最近在优化公司CRM报表系统时发现一个有趣的问题。对学校分组聚合统计后,一旦查询的范围超过一定时长,这个SQL的执行耗时就和原来差10倍以上。线上数据差不多几百万。下面给出一个脱敏后的表结构和存储过程用来模拟。模拟的截图均出自我的虚拟机(2核2G内存)。
建表SQL
CREATE TABLE `dt_school` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`tea_reg` int(11) NOT NULL DEFAULT '0' COMMENT '老师注册数',
`stu_reg` int(11) NOT NULL DEFAULT '0' COMMENT '学生注册数',
`school_id` int(11) NOT NULL COMMENT '学校id',
`time` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间(具体到天)',
PRIMARY KEY (`id`),
KEY `key_school_id` (`school_id`),
KEY `index_time_school` (`time`,`school_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='数据统计-学校统计表'
初始化数据
delimiter //
CREATE PROCEDURE proc_init_dt_school()
BEGIN
DECLARE d INT;
DECLARE sid INT ;
SET d = 20160101;
WHILE d < 20190501 DO
SET sid = 1;
WHILE sid < 1501 DO
insert into dt_school(tea_reg,stu_reg,school_id,time)
value(floor(rand()*100),floor(rand()*100),sid,d);
SET sid = sid + 1;
END WHILE;
SET d = DATE_FORMAT(date_add(d,INTERVAL 1 day),'%Y%m%d');
END WHILE;
END //
delimiter ;
call proc_init_dt_school() ;
多查一天的数据,SQL耗时翻n倍?
线上的SQL大概是这样的
select sum(tea_reg),sum(stu_reg) from dt_school where time between 20160101 and 20160411 group by school_id\G;
执行结果:
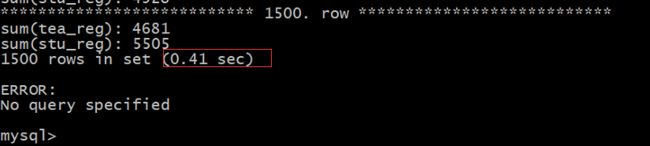
多查一天
select sum(tea_reg),sum(stu_reg) from dt_school where time between 20160101 and 20160412 group by school_id\G;
执行结果

一脸懵逼.jpg , 好吧。对比一下执行计划 :
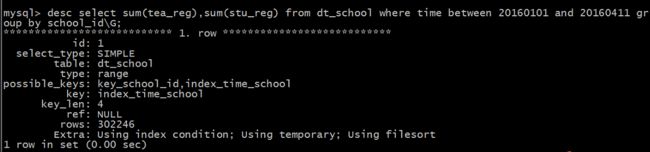
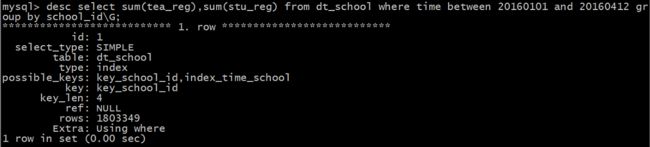
发现一旦查询的时间范围超过了这个节点,MySQL 就会选择school_id这个索引,导致查询缓慢。既然是这样我使用force index 强制使用index_time_school
select sum(tea_reg),sum(stu_reg) from dt_school force index(index_time_school) where time between 20160101 and 20160412 group by school_id\G;


但是对于真实的生产环境,我并不想使用force index 。所以,我决定尝试删掉这个索引,排除它的干扰。(当然线上生成环境,我没有删,因为还有其他业务查询需要用这个索引)
drop index key_school_id on dt_school
再次执行这条查询
select sum(tea_reg),sum(stu_reg) from dt_school where time between 20160101 and 20160412 group by school_id\G;

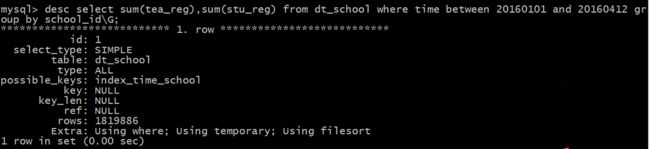
发现删掉key_school_id 这个索引后,MySQL同样不会选择index_time_school 这个索引。但是,我们可以看到,就算不走索引,全表扫描聚合,也只需要0.83s 远快过使用key_school_id索引。
所以, 索引就一定能加快查询吗?不合适的索引还不如不建。
解决方案
我们发现删掉了,key_school_id索引后。MySQL仍然不会选择index_time_school索引,虽然我们可以使用force index() 显式指定索引,但是这并不能从根本上解决问题。因为MySQL不使用这个索引,说明至少从MySQL优化器来看,这个索引使用与否已经没有太大的优化意义了。我们发现一旦这个我们把这个查询范围扩大,耗时就越发明显
select sum(tea_reg),sum(stu_reg) from dt_school force index(index_time_school) group by school_id\G;

