Oracle数据库的体系结构
- 数据库: database
Oracle数据库是数据的物理存储,和mysql不一样的是,只要我们愿意,我们就可以在mysql下创建任意的数据库,每个新项目的启动,创建一个数据库,然后通过
showdatabases可以查看到全部数据库,但是Oracle的数据库是一个操作系统只有一个库,说白了,就是把Oracle看成一个大的数据库
- 实例:
一个Oracle实例,有一系列的后台进程(Background Processes) 和内存结构(Momory Structures),一个数据库,可以有多个实例
- 数据文件: dbf
Oracle中的数据是存放在表空间里面的 数据文件中的,一个数据文件,只属于一个表空间,一旦数据文件被加入到表空间,那么,这个数据文件就不能被删除了,除非我们删除表空间
- 表空间
表空间其实是一种逻辑上的映射, 我们知道,Oracle的数据存放在 数据文件(dbf/ora)中,数据文件在Oracle中是物理层面上的结构,而表空间,就是基于物理层面的数据文件的逻辑上抽象出来的映射, 一个Oracle数据库,至少有一个表空间(system表空间),每个表空间,由同一个磁盘上的一个或多个数据文件组成
每个新项目的启动我们都会创建新的表空间
- 用户:
用户是在实例下创建的,1. 不同实例中可以创建相同名字的用户, 2. 表的数据是由用户放入到表空间里面的,表空间在把数据随机的放入到一个或者多个不同的数据文件中
oracle中的数据由 用户+表空间 进行管理和存放! 表是给用户去查的,而不是给表空间查,因为不同的用户可以在同一个表空间创建同名的表,所以Oralce区分用户
6: SCOTT 用户 和 HR用户
这两个用户是Oracle默认的初始用户,让初学者更好的进行学习
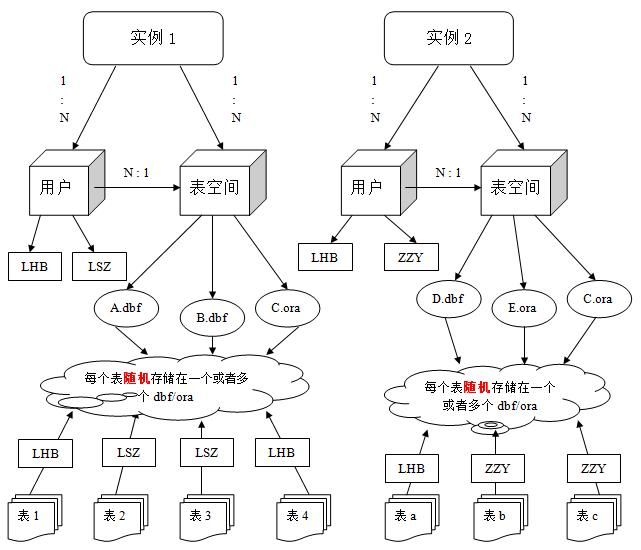
举个例子,顺一下整个Orcle的使用流程
1. 公司新项目启动
2. 运维工程师(DBA)在Oracle数据库给新项目开辟一个新的表空间
- 运维工程师登录数据库的身份是 DBA(系统管理员), DBA是超人,裤衩穿在外面,拥有对Oracle的最高权限
创建表空间的sql
create tablespace 表空间名
logging
datafile 'D:\oracle\oradata\Oracle9i\user_data.dbf' -- dbf文件的路径
size 50m -- 单个dbf文件初始化大小
autoextend on -- 自动增长
next 50m -- 下次增长的大小
maxsize 20480m -- 最大内存后续插入到数据库里面的数据存放在磁盘上的 XXX.DBF文件中,而表空间就是对这些dbf文件的抽象
安装完数据库,会自动创建1. System系统表空间 2.TEMP 临时表空间 3. UNDP 重做日志表空间 4.USERS 用户表空间(创建普通用户时默认的表空间)
DBA查看表空间是否创建成功
Select file_name,tablespace_name from dba_data_files order by file_name;dba_data_files 这种dba_XXX 开头的,只有DBA才有权限查看,普通用户执行的话,会报错说,表或视图不存在
DBA查看每个用户的默认表空间
select user_id , username, default_tablespace from dba_users;DBA修改默认的用户表空间(我们知道,新创建用户属于users,而下面的命令就可以把users替换成其他存在的表空间)
Alter database default tablespace 其他表空间; DBA修改表空间的名称
Alter tablespace 表空间的当前名称 rename to 表空间的新名称DBA 删除表空间
drop tablespace user1 ; -- 不会删除本地的 dbf文件
drop tablespace user1 including contents and datafiles; -- 删除本地的dbf 数据文件一般不让普通用户创建表空间,若他非要创建,需要问DBA要 授权
3.DBA给开发工程师创建账号
创建用户的sql
create user 用户名
identified by 密码
default tablespace 表空间;注意: 新创建的用户没有任何权限,他甚至都不能登录Oracle数据库,(新创建的用户登录Oracle会报错说
缺少创建session的权利)
4. DBA给新创建的用户授权
DBA给普通用户授权sql
grant 角色/权限 to 用户名;DBA自定义角色sql
sql create role 自定义角色名创建会话
然后使用 grant给我们的角色授权,grant给用户
DBA删除角色sql
试了一下,DBA删除系统自带的角色,果然还是裤衩穿在外面,二话不说,删除成功了
drop user 用户名 cascade; -- 删除用户级联的关系也会被删除掉权限的传递(包括普通用户,只要求当前的东西是属于他的就行)
关键字: with grant option;
例: scott 把属于他的emp表的 增删改查权限给 另一个用户B ,同时允许B把权限传递给别人
grant all on emp to B with grant option;注意点:
- with grant option 可选, 如果不写的话,B用户不能把权限传递给别人
- B用户得到的权限 针对的是表中的数据,而不是这张表, 表的主人仍然是scott
- B试着删除emp表,结果尝试删除不属于自己的表直接掉线了
- B对emp的操作都要添加前缀 scott.emp
收回部分权限/全部权限
Revoke select[insert,delete,update] on 表名 from 用户名
Revoke all on 表名 from 用户名当前用户(包括普通用户查看自己的权限)
select * from user_sys_privs;- 问一句, 什么是权限?什么是角色?
