人工智能搜索算法(深度优先、迭代加深、一致代价、A*搜索)
搜索算法问题求解
一、需求分析
分别用深度优先、迭代加深、一致代价、A*搜索算法得到从起始点Arad到目标点Bucharest的一条路径,即为罗马尼亚问题的一个解,在求解的过程中记录每种算法得到的解,即输出每种解得到的条路径。

图一:罗马尼亚地图
二、详细代码
测试类:
/**Main类,打印各个算法的结果
* @author dyl
*
*/
classMain{
int result;
int xiabiao[]=null;//访问的下标
publicstaticvoid main(String[] args){
Graph graph=newGraph();
System.out.println("----------------罗马尼亚问题---------------");
System.out.println("1、深度优先搜索");
DFS dfs=new DFS();
dfs.DF_Search(graph,0,12);
System.out.println("2、迭代加深的搜索");
IDS ids=new IDS();
ids.IDS_Search(graph,0,12,15);//深度设15
System.out.println("3、一致代价搜索");
UCS ucs=new UCS(graph,0,12);
System.out.println("4、A*搜索");
AXing aXing=newAXing();
aXing.A_Search(graph, graph.H,0,15);//0-15即Arad到达Hirsova
}
/**打印
* @param g:图
* @param stack:栈
*/
publicvoid show(Graph g,Stack stack){
if(stack.size()==0){
System.out.println("路径搜索失败");
return;
}
result=0;
System.out.print("访问的下标: ");
for(int i =0; i < stack.size(); i++){
System.out.print("-->"+stack.get(i));
}
System.out.print("\n访问过程: ");
xiabiao=newint[stack.size()];
if(stack.isEmpty()){
System.out.println("搜索失败");
}else{
for(int i =0; i < stack.size(); i++){
System.out.print("-->"+g.cities[(Integer) stack.get(i)]);
}
for(int i =0; i < stack.size()-1; i++){
result+=g.path[(Integer) stack.get(i)][(Integer) stack.get(i+1)];
}
System.out.println("\n总长度为:"+result+"\n");
g.markInit();//清空访问
}
}
}
/**图类
* @author dyl
*
*/
publicclassGraph{
publicint path[][]=newint[][]{{0,75,10000,118,140,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{75,0,71,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{10000,71,0,10000,151,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{118,10000,10000,0,10000,111,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{140,10000,151,10000,0,10000,80,99,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,111,10000,0,10000,10000,70,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,80,10000,0,10000,10000,10000,146,97,10000,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,99,10000,10000,0,10000,10000,10000,10000,211,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,10000,70,10000,10000,0,75,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,10000,10000,75,0,120,10000,10000,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,146,10000,10000,120,0,138,10000,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,97,10000,10000,10000,138,0,101,10000,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,10000,211,10000,10000,10000,101,0,90,85,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,90,0,10000,10000,10000,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,85,10000,0,98,10000,142,10000,10000},
{10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,98,0,86,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,86,0,10000,10000,10000},
{10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,142,10000,10000,0,92,10000},
{10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,92,0,87},
{10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,10000,87,0}};
publicint[]H=newint[]{516,524,530,479,403,394,343,326,391,392,310,160,150,155,100,0};//启发式函数
