架构设计及核心组件
从总体上看,Cloud Foundry 的架构如图1 所示。经过不断的发展,Cloud Foundry 的组件增加了很多。但核心组件并没有变化,增加的组件是原架构基础上的细化和专门化。Stager 组件解决了打包(Stage)过程需要操作大量文件且操作时间长的问题,所以它作为独立进程,使打包工作异步进行,不阻塞作为核心组件的Cloud Controller。下面是对Cloud Foundry 核心组件的描述。Router。顾名思义,Router 组件在Cloud Foundry中是对所有进来的请求进行路由。进入Router 的请求主要有两类。

图1 Cloud Foundry的架构图
第一类是来自VMC Client 或者STS 的,由Cloud Foundry 使用者发出,叫作管理请求。这类请求会被路由到Cloud Controller 组件处理。第二类是对所部署的App 的访问请求。这部分请求会被路由到App execution,即DEA 组件中。简单地说,所有进入Cloud Foundry 系统的请求都会经过Router 组件。Router 组件是可扩展的,由多个 Router 共同处理进来的请求。但如何对Router 做负载均衡不属于Cloud Foundry 的实现范围,Cloud Foundry 只须保证所有Router 都可以处理任何请求,而管理员可用DNS 实现负载均衡,也可部署专用硬件来实现,或者简单点,弄个Nginx 做负载均衡。
在第一个版本中,Router 工作由router.rb 来做,所有请求都必须经过Ruby 代码处理转发。这个设计简单直接,只是容易引起性能问题,新版中做了如下改进,如图2 所示(左侧为第一版本,右侧为新版)。

图2 Router工作过程(新旧版对比)
使用Nginx 的Lua 扩展,在Lua 中加入URL查询和统计的逻辑。如果Lua 不知道当前的URL 应该路由给哪一个DEA,则会发一个查询请求到router_uls_server.rb(也就是图3 中的“Upstream Locator SVC”)。router_uls_server.rb是一个简单的Sinatra应用,它存储了所有URL 与DEA IP:Port 对应关系。另外,它也管理了请求的Session 数据。

图3 DEA模块架构图(新旧版对比)
这样一来,大量的业务请求在Lua 查询过并保存位置后,都由Nginx 直接转发,不再经过
Router,性能和稳定性都大幅提高。
Router 的设计中有个难点:我们知道HTTP 请求是有上下文的,那如何保证请求的上下文完整呢?简单说就是如何保证有上下文的请求每次都可以找到同一个DEA 处理?Cloud Foundry 是支持Session 的,当Router 发现用户请求中带了Cookie 信息,它会在Cookie 里暗藏一个应用实例的id。当有新请求时,Router 通过解析Cookie 得到上次的应用实例,然后转发到同一台DEA 上。这信息与上面的查询类似,会先存在于Upstream Locator SVC 中,当Lua 知道后会保存在Nginx内部提高效率。
DEA (Droplet Execution Agency)。首先要解释下什么叫做Droplet。在Cloud Foundry 中,
Droplet 指把提交的源代码及Cloud Foundry 配置好的运行环境(如Java Web 就是一个Tomcat),再加一些控制脚本,如start/stop 等,全部打包在一起的tar 文件。Staging App 是指制作Droplet,然后把它存储起来的过程。Cloud Foundry 会保存这个Droplet,直到启动(start)一个App 时,一台部署了DEA 模块的服务器会来拿这个Droplet的副本去运行。因此,如果将App 扩展到10 个实例(instance),那么这个Droplet 就会被复制10 份,供10 台DEA 服务器运行。
图3 是DEA 模块的架构图(左侧为第一版本,右侧为新版)。
Cloud Foundry 刚推出时,用户部署的应用可以在内网畅通无阻,跑满CPU,占尽内存,写满磁盘。因此,Cloud Foundry 开发出了Warden,用这个程序运行容器解决这一问题。这个容器提供了一个隔绝环境,Droplet 只可以获得受限的CPU、内存、磁盘访问权限和网络权限。
