个图集的所有页码:
# 获取整个图集的页码 def getPageNum(self , html , url): soup = self.bfs( html) # 直接在站点首页获取所有图集的总页码 #nums=soup.find_all('a',class_='page-numbers') # 除掉“下一页”的链接,并获取到最后一页 #totlePage = int(nums[-2].text) p = r'共\d+?页' #print soup.get_text() pa = re.compile(p.encode('utf-8')) match = re.search(pa, soup.get_text().encode("utf-8")) if match: ct = re.sub(r'\D','', match.group(0)) if not ct: utils.log( "链接: "+ url + " 页面共:" +"0" + "页,总页面查找失败" ) return 1 utils.log( "链接: "+ url + " 页面共:" + str(ct) + "页") totlePage = int(ct) print totlePage return totlePage else: utils.log( "链接: "+ url + " 页面共:" +"0" + "页,总页面查找失败" ) return 1
获取指定图集下图集名称和链接:
#获取指定页面下图集名称和链接 def getPicNameandLink(self , url): html = self.getHtml(url) if html: soup = self.bfs( html) else: utils.log("链接:" + url + " 请求失败" + "网页:") utils.log(str(html)) return None soup = self.bfs(html) meun = [] total = 1 link_list = soup.find("div", class_="pic").find_all('a' ,target="_blank") #+ soup.find_all('img' ,target="_blank") #print type(link_count) link_count = len(link_list) #print type(link_count) utils.log("在链接:"+ url+ "下找到: "+ str(link_count) + " 链接") if(link_count > 0): for pic in link_list: link = pic["href"] self.links.append(link) picturename = "" img = pic.find("img") if img: # 保证中文字符能够正常转码。 picturename = unicode(str(img["alt"])) self.title.append(picturename) else: continue #插入图集名称和对应的url meun.append([picturename,link]) ids=self.get_url_page(url) if ids: self.ids.append(ids) else: self.ids.append(total) total += 1 utils.log( "在链接:" + url +" 下实际找到:" + str(len(meun)) + "个链接") return meun else: return None
获取下一页:
#获取下一页的链接 def getNextPage(self , url): base_url = urlparse(url) html = self.getHtml(url) if html: soup = self.bfs( html) else: utils.log("链接:" + url + " 请求失败" + "网页:") utils.log(html) return None nt = "下一页" next_url = soup.find_all('a',text=nt) ret_url= next_url[0]['href'] #print ret_url if ret_url: try: if re.match(r'^https?:/{2}\w.+$', ret_url): utils.log( "获取到正确的网址:" + ret_url) return ret_url else: ret_url = base_url.scheme +"://"+ base_url.netloc + next_url[0]['href'] utils.log("只获取到查询路径,处理之后网址为:"+ ret_url) return ret_url except BaseException, Argument: utils.log("查找下一页出错,错误为:"+Argument ,logging.ERROR) return None else: print "获取下一页地址失败!" return None
第三部:获取某一个妹子的所有图片:
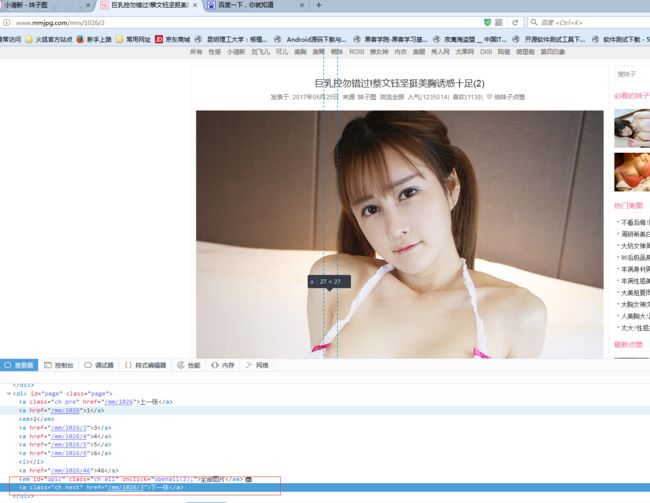
#下载单个相册中的所有图片 def getSinglePic(self , url , path): title = re.split(r'\\', path) title = title[-1] try: page_url = self.getSinglePicUrl(url) if page_url: totalPageNum = self.getSinglePicTotal(url) base_url = urlparse(url) real_url =base_url.scheme+"://"+base_url.netloc #从第一页开始,下载单个图集中所有的图片 #range()第二个参数是范围值的上限,循环时不包括该值 #需要加1以保证读取到所有页面。 p = r'.