publicString[] cities=newString[]{"Arad","Zerind","Oradea","Timisoara","Sibiu","Lugoj",
"Rimnicu Vilcea","Fagaras","Mehadia","Drobeta","Craiova","Pitesti","Bucharest","Giurgiu","Urziceni","Hirsova",
"Eforie","Vaslui","Isi","Neamt"};//城市名
publicint[]mark=newint[20];//访问标记
publicGraph(){//得到数据
markInit();
}
/**
* 访问标志初始化
*/
publicvoid markInit(){
for(int i =0; i < mark.length; i++){
mark[i]=0;
}
}
/**第一个孩子
* @param g
* @param start
* @return -1表示一个孩子都没有
*/
publicint getFirstVex(int start){
if(start>=0&&start<path.length){
for(int j =0; j < path.length; j++)
if(path[start][j]<10000&&path[start][j]>0)//有关系
return j;
}
return-1;
}
/**下一个孩子
* @param start
* @param w
* @return 表示图G中顶点i的第j个邻接顶点的下一个邻接顶点
* 返回-1,表示后面没有邻接点了
*/
publicint getNextVex(int start,int w){
if(start>=0&&start<path.length&&w>=0&&w<path.length){
for(int i = w+1; i < path.length; i++)
if(path[start][i]<10000&&path[start][i]>0)
return i;
}
return-1;
}
publicint getNumber(){
return path.length;
}
}
基本原理:深度优先搜索采用堆栈寻找路径,首先从Arad结点出发,判断是否为目标结点,若否,寻找与该结点的邻接点,先搜索一条分支上的所有节点,然后再去搜索和Arad的其它分支结点,找出并存进待扩展结点表,等待扩展,每次先判断待扩展结点表是否为空,若否,则从待扩展结点表中取出一个结点进行扩展,并将扩展后的结点存进该表,若是,则返回失败。
深度优先搜索类:
/**深度优先搜索类
* @author dyl
*
*/
publicclass DFS {
Stack stack=newStack<Integer>();
int x;
int w;//v0的第一个邻接点
/**深度优先搜索--非递归式
* @param g :图
* @param v0:开始节点
* @param vg:最终节点
*/
publicvoid DF_Search(Graph g,int v0,int vg){
stack.push(v0);//入栈
g.mark[v0]=1;//v0被访问
while(true){
x=(Integer) stack.peek();//查看栈顶元素
w=g.getFirstVex(x);
while(g.mark[w]==1){//被访问,则寻找下一个邻接点
w=g.getNextVex(x, w);
if(w==-1){
break;
}
}
while(w==-1){//没有找到下一个邻接点
stack.pop();
x=(Integer) stack.peek();
w=g.getFirstVex(x);
while(g.mark[w]==1){
w=g.getNextVex(x, w);
if(w==-1){
break;
}
}
}
stack.push(w);
g.mark[w]=1;
if(w==vg)break;//到达终点
}
newMain().show(g, stack);
}
}
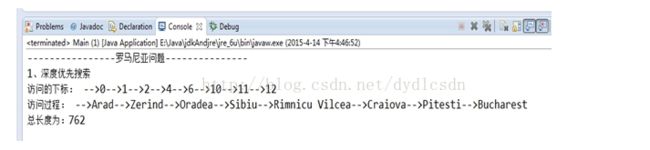
实验分析:
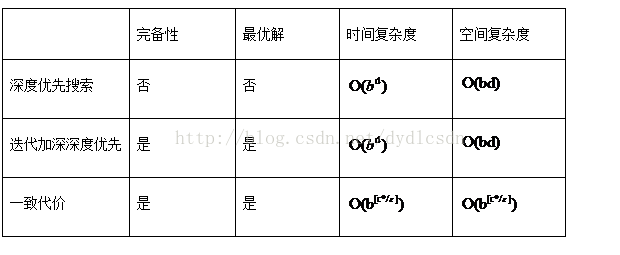
根据结果可只知,在有限状态空间下,树搜索不是完备的,图搜索完备;无限状态下不完备。此结果0->1->2->4->6->10->11->12只是其中一条,但不是最优解。
分支因子b,深度d。则最坏情况下时间复杂度也高达,空间复杂度 ,内存需求少。
l 【迭代加深】
基本原理:
迭代加深搜索是以DFS为基础的,它限制DFS递归的层数。
迭代加深搜索的基本步骤是:
1、设置一个固定的深度depth,通常是depth = 1,即只搜索初始状态
2、DFS进行搜索,限制层数为depth,如果找到答案,则结束,如果没有找到答案 则继续下一步
3、如果DFS途中遇到过更深的层,则++depth,并重复2;如果没有遇到,说明搜 索已经结束,没有答案
/**迭代加深
* @author dyl
*/
publicclass IDS {
Stack stack=newStack<Integer>();
/**迭代加深搜索
* @param g:图
* @param v0:开始节点
* @param vg:目的节点
* @param depthMax:depthMax
*/
publicvoid IDS_Search(Graph g,int v0,int vg,int depthMax){
for(int i =2; i <=depthMax; i++){//迭代depthMax次
if(dfsearch(g, v0, vg,i)==1){
break;
}
}
}
/**深度搜索
* @param g:图
* @param v0:开始节点
* @param vg:目的节点
* @param depthMax:depthMax
* @return
*/
publicint dfsearch(Graph g,int v0,int vg,int depthMax){
int x;
int w;//v0的第一个邻接点
stack.push(v0);//入栈
g.mark[v0]=1;//v0被访问
while(true){
x=(Integer) stack.peek();//查看栈顶元素
w=g.getFirstVex(x);
while(g.mark[w]==1){//被访问,则寻找下一个邻接点
w=g.getNextVex(x, w);
if(w==-1){
break;
}
}
while(w==-1){//没有找到下一个邻接点
stack.pop();
if(stack.size()==0){//清空了栈里的元素
g.markInit();//访问初始化
return0;
}
x=(Integer) stack.peek();
w=g.getFirstVex(x);
while(g.mark[w]==1){
w=g.getNextVex(x, w);
if(w==-1){
break;
}
}
}
stack.push(w);
g.mark[w]=1;
if(w==vg)
{
break;
}//检查是否达到终点
