机器学习之模型评价篇
目录
- 带你认识各种评价指标
- sklearn中的调用方法
- 模型评估的方法
- 过拟合和欠拟合
- 过拟合的几种解决方法
- 超参数调优
- 模型评估面试题记录
带你认识各种评价指标
常见的指标以及其术语:
混淆矩阵、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值、真阳性率、假阳性率、查准率、查全率、特异性、敏感性…
各个评价指标的定义:
混淆矩阵:
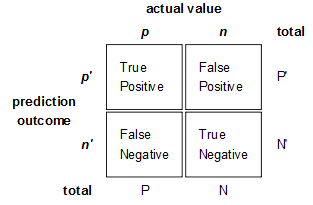
准确率:
A c c u r a c y = n c o r r e c t n t o t a l = T P + T N T P + F N + F P + T N Accuracy = \frac{{{n_{correct}}}}{{{n_{total}}}} = \frac{{TP + TN}}{{TP + FN + FP + TN}} Accuracy=ntotalncorrect=TP+FN+FP+TNTP+TN 准确率是指分类正确的样本占总样本的比例,它的缺点是不能用于正负样本不均衡的情况。
精确率=查准率:
P r e c i s i o n = T P ( T P + F P ) Precision = \frac{{TP}}{{\left( {TP + FP} \right)}} Precision=(TP+FP)TP 精确率只针对预测正确的样本而不是预测错误的样本,它想知道预测是正样本中正确预测的比例。
召回率=查全率=真阳性率=敏感性
R e c a l l = T P ( T P + F N ) {\mathop{\rm Re}\nolimits} call = \frac{{TP}}{{\left( {TP + FN} \right)}} Recall=(TP+FN)TP 召回率想知道对于正样本,分类器能够预测出多少。
F1值
2 F 1 = 1 p r e c i s i o n + 1 r e c a l l \frac{2}{{F1}} = \frac{1}{{precision}} + \frac{1}{{recall}} F12=precision1+recall1 F1值是精确度和召回率的调和平均数,推荐系统一般用它来做评价指标。
ROC曲线
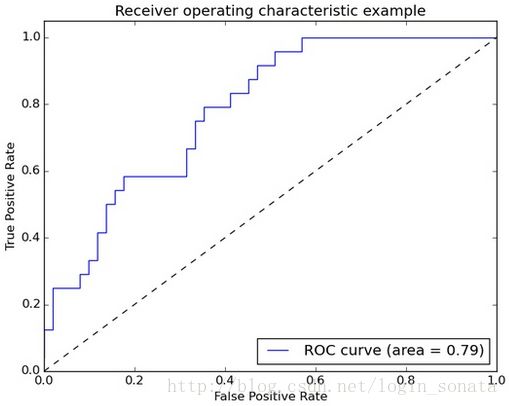
sklearn中的调用方法
sklearn里面有着专门的函数库来调用上述评价指标。
#准确率
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pre)
#平均准确率
from sklearn.metrics import average_precision_score
average_precision_score(y_true, y_pre)
#混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pre)
#精度、召回率和F1值
from sklearn.metrics import classification_report
classification_report(y_true,y_pre)
#AUC值
from sklearn.metrics import roc_auc_score
roc_auc_score(y_true, y_pre)
#绘制ROC曲线
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_true, y_pre)
roc_auc= auc(fpr, tpr)
plt.plot(fpr, tpr)
plt.xlabel("假阳性率")
plt.xlabel("真阳性率")
plt.title("ROC曲线")
#均方误差
from sklearn.metrics import mean_squared_error
mean_squared_error(y_true, y_pre)
#拟合优度
from sklearn.metrics import r2_score
r2_score(y_true, y_pred)
模型评估的方法
模型的泛化性能如何评估?