这个时候我突然有个想法,鉴于这块业务都是对数据做求和聚合,其实我们可以通过,将数据做月度汇总的方法来解决:
- 建一张与dt_school 一模一样的 dt_school_month
- 定时脚本每个月定时将dt_school的数据分组聚合后插入dt_school_month
- 业务层进行拆分,如果对于一个时间范围20180121-20180402 的查询,切成20180121-20180131, 20180401-20180402(查dt_school表) ,20180201-20180331(查dt_school_month)表
拆分完的SQL查询变为:
SELECT
sum(tea_reg) as tea_reg,
sum(stu_reg) as stu_reg,
school_id
FROM (
(SELECT
sum(tea_reg) as tea_reg,
sum(stu_reg) as stu_reg,
school_id
FROM dt_school
WHERE time BETWEEN 20180121 AND 20180131
GROUP BY school_id)
UNION ALL (SELECT
sum(tea_reg) as tea_reg,
sum(stu_reg) as stu_reg,
school_id
FROM dt_school_month
WHERE time BETWEEN 20180201 AND 20180331
GROUP BY school_id)
UNION ALL (SELECT
sum(tea_reg) as tea_reg,
sum(stu_reg) as stu_reg,
school_id
FROM dt_school
WHERE time BETWEEN 20180401 AND 20180402
GROUP BY school_id))
GROUP BY school_id;
SQL变复杂了,但是 因为dt_school_month 中只有两行汇总数据time=20180228 and 20180331 ,并且dt_school 和 dt_school_month的查询都能走index_time_school索引 ,所以速度上去了。
SQL_BIG_RESULT
刚做完这个月表方案,技术交流群里的大佬梦康就发了篇博文 一次 group by + order by 性能优化分析 也在讲遇到的相似的案例,其中提到一个关键字 SQL_BIG_RESULT 。
我两眼放光,充分发挥一个小白学徒工应有的精神。
看到个锤子,就想拿出来钉几下
select SQL_BIG_RESULT sum(tea_reg),sum(stu_reg) from dt_school where time between 20190101 and 20190412 group by school_id\G;

发现,用上SQL_BIG_RESULT后,这个执行时长也变快了。
还有个未解决的问题是线上脚本机用上SQL_BIG_RESULT比走index_time_school索引还快,线下我用虚拟机复现的话,就稍慢与走index_time_school索引。
我猜可能是因为线上机用固态硬盘的缘故(如果你有调试思路,麻烦告诉我 thx)。
如果测试时发现用上SQL_BIG_RESULT还是比较慢,你可以执行一下语句。
show variables like '%sort_buffer_size%';
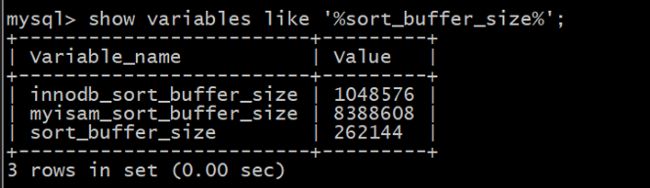
SET GLOBAL sort_buffer_size = 1024*1024*2;
为啥使用SQL_BIG_RESULT能加快查询呢? 先看一下 执行计划