Warden 在Linux 上的实现是将Linux 内核的资源分成若干个namespace 加以区分,底层的机制是CGROUP。这样的设计比虚拟机性能好,启动更快,也能够获得足够的安全性。
DEA 的运行原理没有发生根本改变:Cloud Controller 模块会发送start/stop 等基本的App管理请求给DEA,dea.rb 接收这些请求,然后从blobstore 下载合适的Droplet。前面说到Droplet是一个带有运行脚本和运行环境的tar 包,DEA只需要把它拿过来解压,并执行里面的start 脚本,就可让应用运行起来,App 也就可以被访问了。换句话说,就是这台服务器的某一个端口已经在待命,只要有request 从这个端口进来,这个App就可以接收并返回正确的信息。
接着,dea.rb 要做以下一些善后的工作。
把这个信息告诉Router 模块(前面说到,所有进入Cloud Foundry 的请求都是由Router 模块处理并转发的,包括用户对App 的访问请求。一个App 运行起来后,需要告诉Router,让它根据负载均衡等原则把合适的请求转进来,使这个App的实例能够干活)。一些统计性的工作,例如要把这个用户又新部署了一个App 告诉Cloud Controller,以作quota控制等。把运行信息告诉Health Manager 模块,实时报告该App 的实例运行情况。
另外,DEA 还要负责部分对Droplet 的查询工作。例如,如果用户通过Cloud Controller 想查询一个App 的log 信息,那么DEA 需要从该Droplet 里面取到log 返回等。
Cloud Controller。Cloud Foundry 的管理模块。简单来说,就是与VMC 和STS 交互的服务器端,它收到指令后发消息到各模快,管理整个云的运行,相当于Cloud Foundry 的大脑。
以部署一个App 到Cloud Foundry 为例。在输入push命令后,VMC开始工作,在做完一轮用户鉴权、查看所部署的App 数量是否超过预定数额、问了一堆相关App 的问题后,需要发4 个指令。
发一个POST 到“apps”,创建一个App;发一个PUT 到“apps/:name/application”,上传App;发一个GET 到“apps/:name/”,取得App 状态,查看是否已启动;如果没有启动,发一个PUT 到“apps/:name/”,使其启动。
第一版的Cloud Controller 是基于Ruby on Rails的,新版的Cloud Controller 用Sinatra 进行了重写,并把部分工作独立成组件, Cloud Controller变得更轻。另一个重要的改进是,第一个版本的Droplet 是通过NFS 共享的,这样会带来安全、性能等方面的问题,新版中采用了自己开发的blobstore 存放Droplet。
随着Cloud Foundry 逐渐成熟,权限管理功能在新版本中逐渐完善。在原有的用户模型基础上,加入了组织和用户空间等概念,细化了管理模型。用户模型的认证是由UAA 模块实现的。在企业环境中,如果用Cloud Foundry 的开源代码搭建私有云,它可以与企业已有的认证系统进行整合,例如LDAP、CAS 等。权限控制是由ACM 模块实现的。图4 给出了用户访问Cloud Controller 某个API 的过程。
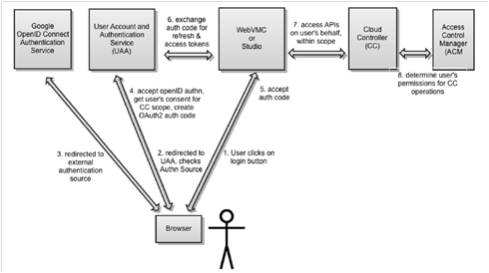
图4 用户访问Cloud Controller某个API的过程
Health Manager。它做的事情不复杂,简单地说是从各个DEA 拿到运行信息,然后进行统计分析、报告、发出告警等。
Services。服务应属于PaaS 的第三层。Cloud Foundry 把Service 模块设计成一个独立的、插件式的模块,便于第三方方便地把自己的服务整合成Cloud Foundry 服务。在GitHub 上有以下两个相关的子项目值得关注。