- Holdout检验
随机将数据集分成两部分,70%用于训练,30%用于模型验证,缺点是数据集的划分存在随机性,这对于模型评估不太友好。
#Holdout验证
from sklearn.model_selection import train_test_split
#stratify是为了保证划分后不同类别的比例是一致的
x_train, x_test, y_train, y_test= train_test_split(data, labels, stratify=labels,test_size=0.33, random_state=0)
- 交叉验证
k折交叉验证是将数据集分成k个大小接近的子集,每次选择一个子集作为验证,其余子集作为训练,最后将k次评估结果取平均。缺点是数据集小的情况划分数据集可能会影响模型训练。
#K折交叉验证
from sklearn.modoel_selection import cross_val_score
scores= cross_val_score(clf, data, labels, cv=10, scoring='accuracy')
- 自助法(BootStrap)
对样本进行有放回抽样,假设数据集包含n个样本,有放回的重复采样n次,得到n个数据,这些数据中有些数据是重复的,样本集中有些数据没有被抽中,将没有抽中的样本作为验证集,这些样本大概占36.8%。自助法适合小样本数据集。
#pandas中有一个现成的方法实现自助法
#replace表示是否放回,frac表示抽取样本的比例,axis=0表示抽取的是行
data.sample(frac=1.0, replace=True,axis=0)
过拟合和欠拟合
模型评估过程中经常会遇到欠拟合、过拟合的情况,那么什么样的情况叫做欠拟合?什么样的情况叫做过拟合?应该怎么样调整? 如上图所示, 第一幅图的训练得分高于验证得分,表现为欠拟合。第二幅图的训练得分和验证得分都很高,这种情况是比较有利的。第三幅图训练得分很高,验证得分很低,典型的过拟合现象。因此过拟合和欠拟合可以通过绘制learning curve来判断。
如上图所示, 第一幅图的训练得分高于验证得分,表现为欠拟合。第二幅图的训练得分和验证得分都很高,这种情况是比较有利的。第三幅图训练得分很高,验证得分很低,典型的过拟合现象。因此过拟合和欠拟合可以通过绘制learning curve来判断。
#学习曲线的绘制
from sklearn.learning_curve import learning_curve
import matplotlib.pyplot as plt
#train_sizes用来控制用于训练的样本数量
train_sizes, train_scores, test_score= learning_curve(clf, data, labels, train_sizes= np.linspace(0.1,1.0,10),cv=10)
过拟合的几种解决方法
- 数据增强
获取更多数据是应对过拟合最有效的方法,如果直接增加数据量不现实,可以通过Data Augumentation的方式增加样本。 - 降低模型复杂度
减小网络层数、神经元个数;决策树中的剪枝 - 正则化
- 提前终止迭代
- DropOut
超参数调优
超参数和参数有什么区别?
参数指的是模型训练后得到的变量值,比如权值、偏置。超参数指的是用来确定模型的参数,比如神经网络层数、神经元个数、学习率、迭代次数、树的深度、K均值中K值等等。
如何进行调参?
这里主要介绍网格搜索,它在kaggle里用的比较多。
网格搜索它的作用是自动帮你做交叉验证
#网格搜索的sklearn使用
from sklearn.model_selection import GridSearchCV
#以支持向量机为例,params是一个字典,用来存放你设定的超参数的值,以供网格搜索
params= {'kernel':('linear','rbf'),'C':[1,10]}
grid= GridSearchCV(clf,param_grid=params,cv=10)
grid.fit(data, label)
#返回最佳参数
grid.best_estimator_
模型评估面试题记录
- 简述偏差和方差
偏差是预测值的期望和标签的差值,它会导致模型欠拟合;
方差是不同训练数据得到的模型预测值之间的差异,方差大表示模型对训练数据的变化十分敏感,会导致过拟合。- 精确率和召回率的定义
精确率表示预测为正样本中预测正确的比例。召回率表示正确预测的正样本占全部正样本的比例。- 多分类任务如何绘制ROC曲线
假设有n个类别,m个测试样本,每个类别下都可以得到m个测试样本的概率,这样可以计算每个类别下的ROC曲线,最后对n条ROC曲线取平均得到最终的ROC曲线。