+\/' pa = re.compile(p) #print title if totalPageNum: for i in range(1,totalPageNum + 1): currenturl = real_url + "/" + str(i) self.downloadpic(currenturl,path) else: next_url = self.getSinglePicUrl(url) cur_page = 1 utils.log("即将下载图集:" + title) while next_url: match = re.search(pa, next_url).group(0) if match: currenturl = real_url+ "/" + match + str(cur_page) else: currenturl = real_url+ "/" + next_url # + str(cur_page) #utils.log("正在下载: "+ str(cur_page) + " 个图片:" +" 链接:"+ url ) self.downloadpic(currenturl,path) cur_page += 1 next_url = self.getSinglePicUrl(currenturl) #判断是否还有下一页 # if cur_page > 2: # return cur_page return (cur_page-1) else: utils.log( "图集:"+ title+ "链接:" + url +" 获取图片链接失败") return None except BaseException,param: utils.log( "下载单个相册:" + title + " 链接:" + url+ "中的所有图片异常,原因:" + param ,logging.ERROR) return None except: utils.log( "下载单个相册:" + title + " 链接:" + url+ "中的所有图片异常" ,logging.ERROR) return None
#获取单个相册内图片链接 def getSinglePicUrl(self , url): html = self.getHtml(url) if html: soup = self.bfs( html) else: utils.log("链接:" + url + " 请求失败" + "网页:") utils.log(html) return None try: if soup: #print "当前页面链接:"+ url nt = "下一张" next_url = soup.find_all('a',text=nt) if next_url: ret_url= next_url[0]['href'] else: return None else: utils.log( "网页" + url + "读取失败") return None except BaseException,param: utils.log( "获取单个相册内图片链接异常,原因" + param ,logging.ERROR) return None return ret_url
获取图片数量:
#获取单个相册内图片所有图片的数量 def getSinglePicTotal(self , url): html = self.getHtml(url) if html: soup = self.bfs( html) else: utils.log("链接:" + url + " 请求失败" + "网页:") utils.log(html) return None #pagenavi还是一个对象(Tag),可以通过find_all找出指定标签出来 #print "当前页面链接:"+ url if soup: #print "获取链接:"+url +" 成功" pass else: utils.log("获取链接:"+url +" 失败") return None nt = "全部图片" try: total = soup.find_all('a',text=nt) if total: total= re.sub('\D',"",total[0]['href']) else: total = 0 except BaseException,param: utils.log( "获取单个相册内图片所有图片的数量异常,原因" + param , logging.ERROR) return None return total
第四步:下个单个相册的所有图片:
#下载单个相册中的所有图片 def getSinglePic(self , url , path): title = re.split(r'\\', path) title = title[-1] try: page_url = self.getSinglePicUrl(url) if page_url: totalPageNum = self.getSinglePicTotal(url) base_url = urlparse(url) real_url =base_url.scheme+"://"+base_url.netloc #从第一页开始,下载单个图集中所有的图片 #range()第二个参数是范围值的上限,循环时不包括该值 #需要加1以保证读取到所有页面。 p = r'.+\/' pa = re.compile(p) #print title if totalPageNum: for i in range(1,totalPageNum + 1): currenturl = real_url + "/" + str(i) self.downloadpic(currenturl,path) else: next_url = self.getSinglePicUrl(url) cur_page = 1 utils.log("即将下载图集:" + title) while next_url: match = re.search(pa, next_url).group(0) if match: currenturl = real_url+ "/" + match + str(cur_page) else: currenturl = real_url+ "/" + next_url # + str(cur_page) #utils.log("正在下载: "+ str(cur_page) + " 个图片:" +" 链接:"+ url ) self.downloadpic(currenturl,path) cur_page += 1 next_url = self.getSinglePicUrl(currenturl) #判断是否还有下一页 # if cur_page > 2: # return cur_page return (cur_page-1) else: utils.log( "图集:"+ title+ "链接:" + url +" 获取图片链接失败") return None except BaseException,param: utils.log( "下载单个相册:" + title + " 链接:" + url+ "中的所有图片异常,原因:" + param ,logging.ERROR) return None except: utils.log( "下载单个相册:" + title + " 链接:" + url+ "中的所有图片异常" ,logging.ERROR) return None