if(stack.size()>=depthMax){//重新迭代则重新初始化值
stack.pop();
}
}
newMain().show(g, stack);
return1;
}
}
实验结果:

实验分析:
因为迭代加深是从按照深度的递增搜索的,所以说0-》1-》2-》4-》7-》12这条 路径,只是在深度最低的情况下找到的结果,并不是最优解。是完备的,时间复杂度也 高达,空间复杂度。
l 【一致代价】
基本原理:
扩展的是路径消耗g(n)最小的节点n,用优先队列来实现,对解的路径步数不关心,只关心路径总代价。即使找到目标节点也不会结束,而是再检查新路径是不是要比老路径好,确实好,则丢弃老路径。
/**
* 一致代价类
*
*/
publicclass UCS {
public UCS(Graph g,int start,int end){
int[] pre =newint[20];// 保存各个结点的前驱结点
int[] dist =newint[20];// 用于保存当前结点到起始结点的实际路径长度
for(int i =0; i < pre.length; i++)
{
pre[i]=-1;
dist[i]=10000;
}
// 调用一致搜索算法搜索路径
UC_search(g,start, end, dist, pre);
// 打印路径显示函数
displayPath(start, end, pre,g);
}
/**
* @param start:开始
* @param goal:目的
* @param prev:前驱节点
* @param g:图
*/
publicvoid displayPath(int start,int goal,int[] prev,Graph g)
{
Stack<Integer> stack =newStack<Integer>();
stack.push(goal);
while(prev[goal]!= start)
{
stack.push(prev[goal]);
goal = prev[goal];
}
stack.push(start);
System.out.print("访问的下标: ");
for(int i = stack.size()-1; i >=0; i--){
System.out.print("-->"+stack.get(i));
}
System.out.print("\n访问过程: ");
for(int i = stack.size()-1; i >=0; i--){
System.out.print("-->"+ g.cities[stack.get(i)]);
}
System.out.print("\n总长度为: ");
int result=0;
for(int i =0; i < stack.size()-1; i++){
result+=g.path[stack.get(i)][stack.get(i+1)];
}
System.out.print(result);
System.out.println("\n");
g.markInit();
}
/**
* @param g:图
* @param start:开始
* @param goal:目的
* @param prev:前驱节点
*
*/
publicvoid UC_search(Graph g,int start,int goal,int[] dist,int[] pre)
{
List<Integer> list =newArrayList<Integer>();
list.add(start);
while(!list.isEmpty())
{
moveMinToTop(list, dist);// 将dist数组中最小值所对应的结点,移至list队首
int current = list.remove(0);// 将list队首的结点出队,并展开
g.mark[current]=1;
if(current == goal)
{
return;
}
for(int j =0; j < g.path[current].length; j++)
{
if(g.path[current][j]<10000&& g.mark[j]==0)
{
if(!isInList(j, list))// 结点j不在队列里
{
list.add(j);
pre[j]= current;
dist[j]= dist[current]+ g.path[current][j];
}
elseif((dist[current]+ g.path[current][j])< dist[j])
{
pre[j]= current;
dist[j]= dist[current]+ g.path[current][j];
}
}
}
if(list.isEmpty())
{
System.out.println("搜索不成功!");
}
}
}
/**
* 检查结点a,是否在队列list里
*/
publicboolean isInList(int a,List<Integer> list)
{
for(int i =0; i < list.size(); i++)
{
if(list.get(i)== a)
{
returntrue;
}
}
returnfalse;
}
/**
* 将dist数组中的最小值所对应的结点,从list队列中移至队列头
*/
publicvoid moveMinToTop(List<Integer> list,int[] dist)
{
int index =0;
int min = dist[index];
for(int i =0; i < list.size(); i++)
{
int a = list.get(i);
if(dist[a]< min)
{
index = i;
min = dist[a];
}
}
int temp = list.get(index);
for(int i = index; i >0; i--)
{
list.set(i, list.get(i -1));
}
list.set(0, temp);
}
}

实验分析:
从结果0-》4-》6-》11-》12可以看出。是最优解,他的复杂度不能简单地使用b、d刻画。得使用C*表示最优解的耗散值。时间复杂度,空间复杂度。
l 【A*搜索】
基本原理:
公式表示为: f(n)=g(n)+h(n),
其中 f(n) 是从初始点经由节点n到目标点的估价函数,
g(n) 是在状态空间中从初始节点到n节点的实际代价,
h(n) 是从n到目标节点最佳路径的估计代价。
保证找到最短路径(最优解的)条件,关键在于估价函数f(n)的选取:
首先将起始结点S放入OPEN表,CLOSE表置空,算法开始时:
1、如果OPEN表不为空,从表头取一个结点n,如果为空算法失败。
2、n是目标解吗?是,找到一个解(继续寻找,或终止算法)。
3、将n的所有后继结点展开,就是从n可以直接关联的结点(子结点),如果不在CLOSE表中,就将它们放入OPEN表,并把S放入CLOSE表,同时计算每一个后继结点的估价值f(n),将OPEN表按f(x)排序,最小的放在表头,重复算法,回到1。
import
java
.
util
.
