Kaggle大神带你上榜单Top2%:点击预测大赛纪实(下)
 作者:Gabriel Moreira
作者:Gabriel Moreira
编译:修竹、柳青秀、王梦泽、钱天培
在上周,文摘菌为大家介绍了资深数据科学家Gabriel参加Kaggle的Outbrain点击预测比赛的前半程经历(戳链接阅读 Kaggle大神带你上榜单Top2%:点击预测大赛纪实(上))。
这周,我们将继续听大神唠嗑,看他又在比赛冲刺阶段用到了哪些数据科学领域的知识技能。
作为全世界最知名的数据挖掘、机器学习竞赛平台,Kaggle早已成为数据玩家在学习了基础机器学习之后一试身手的练兵场。
在该系列的上半部分中,我介绍了Outbrain点击预测机器学习比赛以及我对这次竞赛所做的初步处理。同时也介绍了用于探索性数据分析、特征工程、交叉验证策略和使用基础统计学和机器学习的基线预测模型的主要技术。
在系列的下半部分,我将描述我是如何使用更有效的机器学习算法来解决点击预测问题的。接下来我会介绍一些集成方法(ensemble methods),这些方法将我带到排行榜(Leaderboard)第19位(Top2%)。
FTRL(Follow-the-Regularized-Leader)算法
点击率预测的常用方法之一是使用FTRL优化器进行逻辑回归。谷歌通过FTRL优化器和相应较大的特征空间来预测每天数十亿的事件。
FTRL是一种懒结合了L1正则、可生成非常稀疏的系数向量的线性模型。因为每个实例通常只有几百个非零值,稀疏性可以缩小对内存的使用,使得数十亿维度的特征向量具有可伸缩性。FTRL通过从磁盘或网络上的流实例为大型数据集提供高效训练,即每个训练样本仅需被处理一次(在线学习)。
我尝试了两种不同的FTRL实现,分别适用于Kaggler框架和Vowpal Wabbit(VW)框架。
对于点击率预测,理解特性之间的交互作用是很重要的。比如,由于发布广告的平台不同(比如 ESPN和Vogue),Nike广告客户的平均转化率也会有不同。
我考虑了在Kaggler FTRL平台上训练模型的所有分类特征。特征交互选项被启用,这意味着对于所有可能的成对的特征组合,特征值增多并哈希(请阅读第一部分的特征哈希)到一个具有维度为2²⁸的稀疏特征向量的位置。这是我运行最慢的一个模型,训练时间花了超过12个小时。但是通过该方法(方法6),我的排行榜分数跃到了0.67659。
我也在VW中使用了FTRL,这是一种在使用CPU和内存资源上非常快速和有效的框架。输入数据(Input data)仍然是分类特征,除此之外还有一些被选出的数值型分箱特征(请阅读第一部分的特征分箱)。我最好的一个模型在2个小时之内就训练好了,此方法(方法7)的排行榜分数为0.67512。准确率也许稍微低了一点,但是比方法6速度快很多。
在VM的第二个FTRL模型中,我使用了VM超参数来配置只有特征子集(命名空间)的交互(特征对)。在此情况下,交互只对分类特征和一些选定的数值型特征(没有分箱转化)进行配对。 这个调整获得了一个更好的模型,排行榜分数为0.67697。我将这个模型称为方法8。
我最终提交的版本用到了以上三种FTRL模型的集成,我将会在下文描述。
FFM (Field-aware Factorization Machines)算法
在2014年两个CTR预测比赛中获胜的方法都使用了一种叫 Field-aware Factorization Machines (FFM)的方法,它是因式分解机(Factorization Machines)的变体。FFM尝试通过学习每个特征交互对的潜在因素来为特征交互建模。这个算法可以在LibFFM框架中实现并且已被许多参赛者使用。LibFFM对大型数据集的并行处理和内存使用非常有效。