下载图片的重点来了:
#下载单个相册中的所有图片 def getSinglePic(self , url , path): title = re.split(r'\\', path) title = title[-1] try: page_url = self.getSinglePicUrl(url) if page_url: totalPageNum = self.getSinglePicTotal(url) base_url = urlparse(url) real_url =base_url.scheme+"://"+base_url.netloc #从第一页开始,下载单个图集中所有的图片 #range()第二个参数是范围值的上限,循环时不包括该值 #需要加1以保证读取到所有页面。 p = r'.+\/' pa = re.compile(p) #print title if totalPageNum: for i in range(1,totalPageNum + 1): currenturl = real_url + "/" + str(i) self.downloadpic(currenturl,path) else: next_url = self.getSinglePicUrl(url) cur_page = 1 utils.log("即将下载图集:" + title) while next_url: match = re.search(pa, next_url).group(0) if match: currenturl = real_url+ "/" + match + str(cur_page) else: currenturl = real_url+ "/" + next_url # + str(cur_page) #utils.log("正在下载: "+ str(cur_page) + " 个图片:" +" 链接:"+ url ) self.downloadpic(currenturl,path) cur_page += 1 next_url = self.getSinglePicUrl(currenturl) #判断是否还有下一页 # if cur_page > 2: # return cur_page return (cur_page-1) else: utils.log( "图集:"+ title+ "链接:" + url +" 获取图片链接失败") return None except BaseException,param: utils.log( "下载单个相册:" + title + " 链接:" + url+ "中的所有图片异常,原因:" + param ,logging.ERROR) return None except: utils.log( "下载单个相册:" + title + " 链接:" + url+ "中的所有图片异常" ,logging.ERROR) return None
第五步:下载图片:
def Schedule(a,b,c): ''''' a:已经下载的数据块 b:数据块的大小 c:远程文件的大小 ''' per = 100.0 * a * b / c if per > 100 : per = 100 print '%.2f%%' % per def auto_down(self, url , filename): file_dir = os.path.split(filename )[0] if os.path.isdir(file_dir): pass else: utils.log("目录:" + file_dir +"不存在,将重新创建该目录,用于下载文件:"+ filename) os.makedirs(file_dir) urllib.urlretrieve(url,filename ,Schedule)
接下来需要判断,图片是否存在,以及删除文件为空的文件夹:
#判断文件是否存在 def file_exists(self,filename): try: with open(filename) as f: return True except IOError: return False #删除空目录 def cleanDir( dir ): try: if os.path.isdir( dir ): files = os.listdir(dir) # 获取路径下的子文件(夹)列表 if files: utils.log( "找到:" +dir+"下共:" + str(len(files)) +" 文件或文件夹") else: dir= dir+"\\" files = os.listdir(dir) # 获取路径下的子文件(夹)列表 utils.log( "找到:" + dir +"下" +str(len(files)) +"文件或文件夹") for file in files: print '扫描路径:'+ file.decode('GBK') if os.path.isdir(file): # 如果是文件夹 if not os.listdir(file): # 如果子文件为空 os.rmdir(file) # 删除这个空文件夹 utils.log( file.decode('GBK') + " 文件夹为空,即将删除" ) elif os.path.isfile(file): # 如果是文件 if os.path.getsize(file) == 0: # 文件大小为0 os.remove(file) # 删除这个文件 utils.log( file.decode('GBK')+"文件为空,即将删除" ) except BaseException,param: utils.log( "扫描路径"+ dir + "异常,原因:" + str(param) ,logging.ERROR ) utils.log( "扫描路径"+ dir + " 结束")
好了,大工告成,让我们取旁边喝一杯,稍微等一会,就有大大的惊喜。

好了,这次的分享,到这里结束了,完整的源代码大家可以加入QQ群: 98556420,获取。
下一期,我也将会和大家分享使用人脸识别,来识别这些妹子。。。