vcap-services-base: 顾名思义, 包括CloudFoundry 服务的框架及核心类库。如果开发自定义服务,需要引用到里面的类。vcap-services:目前Cloud Foundry 支持的,包括官方及大部分第三方贡献的服务。这个项目的根文件目录是根据服务名称划分的,可以选择其中自己感兴趣的来研究。
由此可见,Service 模块十分方便为第三方提供自定义服务。从架构来说, Cloud Foundry 服务部分使用了模板方法设计模式,可通过重写钩子方法来实现自己的服务,如果不需要特别逻辑则可以使用默认方法。
现实情况中,种种原因使有些系统服务难以或不愿意迁移到云端,为此Cloud Foundry 引入了Service Broker 模块。
Service Broker 可以使部署在Cloud Foundry 上的应用能访问本地服务。Service Broker 的使用方法如下。
准备被访问的服务。以PostgreSQL 为例,配置好程序和防火墙,让其可以通过类似 postgres://xyzhr:[email protected]:5432/xyz_hr_db 的URI 访问。
注册以上URI 到Service Broker。
使用Service Broker 暴露的服务与使用Cloud Foundry 的系统服务无异,准备被访问的服务中的访问服务的URI 通过环境变量传给App。App通过URI 访问暴露出来的服务,这过程不必通过Service Broker。这个过程如图5 所示,与使用系统服务类似,此处不再赘述。

图5 使用Service Broker所暴露的服务的过程
NATS (Message bus)。 Cloud Foundry 的架构是基于消息发布和订阅的。联系各模块的是一个叫NATS 的组件。NATS 是由Cloud Foundry 开发的一个基于事件驱动的、轻量级的消息系统。它基于EventMachine 实现。第一版本Cloud Foundry 被人诟病的一个问题就是NATS 服务器是单节点的,让人不大放心。新版NATS 终于支持多服务器节点,NATS 服务器间通过THIN 来做通信。NATS 的GitHub 开源地址是:https://github.com/derekcollison/nats。代码量不多但设计很精妙,推荐研究它的源代码。
Cloud Foundry 各种优秀特性均源于消息通信架构。每台服务器上的各模块会根据当前的行为,向对应主题发布消息,同时也按照需要监听多个主题,彼此以消息进行通信。
可以说,Cloud Foundry 的核心是一套消息系统,如果想了解Cloud Foundry 的来龙去脉,跟踪它里面复杂的消息机制是非常好的方法。举个最简单的例子,一个装有DEA 组件的服务器为加强云的计算能力,被加入到Cloud Foundry 集群中,它首先需要表明已准备好随时提供服务,Cloud Controller 可将App 部署到它这里,Router 也可将相关的请求交给它处理;Health Manger 可定时为它体检等,它会发布一条消息到主题“dea.start”:
NATS.publish(‘dea.start’, @hello_message_json)
@hello_message_json包括DEA的UUID、ip、por t、版本信息等内容。Cloud Controller、Router、Health Manger及其他模块会监听这个主题,得到通知,各自干活。
理解Cloud Foundry的最好方法其实是选定某一操作,如部署一个App、创建服务等,以消息为线索,跟踪到各模块,看其如何处理。这样就可以观察到整个Cloud Foundry的工作流程。本专栏第2篇文章将专门介绍如何以NATS为主线理解Cloud Foundry原理,这里就不做过多叙述了。
总结
在过去的一年中,Cloud Foundry发生了很多改变,足可看出Cloud Foundry社区的活跃。非常希望本文已把Cloud Foundry的原理讲得足够明白,但请不要把本文作为参考手册使用,在VMware中国开发者关系团队的努力下,Cloud Foundry的文档相当完善,强烈推荐以其作为参考(网址:www.cloudfoundry.cn)。