再执行一下
help SQL_BIG_RESULT

假装成一个看得懂英语的人,翻译一下,手册大概是说
SQL_BIG_RESULT或者 SQL_SMALL_RESULT可以与GROUP BY或DISTINCT一起使用 告诉优化器结果集分别有很多行或很少行。使用SQL_BIG_RESULT,MySQL在创建时直接使用基于磁盘的临时表,并且优先对带有GROUP BY元素键的临时表进行排序。使用 SQL_SMALL_RESULT,MySQL使用内存中的临时表来存储生成的表而不是使用排序。
这段话也就是,网上有些博文总结为使用SQL_BIG_RESULT先排序,后分组。不使用SQL_BIG_RESULT, 先分组后排序。
从group by 原理说起
为什么使用了SQL_BIG_RESULT能加快查询,这还得从group by 的原理说起 。这里我要借用一下丁奇老师专栏的图 ,顺带安利一下他的专栏MySQL45讲
group by 的本质其实也是排序
对于
select sum(tea_reg) as t ,sum(stu_reg) as s from dt_school where time between 20190101 and 20190412 group by school_id\G;
这个语句的执行流程是这样的:
1 . 创建内存临时表,表里有三个字段t , s , school_id
- 扫描表dt_school主键索引,依次取出节点school_id和tea_reg, stu_reg,和time 的值。
- 如果time的值不在获取的时间范围内,丢弃。判断内存表中是否已经有school_id值的行,如果没有插入(school_id,tea_reg,stu_reg), 如果有在对应的行加上tea_reg 和stu_reg的值
- 如果依次往内存表插数据的时候,发现内存表已满。新起一个innodb引擎的磁盘临时表,将数据挪到磁盘临时表中。
-
将对临时表的school_id排序,将结果集返回给客户端。
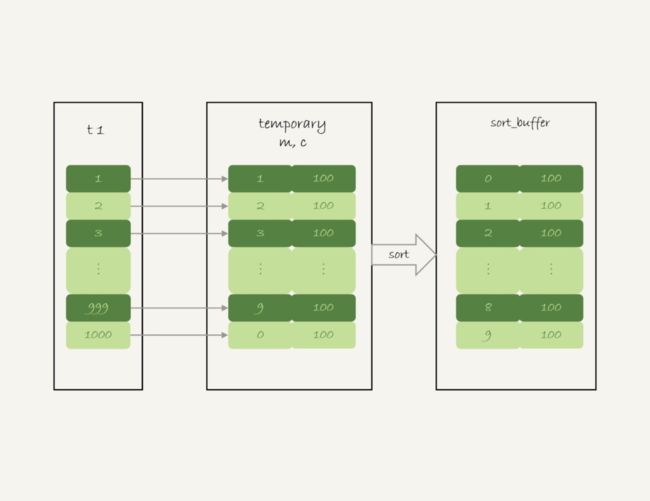 image.png
image.png
 image.png
image.png
其实5这个步骤也不是必须的 。当使用索引school_id来遍历时,插入临时表的数据就默认是有序的,这就是为何数据量一大优化器就要选择school_id索引,因为它总是认为排序是耗时的,而使用school_id是不需要排序的。
所以对于group by a 如果走的不是a 索引,在mysql5.6及以下的操作都是默认对分组后进行排序的,如果你不需要,可以尝试使用order by null 来加快这个查询。
上面这个流程,比较傻的就是第4步了,当内存临时表不够用时,我们再把内存临时表的数据挪到磁盘临时表。
而使用SQL_BIG_RESULT的时候,优化器就会直接使用磁盘临时表
对于
select SQL_BIG_RESULT sum(tea_reg) as t ,sum(stu_reg) as s from dt_school where time between 20190101 and 20190412 group by school_id\G;
这个语句的执行流程是这样的:
- 扫描表dt_school主键索引,依次取出节点school_id和tea_reg, stu_reg,和time 的值。
- 如果time的值不在获取的时间范围内,丢弃。否则插入sort buffer中,如果sort_buffer 不够用,直接使用磁盘临时文件辅助排序
- 对sort buffer 的数据对school_id 进行排序
- 扫描sort buffer 的数据,返回聚合结果

这也就是为啥 查看SQL_BIG_RESULT的语句的执行计划,Extra选项的值,没有使用临时表,但是需要using filesort 。 当然我们加上这个school_id索引的话,这个filesort排序也不需要了。
丁奇老师在专栏里的建议,是优先调高内存临时表的大小(temp_table_size) , 但是没有说明原因。于是 我请教了公司的DBA同学,他是这样说的
表数据少的时候,使用提示符让走文件排序很快,实际上一个表如果十几G,呢,文件排序就很慢很慢
sort buffer是会话变量,线上设置的1M,一般不会给很大,因为如果同时有很连接都在排序就会占很多内存。
数据库是一个整体有限的资源需要均衡分配,不能因为某条语句调整配置。
以上就是对自己工作中关于group by 的总结。由于作者见识有限,文中难免纰漏繁多。欢迎读者交流指正。
参考阅读 :
SELECT Syntax -- MySQL 5.6 Reference Manual
https://dev.mysql.com/doc/refman/5.6/en/group-by-handling.html
https://dev.mysql.com/doc/refman/5.6/en/group-by-modifiers.htmlMySQL执行计划extra中的using index 和 using where using index 的区别 -- Linux 公社
一次 group by + order by 性能优化分析 -- 周梦康
什么时候会使用内部临时表 -- 丁奇
MySQL的优化 -- 老叶茶馆