【论文笔记】时空域特征学习的反思:视频分类中速度与精度的权衡
论文链接:
rethinking spatiotemporal feature learning: speed-accuracy trade-offs in video classification
Google Research & University of California San Diego
1. 文章想回答的3个问题
- 我们是否真的需要3d conv? 如果需要的话,哪些层我们应该让他是3d的,哪些层可以是2d的?这个设置依赖于特定的数据集和任务吗?
- 在时间和空间维度上联合做卷积是否很重要?还是说单独在时间和空间维度上分别做卷积也是足够用的?
- 我们如何用上述问题的答案来提升算法的精度,速度和内存占用呢?
围绕这3个问题,组织的实验有:
为了回答第一个问题,本文在I3D的基础上进行network surgery.
(1) Bottom-Heavy-I3D:在网络的低层级使用3D时域卷积,在高层级使用2D卷积
(2) Top-Heavy-I3D:在网络的低层级使用2D卷积,在高层级使用3D时域卷积。
我们发现Top-Heavy-I3D模型更快,这个不难理解,因为它只在抽象层的feature map上进行3D,这些feature map往往比低层级的feature map尺寸上更小。另一个发现是Top-Heavy-I3D模型通常还更加精确,这还挺惊讶的,因为毕竟它忽略了低层级的motion cues(见2.2节)。
为了回答第二个问题,我们将3D conv用 2D spatial conv + 1D temporal conv代替(称它为S3D, separable 3D CNN,思想和R(2+1)D,P3D是一样的)。S3D通常比标准的3D conv参数少很多,计算上也更加高效。惊讶的是,它也比原始的I3D模型更加高精度。实验结果显示从seperable conv得到的效果增益和从top-heavy网络设计得到的效果增益相当(见2.4节)。
为了回答第三个问题,我们将以上两个问题的答案结合,设计了一种新的网络结构 S3D-G,spatio-temporal gating mechanism。在Kinetics,Something-something,UCF101,HMDB等数据集上都比baseline方法的精度更高。(见2.6节)
2. Network surgery

2.1 将所有3D conv替换成2D conv
将I3D中所有的3D conv替换成2D conv,如图Fig.2(a)(b)所示。然后在kinetics Full和something-something上进行训练测试。训练时都是按照正常的帧顺序输入,测试时考虑正常序和倒序两种帧顺序。结果如Table 1所示。

我们可以发现I2D的表现在正常序和倒序是稳定的,这符合续期。而I3D在Kinetics-Full数据集上正常序和倒序表现一致,而在Something-something数据集上倒序的精度低很多。我们认为这是因为Something-something这个数据集需要更细致的特征来区分视觉信息上非常相似的动作类别,例如“Pushing something from left to right” 和“Pushing something from right to left”。
2.2 将部分3D conv替换成2D conv
虽然我们从2.1的实验中看到3D conv能够提高精度,但是它的计算量太大了。所以在本节中,我们讨论将部分3D conv替换成2D。我们以I2D作为起点,从低层级逐渐向高层级inflate 2D conv到3D,来得到Bottom-Heavy-I3D。同样我们也从高层级逐渐向低层级inflate 2D conv到3D,来得到Top-Heavy-I3D。
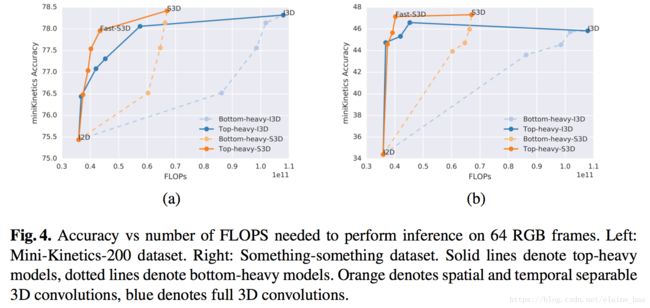
我们在Mini-Kinetics-200和Something-something数据集上训练和测试,结果如Fig.4所示,蓝色实线(top heavy I3D)比蓝色虚线(bottom heavy I3D)在相同的FLOPS下的acc高很多。top heavy I3D的速度优势是先天的(在小的feature map上进行计算),同时Top-Heavy-I3D也比Bottom-Heavy-I3D在精度上更有优势,这可能说明3D conv对于在高层更具语义的层级里建模时间特征更加有效。
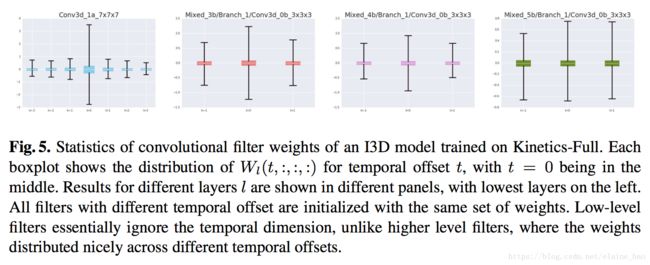
2.3 分析learned filters的权重分布
为了验证上述观察,我们分析了在Kinetics-Full上训练的I3D模型的权重。Fig.5展示了不同层的权值的分布,可以看到低层级来看,权重还是主要分布在t=0的位置的feature map上,对于t≠0的位置权值还是接近于0,说明低层级的filter忽略了时间维度的信息。而在高层级,权重在不同时刻的分布比较平衡,说明高层级的时间信息比较能被I3D捕捉到。
2.4 将temporal conv和spatial conv分离开
每个3D conv被分解成1个2D conv+1个1D conv,这样I3D就被改造成了S3D,如图Fig6所示。
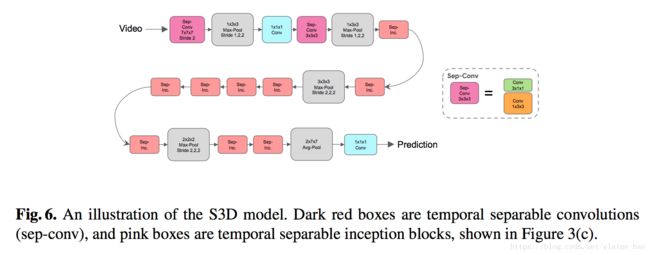
Table 2,3对比了Kinetics-Full、Something-something上S3D和I3D的结果。S3D精度高,参数少,FLOPS小。我们认为这种acc上的增益是因为spatial-temporal的分解有利于减少overfitting,同时并没有降低模型的表达能力(我们发现单纯减少模型的参数对性能提升没有帮助)。

