hadoop单机模式、伪分布式和分布式
hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
HDFS架构
(1)NameNode
(2)DataNode
(3)Secondary NameNode
NameNode
(1)是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
(2)文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
(3)以上这些文件是保存在linux的文件系统中。
SecondaryNameNode
(1)HA的一个解决方案。但不支持热备。配置即可。
(2)执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
(3)默认在安装在NameNode节点上,但这样不安全!
Datanode
(1)提供真实文件数据的存储服务。
(2)文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.
dfs.block.size
(3)不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
(4)Replication。多复本。默认是三个。hdfs-site.xml的dfs.replication属性
一.单机模式
- 建立用户,设置密码(密码此次设置为(redhat)
[root@server1 ~]# useradd -u 1000 hadoop
[root@server1 ~]# passwd hadoop
2.hadoop的安装配置
[root@server1 ~]# mv hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz /home/hadoop
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls
hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf hadoop-3.0.3.tar.gz
[hadoop@server1 ~]$ ln -s jdk1.8.0_181/ java
[hadoop@server1 ~]$ ln -s hadoop-3.0.3 hadoop
[hadoop@server1 ~]$ ls
hadoop hadoop-3.0.3.tar.gz jdk1.8.0_181
hadoop-3.0.3 java jdk-8u181-linux-x64.tar.gz
3.配置环境变量
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim hadoop-env.sh
54 export JAVA_HOME=/home/hadoop/java
[hadoop@server1 ~]$ vim .bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/java/bin
[hadoop@server1 ~]$ source .bash_profile
[hadoop@server1 ~]$ jps
2133 Jps


4.测试
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ mkdir input
[hadoop@server1 hadoop]$ cp etc/hadoop/*.xml input/
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 output]$ cat *
1 dfsadmin
二.伪分布式
namenode和datanode都在自己这台主机上
1.编辑文件
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim core-site.xml
fs.defaultFS
hdfs://localhost:9000
[hadoop@server1 hadoop]$ vim hdfs-site.xml
dfs.replication
1
2.生成密钥做免密连接
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ ssh-copy-id localhost
3.格式化,并开启服务
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ cd sbin/
[hadoop@server1 sbin]$ ./start-dfs.sh
[hadoop@server1 sbin]$ jps
2458 NameNode
2906 Jps
2765 SecondaryNameNode
2575 DataNode
4.浏览器查看http://172.25.68.1:9870
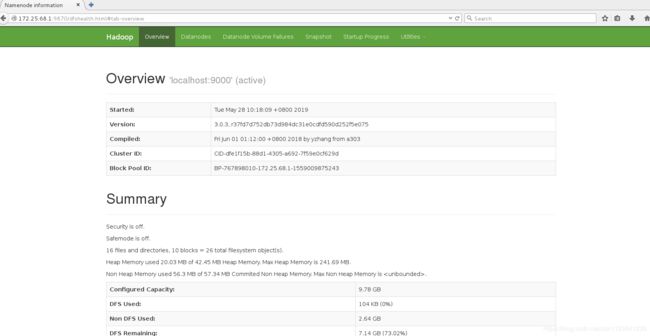
5.测试,创建目录,并上传
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
[hadoop@server1 hadoop]$ bin/hdfs dfs -put input
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-05-28 10:20 input