在方法9中,我使用了分类特征并以700000的维度进行哈希交互。最佳模型训练只用了37分钟。这也是我最好的一个模型,排行榜分数为0.67932。
在方法10中,输入数据除了分类特征外加入了一些被选出的数值型分箱特征。训练时间增加到了214分钟,排行榜分数为0.67841。
在方法11中,基于对过去的训练可以提高对测试集未来两天的预测(50%)的假设,我尝试只用训练集中过去30%的数据来训练FFM模型。排行榜分数是0.6736,对于过去两天的准确率的确增加了,但是对于之前测试集数据的准确率下降了。
在机器学习项目中,一些很有效的方法最终以惨败告终的情况并不罕见。在我训练FFM模型中就遇到过这样的事情。我曾尝试效仿Criteo比赛中的一个成功事例,将GBDT模型学习方法通过叶编码转到FFM模型中。但是FFM模型准确率却下降了,也许是因为GBDT模型在这个背景中并不足够准确,所以增加了更多的噪音而不是信号。
另外一个失败的方法是训练多个独立的FFM模型,具体适用于测试集中有多个事件的地理区域,比如一些国家(US ~ 80%, CA ~ 5%, GB ~ 5%, AU ~ 2%, Others ~ 8%)和一些美国的州(CA ~ 10%, TX ~ 7%, FL ~ 5%, NY ~ 5%)。为了生成预测,每个测试集的事件都被发送到该区域的特定模型。专门针对美国的模型对该区域的点击率有比较好的预测,但是对其他地区预测的准确率要偏低一些。因此,用全球范围的FMM模型表现的要更好。
这三个选定的FFM方法同样被用到了最终集成里面。
集成方法(Ensembling methods)
集成方法由不同模型的预测组成,用于提高精度和泛化能力。相关模型预测越少,集成精度越高。集成的主要思想是个别模型不仅受到信号的影响,也受到随机噪声的影响。采用不同模型并结合其预测,能取消相当多的噪音,使得模型具备更好的泛化能力,如下图所示。
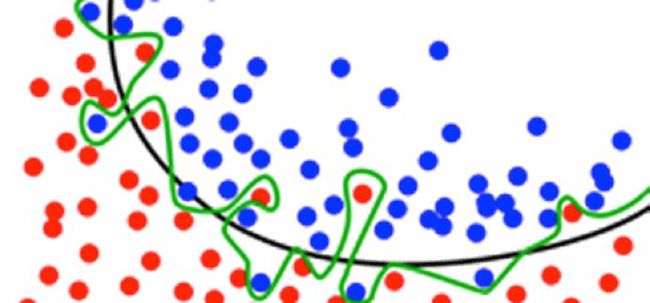
一种简单而有力的集成方法是通过平均来合并模型预测。在这次比赛中,我测试了许多类型的加权平均值,比如算术、几何、调和以及排名平均值等等。
我能找到的最好的方法是利用如式1所示的预测的CTR(概率)的logit(sigmoidal logistic的倒数)的加权算术平均值。它考虑了三个选定的FFM模型(方法9、10和11)以及一个FTRL模型(方法6)的预测。此平均值在方法12中让我得到了0.68418的LB得分,与我最好的单一模型相比(方法10,得分为0.67932),这是一个不错的跳跃。
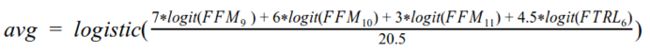
模型预测的logit加权平均法
当时,距离竞赛提交截止日期只剩几天。在剩下的时间,我选择使用Learn-to Rank模型来融合最好的模型预测。
该模型是具备100棵树的GBDT,且其排序的目的是为xgboost研发部门所用。此被认为是输入的集成具有最好的3FFM和3FTRL模型预测以及15选定的工程数字特征(如用户意见数、用户偏好的相似性和平均CTR的类别)。
该集成层仅使用验证集数据(在上半部分中描述过)在一个名为Blend的模块中进行训练。采用这种方法的原因是,如果集成模型也考虑训练集的预测,它将优先考虑更多过拟合模型,从而降低其对测试集的泛化能力。在最后一天的比赛中,方法13让我得到最好的公共LB分数(0.68688)。比赛结束后,我的私人LB得分为0.68716,并使我在决赛中保持在第十九的位置,如下图所示。
