pytorch学习笔记(Tensor,Variable,nn.Module,optim)
Tensor(张量)

torch.Tensor 默认的是 torch.FloatTensor 数据类型,也可以定义我们自己想要的数据类型
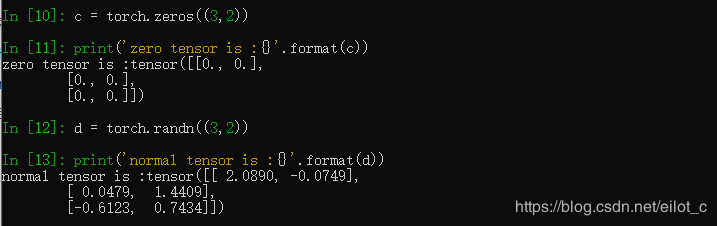
当然也可以创建一个全是0的空的Tensor或者取一个正态分布作为随机初始值
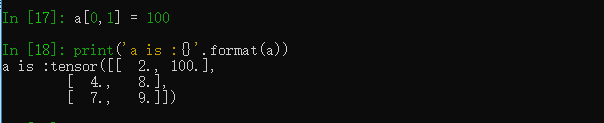
可以像numpy一样通过索引的方式取得其中的元素,同时改变它的值
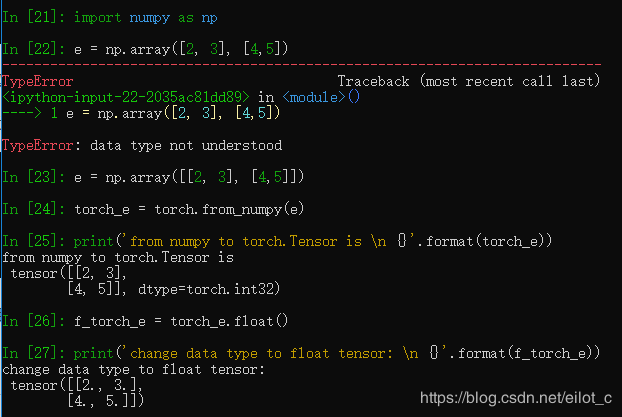
除此之外可以在Tensor和numpy.ndarray之间相互转换:
判断是否支持GPU,如果想把tensor放到GPU上,只要 a_cuda = a.cuda()

Variable(变量)
Variable是神经网络计算图里特有的一个概念,它提供了自动求导的功能.神经网络在做运算的时候首先构造一个计算图谱,然后在里面进行前向传播和反向传播.
Variable和Tensor本质上并没有什么区别,variable会被放入一个计算图中.Variable在torch.autograd.Variable中,要将一个tensor转为Varible十分简单,只需Variable(a).
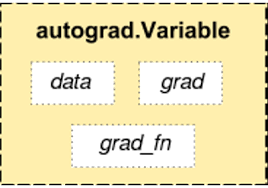 结构图
结构图
data: 通过data可以取出Variable里面的tensor数值
grad:表示Variable反向传播的梯度
grad_fn:表示得到Variable的操作,例如通过加减还是乘除得到的.
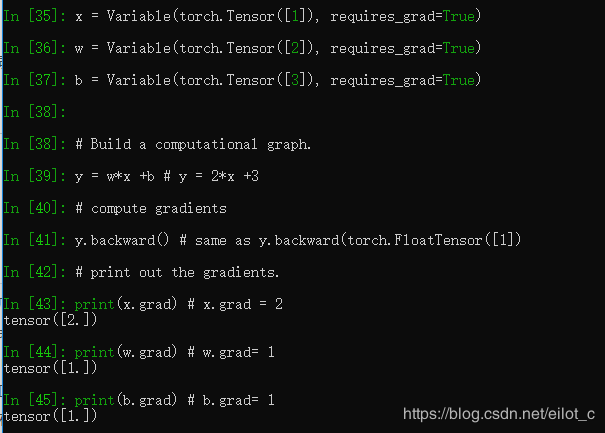
构建Variable, requires_grad=True ,这个表示是否对这个变量求梯度,默认是Fasle.
y.backward()这一行代码就是所谓的自动求导,直接通过这个就可以对所有需要梯度的变量进行求导,得到他们的梯度.然后通过x.grad来得到它们的梯度.
同时也可以做矩阵求导,例如:
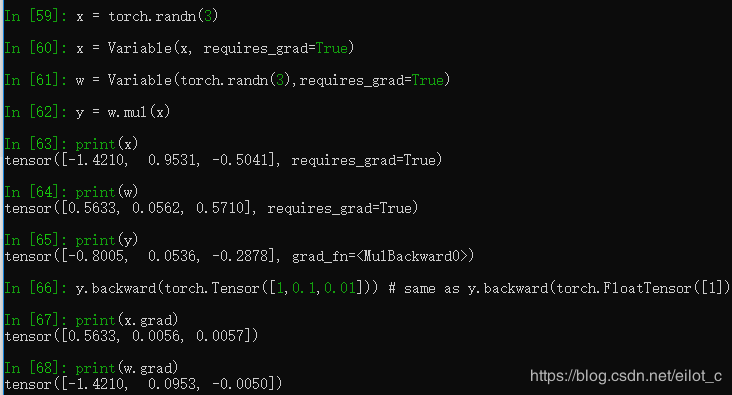
得到的结果是他们每个分量的梯度, y.backward(torch.Tensor([1,0.1,0.01])) ,得到的梯度是他们原有的梯度乘以1 ,0.1 和0.01.
Dataset(数据集)
在处理任何机器学习问题之前都需要数据读取,并且进行预处理.pytorch提供了很多工具使得数据的读取和预处理非常容易.
torch.utils.data.Dataset 是代表这一数据的抽象类.可以定义自己的数据继承和重写这个抽象类.只需要定义_len_ 和_getitem_这两个函数:

通过上面的形式可以定义我们需要的数据类,可以通过迭代的当时来取得每一个数据,但是这样很难实现取batch,shuffle或者多线程取读取数据,所以pytorch中提供了一个简答的办法;来做这件事情,通过torch.utils.data.DataLoader来定义一个新的迭代器,如下:

shuffle 是打乱或者洗牌. collate_fn 表示如何取样本.,我们可以定义自己的函数来实现所需要的功能,默认的函数一般情况下都是可以使用的.
另外torchvison这个包里面有关于计算机视觉的数据读取类,ImageFolder,主要功能是读取图片,且对图片的存放形式有要求:
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/124.png
root/cat/125.png
dset = ImageFolder(root='root_path', transform=None, loader=default_loader)
![]()
root为根目录,在这个目录下有几个文件夹,每个文件夹代表一个类别:transform和target_transform是图片增强; loader是图片读取的办法去,我们读取的是图片的名字,然后通过loader将图片转化成我们需要的图片类型进入神经网络.
nn.Module(模组)
在Pytorch里面编写神经网络,所有的成结构和损失都是来自torch.nn,所以所有的模型构建都是从这个基类nn.Moodule
继承的,于是有了下面的这个模板.
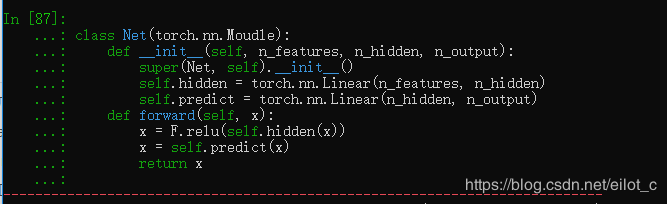
这样就建立了一个计算图,并且这个结构可以复用多次,每次调用就相当于该计算图定义的相同参数做了一次前向传播,因为pytorch的自动求导功能所以我们不需要自己编写反向求导函数,而所有的网络层都是由这个包得到的.
需要通过nn这个包来定义us你hi函数,常见的损失函数都已经定义在了nn之中,例如均方误差,多分类的交叉熵等等,那么如何使用这些损失函数呢?

求得我们的输出和真实目标之间的损失函数
torch.optim(优化)
在机器学习或者深度学习中,我们要通过修改参数来使得损失函数最小化(或者最大化),
1.一阶优化算法
这种方法使用各个参数的梯度值来更新参数,最常用的一届优化算法是梯度下降,所谓的梯度就是导数的多变量表达式,函数的梯度形成了 一个向量长,同时也是一个方向,在这个方向上方向导数最大,且等于梯度.梯度下降的功能是寻找最小值,控制方差,来更新模型的参数最终来使得收敛,网络的更新公式是:
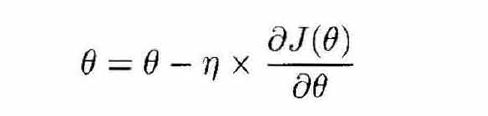
这是深度学习里最常用的优化方法
2.二阶优化算法
二阶优化算法使用了二阶导数(也叫Hessian方法) 来最小化或者最大化损失函数,主要基于牛顿法,但是计算成本很高,所以没有被广泛使用.torch.optim是一个实现各种优化算法的包,大多数的算法都能通过它直接调用,比如随机梯度下降,自适应学习率等等.调用的时候将需要优化的参数传入,这些参数都必须是Variable,然后传入一些基本的设定,比如学习率和动量.
![]()
![]()
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.9)
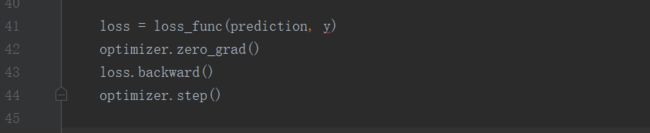
学习率为0.01,动量为0.9的随机梯度下降,下降之前需要将梯度归为0,然后在进行反向传播,自动求导得到每个参数的梯度,最后只需要 optimizer.step() 就可以通过梯度做进一步参数更新
模型的保存和加载
在pytorch里面使用torch.save来保存模型的结构和参数,有两种保存方式:
(1) 保存模型的结构信息和参数信息,保存的对象时模型的状态,保存的对象时模型model;
(2) 保存的对象是模型的状态 model.stae_dict()
可以这样保存,save的第一个参数是保存对象,第二个参数是保存路径以及名称:

torch.save(net1, "net.pkl") # entire net 整个神经网络保存
torch.save(net1.state_dict(), 'net_params.pkl') # parameters 保存神经网络中的参数加载模型的也有两种方式与之对应:
(1) 加载完整的模型结构和参数信息,使用load_model = torch.load('model.pth'), 在网络比较大的时候加载时间 比较长,同样存储空间也比较大;
(2) 加载模型的参数信息,需要先导入模型的结构,然后通过 model.load_state_dic(torch.load('model_state.pth')) 来导入

参考: 深度学习入门之PyTorch(廖星宇)
莫凡的PyTorch https://morvanzhou.github.io/tutorials/machine-learning/torch/