Stack
;
/** A*搜索类
* @author dyl
*
*/
publicclassAXing{
intMaxWeight=10000;//表示无穷大
Stack stack=newStack<Integer>();
/**A*搜索
* @param g:图
* @param H:启发式函数值
* @param v0:初始值
* @param end:目标值
*/
publicvoid A_Search(Graph g,int H[],int v0,int end){
boolean flag=true;
int x;//表示栈顶元素
int vex;//寻找目标节点
intMinF,MinVex= v0;//记录最小的f(n)和对应的节点
int[][]GHF=newint[g.path.length][3];//分别用于存储g(n),h(n),f(n)
for(int i =0; i < g.path.length; i++){
GHF[i][0]=0;
GHF[i][2]=MaxWeight;//对f(n)初始化,1000表示无穷大
}
stack.push(v0);//v0入栈
GHF[v0][0]=0;//g(n)
GHF[v0][1]=H[v0];//h(n)
GHF[v0][2]=GHF[v0][0]+GHF[v0][1];//f(n)
g.mark[v0]=1;
while(flag){
MinF=MaxWeight;
x=(Integer) stack.peek();
//处理第一个子节点
vex=g.getFirstVex(x);
if(vex==end){//找到目标节点
stack.push(vex);
g.mark[vex]=1;
break;
}
if(vex!=-1){//子节点能找到,继续
if(g.mark[vex]==0){//没被访问
GHF[vex][0]=GHF[x][0]+g.path[x][vex];//节点vex的g(n)
GHF[vex][1]=H[vex];//节点vex的h(n)
GHF[vex][2]=GHF[vex][0]+GHF[vex][1];
if(GHF[vex][2]<MinF){
MinF=GHF[vex][2];
MinVex=vex;
}
}
//处理剩下的邻接点(宽度遍历)
while(vex!=-1){
vex=g.getNextVex(x, vex);
if(vex!=-1&&g.mark[vex]==0){//有邻节点
GHF[vex][0]=GHF[x][0]+g.path[x][vex];//节点vex的g(n)
GHF[vex][1]=H[vex];//节点vex的h(n)
GHF[vex][2]=GHF[vex][0]+GHF[vex][1];
if(GHF[vex][2]<MinF){
MinF=GHF[vex][2];
MinVex=vex;
}
}
if(vex==-1){//没有邻接点了,此时确定最小消耗节点,并压栈
stack.push(MinVex);
g.mark[MinVex]=1;
break;
}
if(vex==end){
stack.push(vex);//压栈目标节点
g.mark[vex]=1;
flag=false;
break;
}
}
}
else{//没有子节点或者子节点被访问了,循环出栈
while(vex==-1){
stack.pop();
}
}
}
newMain().show(g, stack);
}
}
实验结果:

实验分析:
A*搜索估价值h(n)<= n到目标节点的距离实际值,这种情况下,搜索的点数多,搜索范围大,效率低。但能得到最优解。并且如果h(n)=d(n),即距离估计h(n)等于最短距离,那么搜索将严格沿着最短路径进行, 此时的搜索效率是最高的。如果 估价值>实际值,搜索的点数少,搜索范围小,效率高,但不能保证得到最优解。
三、实验结果:

四、思考题
1、根据实验结果分析深度优先搜索,一致代价搜索,迭代加深的深度优先搜索算法的时间和空间复杂度。
2、根据实验结果分析A*搜索的性能。
答:A*算法是一种静态路网中求解最短路径最有效的直接搜索方法。估价值与实际值越接近,估价函数取得就越好。0-》4-》6-》11-》12-14-》15从图中可以看出是最优解,估价值h(n)<= n到目标节点的距离实际值,这种情况下,搜索的点数多,搜索范围大,效率低。但能得到最优解。并且如果h(n)=d(n),即距离估计h(n)等于最短距离,那么搜索将严格沿着最短路径进行, 此时的搜索效率是最高的。如果 估价值>实际值,搜索的点数少,搜索范围小,效率高,但不能保证得到最优解。
该实验是人工智能的实验,之前做的时候没考虑到代码优化,所以代码量有点大,请大家见谅。如有不对的地方,希望大家提出建议。