Kaggle的Outbrain Click预测最终成绩

我没有跟踪确切的提交天数,但下面的图表显示出我的LB分数在竞赛中是如何演变的。可以看出,第一次提交在成绩上提供了很好的跳跃,但在此基础上的改进变得更加困难,这在机器学习项目中相当普遍。
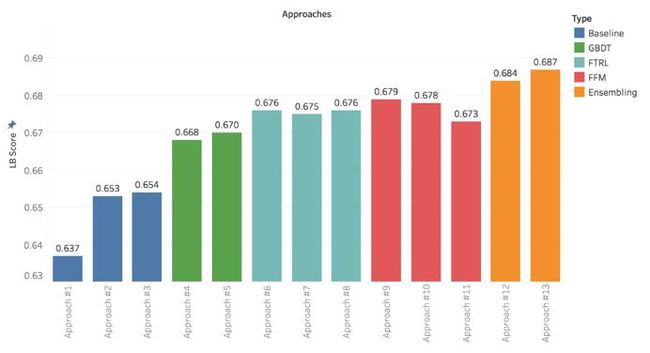
在竞赛中我方法得到的LB分数
总结
我从这次比赛中学到的一些经验有:
1、良好的交叉验证策略在竞争中至关重要。
2、应该在特征工程上投注精力。在数据集上添加新功能需要付出更多的努力和时间。
3、散列是稀疏数据的必要条件。事实上,它在简单和高效方面的性能优于One-Hot编码(OHE)。
4、对于决策树集合而言,OHE分类特征并不是最优的。基于竞争对手共享的经验,树形集合能够在足够多的树的情况下能更好地表现出原始分类值(IDS),因为它将特征向量降到一个更低的维数,从而增加包含更多预测特征概率的随机特征集。
5、对于学习而言,测试许多不同的框架会很有帮助,但通常需要大量时间来转换数据所需的格式,阅读文件和调整参数。
6、阅读主要技术(FTRL和FFM)相关的研究论文对于超参数调整的指导是必不可少的。
7、研究论坛的帖子、公共核(共享代码)和竞争对手共享的过去解决方案是学习的好方法,对于竞赛至关重要。每个人都应该分享一些东西!
8、基于平均的集成精度提高很多,与ML模型混合使用条形图,并且必须进行堆叠。我没有时间去探索堆叠,但根据其他竞争者的说法,在固定折叠中使用非折叠预测可以增加集合训练(完整训练集)的可用数据,并提高最终集合的精度。
Kaggle对于那些决定接受挑战、从过程和同行中学习的人来说,就像一所先进的机器学习大学。与世界级的数据科学家一起竞争和学习是一次非常吸引人的经历。
谷歌云平台在这段旅途中就像一个伟大的徒步旅行伙伴,它提供了所有必要的爬山工具来克服大数据和分布式计算的悬崖,而我的重点和努力的目的是为了到达山顶。
好了,这篇Kaggle大神经验分享系列就到此为止了。
如果你觉得读完这篇经验分享很有收获并且对Kaggle竞赛充满兴趣的话,就赶紧参加一个Kaggle竞赛练练手吧,文摘菌先走一步去报名啦~
关于集成方法的更多讯息:
https://mlwave.com/kaggle-ensembling-guide/
原文链接:
https://medium.com/unstructured/how-feature-engineering-can-help-you-do-well-in-a-kaggle-competition-part-iii-f67567aaf57c
优质课程推荐:《人工智能的数学基础》
往期学员评价(by Leo Tian)
作为一名软件工程在读本科生,关于机器学习和人工智能领域的课程我也没少上。而在我所有上过课程的老师中,对于基础数学知识讲解的最详细、最透彻的,Jason博士绝对是数一数二的。
Jason博士曾经在信号处理领域做过深入研究,对于计算机领域涉及到的数学问题,也同样有着非常独到的理解。而正是他这种基于大量工程项目经验的理解,能够很轻易的帮助同学们把非常抽象复杂的数学问题,讲的生动有趣,透彻明白。
他常常能把高维的数学问题降低到二维,在二维中带领大家理解其中的原理,再反过来推广到高维。这种方法就如同看推理小说,在得出结论时绝对可以令你拍案叫绝。
我很感激能够听到Jason博士的课程,我也非常希望把这份优质的课程介绍给其他同学。

志愿者介绍
回复“志愿者”加入我们




往期精彩文章
点击图片阅读
Kaggle大神带你上榜单Top2%:点击预测大赛纪实(上)


