Winner-Take-All Autoencoders ( 赢者通吃自编码器)
Winner-Take-All Autoencoders ( WTA-AE 赢者通吃自编码器)
Alireza Makhzani, Brendan Frey
2015 NIPS
论文地址:http://papers.nips.cc/paper/5783-winner-take-all-autoencoders.pdf
这个模型在传统的稀疏自编码的空间稀疏性约束之外,又增加了一个lifetime sparsity,利用的是mini-batch的统计特性。
这个模型的改进主要就是为了解决无监督学习中,我们在没有标签的情况下学到的representation是不是powerful的。作者给出了两个模型,fully-connected全连接的,以及convolutional 卷积的,winner-take-all model。赢者通吃,顾名思义,就是只保留最大的,其他的直接被抑制掉。
Fully-Connected Winner-Take-All Autoencoders
Fully-Connected Winner-Take-All (FC-WTA)
传统的对于稀疏性的penalty用KL散度进行表示,也就是lambda KL(rho||hat{rho}),其中hat rho是hidden unit marginal,而rho是target sparsity probability。这样的稀疏约束一方面对于lambda的选取很困难,另一方面主要是针对sigmoidal的激活函数的输出,因为KL散度计算的是概率(确切的说,是每个神经元在整个训练集上的平均激活率的一个限制,因为KL散度是计算两个bernoulli分布的差异的)。
FC-WTA是本文的稀疏自编码在全连接网络的实现,训练速度快,仅仅略慢于standard ae,也没有超参数,比如上面的lambda。
In the feedforward phase, after computing the hidden codes of the last layer of the encoder, rather than reconstructing the input from all of the hidden units, for each hidden unit, we impose a lifetime sparsity by keeping the k percent largest activation of that hidden unit across the mini-batch samples and setting the rest of activations of that hidden unit to zero. In the backpropagation phase, we only backpropagate the error through the k percent non-zero activations.
上面可以看出,训练过程中,对于一个mini batch中的sample,只保留k%的激活最大的神经元,正向传播时把其他的置零,BP的时候也不更新除了k%以外的神经元。
At test time, we turn off the sparsity constraint and the output of the deep ReLU network will be the final representation of the input. 测试时候的策略。
对于大的sparsity level,倾向于学到local 的信息,而小的sparsity level 容易获得可以用于分类的全局信息,当然如果太小也会导致对input不进行分解,也是不期望的。

WTA的模式还可以用于RBM网络
Convolutional Winner-Take-All Autoencoders
Convolutional Winner-Take-All (CONV-WTA) autoencoders 是通过enforce WTA 的 spatial 和 lifetime 稀疏约束来实现的。
A non-regularized convolutional autoencoder learns useless delta function filters that copy the input image to the feature maps and copy back the feature maps to the output.
也就是autoencoder的一个缺陷,如果不加入约束或者正则的话,那么很有可能学出来的就是delta function,也就是尖脉冲,因为尖脉冲可以直接把图像输入复制到fm,然后在复制到输出。

上面就是一个栗子,filter都是近似的delta function,而fm都是某种复制。这样的问题用dropout等正则是没法解决的,因为即使dropout了某些filter,由于其它的还是delta function,所以也能恢复出来,因此需要加更强的约束,强制使得网络学到有代表性的特征。
本文的网络结构如下:(128conv5-128conv5-128deconv11)
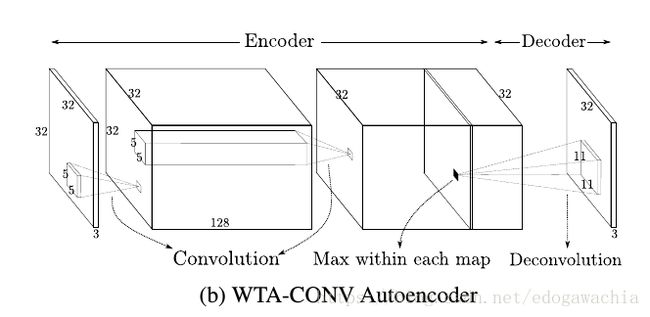
在训练的时候用了两种 winner-take-all 的稀疏约束: spatial 稀疏 和 lifetime 稀疏
spatial sparsity
In the feedforward phase, after computing the last feature maps of the encoder, rather than reconstructing the input from all of the hidden units of the feature maps, we identify the single largest hidden activity within each feature map, and set the rest of the activities as well as their derivatives to zero.
是在feature map中找到 single largest hidden activity。
lifetime sparsity
lifetime sparsity是在feature map中进行选择,由上面的fm的控件稀疏约束可以得到,每个fm都是只有一个点有值。在mini-batch训练的过程中,对于每个fm,都对应有batch_size个,每个都是一个单点的尖脉冲,那么就有batch_size个尖脉冲,那么我们要做的就是在这些尖脉冲里面,再选择k%个最大值,其他的都置零。
其它
另外,作者还提到,这个CONV-WTA还可以用来做building block,级联起来,从而form a hierarchy。
2018年05月10日15:55:03
上班明明是为别人赚大钱,最后竟要谢他给你工作机会,一个人怎么能享受这种鸟日子呢? —— 诗人,查尔斯布考斯基