刚才说了,在Oracle中,新创建的用户默认一点权限都没有,没有权限就不能对数据库进行操作, 有了用户但是不能对oracle进行操作那要这个用户 干什么? 所以就得根据需求授予用户权利
比如说,如果 create session 权限,可以让用户登录Oracle, create table权限可以让用户在自己所属的表空间创建表
多个权限的集合 === 角色
在Oracle主要有三种角色, 分别是
1. DBA系统管理员
这个角色拥有至高无上的权限,传说中删库跑路的主,拥有的角色就是DBA
2. Resource 专属开发者的权限
开发者可以做下面的事,开发我们的新项目
- create cluster 建立聚簇
- create procedure 建立过程
- 存储过程是一组已经编译好了的plsql语句,辅助提高对数据库的读写效率
- create sequence 建立序列
- oracle和mysql不一样,是没有auto_increament自增长的,而序列可以间接实现自增长
- create table 建表
- create trigger 创建触发器
- 我们可以把它理解成是监听器,监听用户对具体某张数据表的具体操作(inset update delete)然后再操作前后做出相应的 逻辑反应
- create type 创建类型
- 变量名 类型
3. Connect 最终用户的权限
- alter session 修改
- create cluster 建立聚簇
- create Database Link 创建数据库连接
- create session -- 创建会话(登录的前提)
- create synonym 创建同义词
- create view 创建视图
5. 开发人员把密码忘了DBA怎么办?
修改某用户的 用户密码
alter user 用户名 identified by 新密码;6. 开发人员离职DBA怎么办?
删除用户
DROP USER 用户名 CASCADE;补充概念
什么是事务
事务可以理解成是一组操作的集合,要么都成功,要么都失败
事务的四大特性
- Atomicity 原子性
- Consistency 一致性
- Isolation 隔离性
- Durability 持久性
事务的提交 , 回滚点, 回滚
- commit
- savepoint
- rollback
什么是视图?
视图可以理解成一扇窗户,是对我们查询出来的数据的封装,说的这么高大尚,但是本质就是从好几张不同的表中抽取字段,组成一张新的表(从而屏蔽掉我们不想看到的字段)
特点: 视图中的所有数据都来自于原表中的数据,换句话说,如果视图中的数据被更改,原表中的数据也会被修改 但是如果我们在创建视图时添加 with read only 就是只读的视图
创建视图 用的关键字是 as (同义词是for 别混了)
语法:
create or replace view 视图名 as 查询语句 [whth read only]再说一下,视图本质还是一张表,只要不设置它是只读的,那么,DML语句同样适用于视图
什么是别名?
关键字是 synonym(别名)
sql
create or replace 别名 for 视图/表很多情况下我们是给视图取别名,因为一般视图的名称都是XXX_view,遵循命名规范,一看他就是视图,为了让他看起来像个表,于是我们给视图取个表的名子
什么是序列?
在mysql中,我们想让某个字段自增长的话, 可以使用 auto_increatement 关键字
然而oracle没有auto_increatement!!! 但是 oracle 中 使用序列完成对相似操作
语法:
create sequence 序列名
start with 从几开始
increment by 每次增长几
maxvalue 最大值| nomaxvalue
minvalue 最小值 | nominvalue
cycle | nocycle
cache 缓存的数量 | nocache注意点:
- 下面的语句执行报错了,原因是 cache值必须小于cycle , 也就是指定了 cycle, 就必须再写出cache的值,不然报错
create sequence startText1
start with 1
increment by 2
maxvalue 30
cycle
;正确创建:
create sequence startText1
start with 1
increment by 2
maxvalue 30
cycle
cache 10;从序列中获取值
关键字: currval : 当前值
关键字: nextval : 下一个值
- 注意: ----- currval 在 nextval之后才能用
select startText1.nextval from dual; -- 先执行
select startText1.currval from dual; -- 再执行,不然报错/或者一直都是当前值create sequence seq_text2; -- 默认没有最大值,不循环,不缓存
什么是索引?
- 相当于一本书的目录,可以提高我们的查询效率
-- 语法
create index 索引名称 on 表名(列)注意:
主键约束自带主键索引
唯一约束自带唯一索引
sql 优化
-- 考虑 Cost CPU调用次数
-- 考虑 Cardinality 影响行数
在百万级别的数据里面检索, 建立索引 create index 无论是在Cost CPU的调用次数,还是Cardinality 影响行数 都会产生上百数量级级别的差距
-- 索引 原理;
-- btree balance Tree 平衡二叉树
-- 每个子节点都会记录 物理地址 --- rowid
-- 优点: 把某列当作查询条件的时候, 可以提高查询效率,
-- 缺点: 在修改的时候,会变慢(DBA 每隔一段时间就会重构索引)