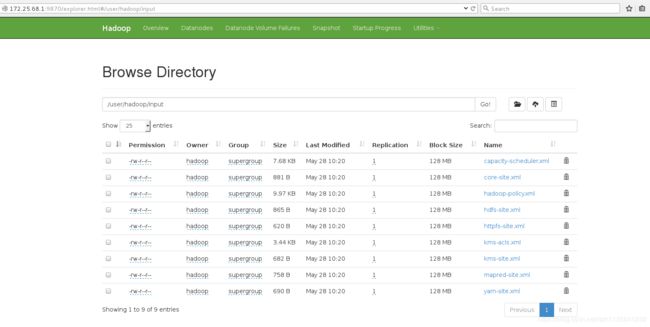
- 删除input和output文件,重新执行命令(测试从分布式上拉取文件)
[hadoop@server1 hadoop]$ rm -fr input/ output/
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
[hadoop@server1 hadoop]$ ls
bin etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
**此时input和output不会出现在当前目录下,而是上传到了分布式文件系统中,网页上可以看到**
[hadoop@server1 hadoop]$ bin/hdfs dfs -cat output/*
1 dfsadmin
[hadoop@server1 hadoop]$ bin/hdfs dfs -get output ##从分布式系统中get下来output目录
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 output]$ cat *
1 dfsadmin
分布式
主机是namenode,其它从机是datanode
1.先停掉服务,清除原来的数据
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [server1]
[hadoop@server1 hadoop]$ jps
3927 Jps
[hadoop@server1 hadoop]$ cd /tmp/
[hadoop@server1 tmp]$ ls
hadoop hadoop-hadoop hsperfdata_hadoop
[hadoop@server1 tmp]$ rm -fr *
2.新开两个虚拟机,当做节点
[root@server2 ~]# useradd -u 1000 hadoop
[root@server3 ~]# useradd -u 1000 hadoop
[root@server1 ~]# yum install -y nfs-utils
[root@server2 ~]# yum install -y nfs-utils
[root@server3 ~]# yum install -y nfs-utils
[root@server1 ~]# systemctl start rpcbind
[root@server2 ~]# systemctl start rpcbind
[root@server3 ~]# systemctl start rpcbind
3.server1开启服务,配置
[root@server1 ~]# systemctl start nfs-server
[root@server1 ~]# vim /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server1 ~]# exportfs -rv
exporting *:/home/hadoop
[root@server1 ~]# showmount -e
Export list for server1:
/home/hadoop *
4.server2,3挂载
[root@server2 ~]# mount 172.25.68.1:/home/hadoop/ /home/hadoop/
[root@server2 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 10258432 1097104 9161328 11% /
devtmpfs 497292 0 497292 0% /dev
tmpfs 508264 0 508264 0% /dev/shm
tmpfs 508264 13072 495192 3% /run
tmpfs 508264 0 508264 0% /sys/fs/cgroup
/dev/sda1 1038336 141516 896820 14% /boot
tmpfs 101656 0 101656 0% /run/user/0
172.25.68.1:/home/hadoop 10258432 2796544 7461888 28% /home/hadoop
[root@server3 ~]# mount 172.25.68.1:/home/hadoop/ /home/hadoop/
5.server1免密登陆server2和server3
[root@server1 tmp]# su - hadoop
Last login: Tue May 28 10:17:23 CST 2019 on pts/0
[hadoop@server1 ~]$ ssh 172.25.68.2
[hadoop@server2 ~]$ logout
Connection to 172.25.68.2 closed.
[hadoop@server1 ~]$ ssh 172.25.68.3
[hadoop@server3 ~]$ logout
Connection to 172.25.68.3 closed.
6.编辑文件(server1做namenode,server2和server3做datanode)
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim core-site.xml
fs.defaultFS
hdfs://172.25.68.1:9000
[hadoop@server1 hadoop]$ vim hdfs-site.xml
dfs.replication
2
[hadoop@server1 hadoop]$ vim workers
[hadoop@server1 hadoop]$ cat workers
172.25.68.2
172.25.68.3
7.格式化,并启动服务
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server1]
Starting datanodes
Starting secondary namenodes [server1]
[hadoop@server1 hadoop]$ jps #出现SecondaryNameNode
4673 SecondaryNameNode
4451 NameNode
4787 Jps
从节点可以是datanode
[hadoop@server2 hadoop]$ jps
2384 DataNode
2447 Jps
[hadoop@server3 hadoop]$ jps
2386 DataNode
2447 Jps
8.测试
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir input
[hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/*.xml input
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
网页上查看,有两个节点,且数据已经上传


9.添加节点server4
[root@server4 ~]# useradd -u 1000 hadoop
[root@server4 ~]# yum install -y nfs-utils
[root@server4 ~]# systemctl start rpcbind
[root@server4 ~]# mount 172.25.68.1:/home/hadoop /home/hadoop
[root@server4 ~]# su - hadoop
[hadoop@server4 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server4 hadoop]$ vim workers
172.25.68.2
172.25.68.3
172.25.68.4
[hadoop@server4 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
[hadoop@server4 hadoop]$ jps
3029 DataNode
3081 Jps
浏览器查看,节点添加成功
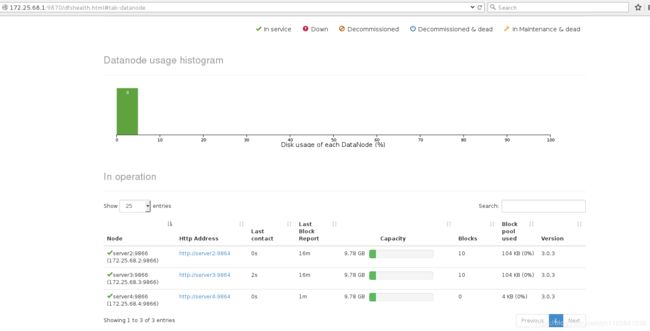
server4上传文件
[hadoop@server4 hadoop]$ dd if=/dev/zero of=bigfile bs=1M count=500
500+0 records in
500+0 records out
524288000 bytes (524 MB) copied, 15.8634 s, 33.1 MB/s
[hadoop@server4 hadoop]$ bin/hdfs dfs -put bigfile