注意这种拆分的操作可以在任意3D conv上进行,因此Bottom-Heavy-I3D的拆分版本是Bottom-Heavy-S3D, Top-Heavy-I3D的拆分版本是 Top-Heavy-S3D。它们之间的性能对比如Fig4所示,我们发现seperate top-heavy模型能够在速度-精度之间做出很好的trade-off。另外,如果我们保留top 2 层为separable 3D conv,剩余的都是2D conv,我们发现速度-精度之间trade-off最好,称其为Fast-S3D。
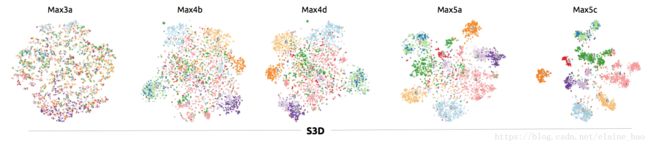
2.5 tSNE工具可视化features
我们用tSNE来可视化S3D模型不同层级的spatialtemporal的表示。我们用了10个类别(0: Dropping [something], 1: Moving [something] from right to left, 2: Moving [something] from left to right, 3: Picking [something], 4:Putting [something], 5:Poking [something], 6: Tearing [something], 7: Pouring [something], 8: Holding [something], 9: Showing [something].)进行可视化。如Fig.7所示,发现S3D模型从Max3a到Max5c,类别的可区分性在高层级越来越清楚。
2.6 Spatial-temporal feature gating
视频分类中最先用到的context feature gating[23]的表达式如下:
y = σ ( W x + b ) ⊙ x y=\sigma(Wx+b)\odot x y=σ(Wx+b)⊙x
⊙ \odot ⊙表示elementwise的相乘, W ∈ R n ∗ n , b ∈ R n W \in \mathbb{R}^{n*n}, b \in \mathbb{R}^n W∈Rn∗n,b∈Rn。这个机制使得模型可以upweight x中特定的维度,如果 y = σ ( W x + b ) y=\sigma(Wx+b) y=σ(Wx+b)预测它们为重要。也可以downweight一些不重要的维度。这可以看成是self-attention的机制。
我们将这一思想扩展到feature tensors,加入spatial-temporal的结构。令X为输入tensor,Y是相同尺度的输出tensor。将上述Wx替换成Wpool(x),pooling是在x的时间空间维度上做平均(我们发现这样做比单独在时间或者空间维度上做平均更好)。然后计算 Y = σ ( W p o o l ( x ) + b ) ⊙ x Y=\sigma(Wpool(x)+b)\odot x Y=σ(Wpool(x)+b)⊙x,其中 ⊙ \odot ⊙表示在channel维度上做乘积。
我们将这个gating的操作接在S3D每个temporal conv的后面得到了最好的结果,称其为S3D-G。我们在Table2中看到S3D-G在Kinetics-Full上比S3D高了2.5% top-1 acc,同时计算量相差不大(66.38 GFLOPS to 71.38),同样Table3也显示S3D-G比S3D效果更好。另外比现在的state-of-art方法Multi-scale TRN高了很多。
3. 泛化性
再来看一下S3D-G在别的数据集,模型,任务上的表现。
3.1 使用光流进行训练
从Table4中看出S3D-G Flow相比于I3D Flow的表现和S3D-G RGB相比于I3D RGB的表现基本一致(都提升了3-4个点)。

3.2 在别的视频分类数据集上finetuning
在Kinetics上训完后在HMDB-51,UCF101上finetuning的结果如Table5所示。

3.3 视频中时空域的动作检测
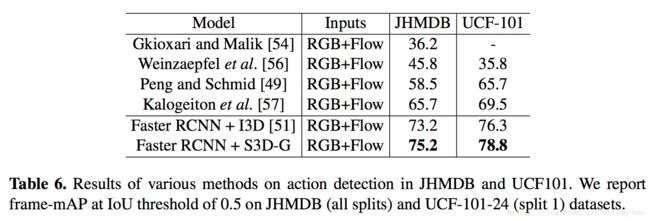
视频时空域的动作检测是指输入视频帧,输出带bbox和action label的帧。参考faster-rcnn的结构,训练时使用2D res50对有标注bbox的关键帧进行特征提取,用于生成region proposal。然后使用3D网络,(如I3D、S3D-G)将关键帧的相邻帧作为输入,然后提取feature map用于bbox分类。2D的region proposal network和3D的action classification network是端到端进行训练的。Table 6是结果。
4.总结
这篇文章的主要亮点是分析了在I3D的基础上的多种变形,试验下来主要有3个要点比较重要,使其在精度和效率上有大幅度提升。
- top-heavy的结构
- temporal separable conv
- spatial-temporal feature gating
其实这些想法在别的文章中都有提出过,只是本文做了系统的整理和实验,是篇很有参考价值的文章。