Wolf从零学编程-用Python打造简单加密程序(二)
我的小程序已经搞定了hash计算和DES加密部分,这次把DES解密搞定,再进行一些改进和整合。
一、使用DES进行解密
这一步和上一篇中使用DES加密是对应的。
但是在写代码前我思考了一个问题:程序怎么判断要进行解密的依据是什么?文件特征?或是用户选择指令?最终我决定依靠用户选择,原因如下:加密后添加des的后缀只是我为了易识别才加的,一般加密过的文件没有明确的算法判断特征。
为了完整的测试加解密过程,我新建了一个word起名’des_en.doc’,内容只有一句话“DES加密”

紧接着就运行加密,得到了des_en.doc.des。


我先解决最简单的问题,就是解密,代码很简单,几乎和加密一模一样。
# -*- coding:utf-8 -*-
import pyDes
#解密
def decryptfile(file): #函数名变成解密
key = str(input('请输入8字节密钥:'))
IV = str(input('请输入8字节初始值:'))
des = pyDes.des(key,pyDes.CBC,IV,pad=None,padmode=pyDes.PAD_PKCS5)
with open(file,'rb') as f1:
data = f1.read()
M = des.decrypt(data) #我要得到明文,就换个变量名
with open(file+'.doc','wb') as f2: #方便打开,添加后缀
f2.write(M) #把明文写进word
f2.close()
f1.close()
file = input('输入文件路径:')
decryptfile(file) #调用解密函数
代码的注释已经标明和加密函数不同的地方,解密时要使用相同的密钥和初始值,这也是对称加密的要求。
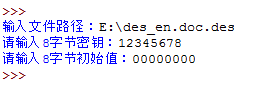
稍等个几秒后,解密后的文件就生成了,现在我同时有3个文件。

并且原始文件和解密文件是完全一致的。

二、DES部分改进
之前的加解密看起来似乎是OK了,但是我还有几个问题要解决:
- 新文件的名字不能每次都加个后缀啊,最好加密后的文件和源文件从外表上是分辨不出来的
- 加密和解密函数几乎完全相同,看来我还需要至少一个函数,用来那些重复的代码
- 运行过几次代码,每次新的文件都会直接覆盖已存在文件,我想让程序可以判断当前目录是否有重名文件
先解决第一个问题:新文件命名。
我想到这么两个方案:
- 保持后缀名不变,在文件名上随便加点什么
- 保持整个文件的名字都不变。这就涉及到更改路径,等于要加个新功能,不考虑它
那么最简单的办法出炉:后缀不变,文件名尾部简单的添加一个’(2)’
pathname = file.split('.')[0] #得到文件名
lastname = file.split('.')[1] #得到后缀
with open(pathname + '(2)' + '.' + lastname,'wb') as f2:
f2.write(M)
f2.close()
file.split(’.’)以’.‘为分隔符(不包含引号),将file分割并返回分割后的列表,默认情况下会进行所有可能的分割,所以前面生成的新明文文件’E:\des_en.doc.des.doc’,分割后会返回
['E:\\des_en', 'doc', 'des', 'doc'],‘E:‘多了个反斜杠,是因为Python中’‘是转义字符,’\‘表示的就是’’。我的考虑是第一个后缀应该是原始文件的后缀,因此以它为新文件后缀。
阅读中文文档str.split及官方文档str.split了解split()更多的用法。
把加解密函数对应部分改成这段代码就OK了。下图中有’(2)‘的是密文,’(2)(2)'的是和源文件相同的明文。

密文文件打开时的画风是介样的:

这画面怎么感觉工作中常见呢?~~
接下来解决第三个问题:重名文件
这个问题和新文件命名是同时出现的,因此先搞定它。
因为目前默认是同路径生成,我的想法是每次新文件命名后,带着路径判断是否有重名文件,如果有就递增更改新文件名,最后再人性化的告诉用户哪一个是新文件。
因此如果固定的使用’(2)’,可能会有某个文件的尾巴上有一串’(2)’,那就太二了。我定义了一个递增的变量来实现。
import os
...
pathname = file.split('.')[0]
lastname = file.split('.')[1]
count = 0
newname = pathname + '(%d)'%count + '.' + lastname
#若存在同名文件,则count自增1,newname重新生成
while os.path.isfile(newname):
count += 1
newname = pathname + '(%d)'%count + '.' + lastname
with open(newname,'wb') as f2:
...
这样一来文件查重和命名就同时完成了。此时若单独看解密函数是这样子的:
# -*- coding:utf-8 -*-
import pyDes
import os
#解密
def decryptfile(file):
key = str(input('请输入8字节密钥:'))
IV = str(input('请输入8字节初始值:'))
des = pyDes.des(key,pyDes.CBC,IV,pad=None,padmode=pyDes.PAD_PKCS5)
with open(file,'rb') as f1:
data = f1.read()
M = des.decrypt(data)
pathname = file.split('.')[0]
lastname = file.split('.')[1]
count = 0
newname = pathname + '(%d)'%count + '.' + lastname
while os.path.isfile(newname):
count += 1
newname = pathname + '(%d)'%count + '.' + lastname
with open(newname,'wb') as f2:
f2.write(M)
f2.close()
print('新文件是:%r'%newname)
f1.close()
file = input('输入文件路径:')
decryptfile(file)
简单进行了测试:
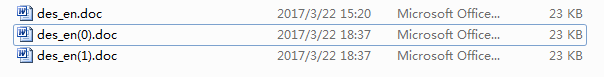
可以看到,连续两次对明文加密,生成了不同名的密文文件。
最终问题:DES整合
这是针对前面提到的第二个问题:相同语句太多。
起初我准备让DES变成一个类,里面3个方法,一个做数据初始化,一个加密,一个解密。经历了数次更改,最终只写出一个函数:
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
import pyDes
import os
def DES(file,mode):
'''
mode==0:加密
mode==1:解密
'''
#以下数据初始化
key = str(input('请输入8字节密钥:'))
IV = str(input('请输入8字节初始值:'))
des = pyDes.des(key,pyDes.CBC,IV,pad=None,padmode=pyDes.PAD_PKCS5)
#以下给新文件命名
pathname = file.split('.')[0] #获得源文件名
lastname = file.split('.')[1] #获得源文件后缀,选取第一个后缀
count = 0 #自增变量,文件名查重后生产新文件名
#新文件名=源文件名+加解密模式+count+'.后缀'
newname = pathname + '-mode-%d-(%d)'%(mode,count) + '.' + lastname
#查重后生产新文件名
while os.path.isfile(newname):
count += 1
newname = pathname + '-mode-%d-(%d)'%(mode,count) + '.' + lastname
#以下根据用户选择进行加密或解密
with open(file,'rb') as f1: #以二进制只读模式打开源文件
data = f1.read() #读取文件数据
#加密数据
if mode == 0:
print('加密中,请稍候...')
information = des.encrypt(data)
#解密数据
else: #mode不是0,就只可能是1
print('解密中,请稍候...')
information = des.decrypt(data)
with open(newname,'wb') as f2:
f2.write(information)
f2.close() #操作完成后,打开的文件要关闭
print('新文件是:%r' % newname) #十分人性化告诉用户新文件是哪个
f1.close()
file = input('输入文件路径:')
mode = int(input('输入模式(0为加密1为解密):')) #mode转换成整数
#mode非0即1,由UI中用户选择,未选择则加解密按钮不可用
DES(file,mode)
对于这段代码,有以下几点:
- 养成良好习惯,第一行声明脚本语言(虽然windows用不着),第二行声明编码类型
- 除了mode控制加密或解密,其他代码都是前面代码的重组
- DES暂时定型,最后写UI时配合修改
现在运行代码分别进行一次加密和解密如下:

表现正常:

想了很久,要从名字上分辨出明文文件和密文文件,我只能做到依靠最后一个mode,前面名字里的要删掉就有点太麻烦了。
以上,DES收工!
RSA的任务推迟~~~