相对来说,贴吧还是比较好爬一些的,所以就先拿贴吧为例,来做第一个实战。
1 爬前分析
如果要爬取一个网站的内容,我们要先做一般有以下几个步骤:
- 对url进行分析,找到有规律的内容,定义相应的变量;
- 开始爬取内容,对获取的内容进行查看;
- 通过查看,设定正则规则,过滤无用内容;
- 保存我们需要的内容到文件。
2 url分析
因为上大学时候就很迷恋盗墓笔记,一直关注着,所以这次就爬盗墓笔记吧的内容吧,。
2.1 url分段
盗墓笔记吧的一个帖子网址如下:https://tieba.baidu.com/p/4366865181?see_lz=1&pn=1
https:// # 使用的传输协议
tieba.baidu.com # 是百度的二级域名,指向百度贴吧的服务器。
/p/4366865181 # 服务器的路径
see_lz=1和pn=1分别表示只看楼主和页数
所以,url部分我们就分位两部分,基础部分和参数部分,结合到具体例子可以指定
基础部分:https://tieba.baidu.com/p/4366865181
参数部分:see_lz=1&pn=1
2.2 抓取页面
这里就用到了前面讲的urllib模块,下面直接看代码:
# -*- coding: utf-8 -*-
# 爬取百度贴吧楼主发送的文字内容,存储在本地文件中
# 导入模块
from urllib import request
# 定义查看楼主和页数
seelz = '?see_lz=' + '1'
pn = '&pn=' + '1'
# 定义基础url
base_url = 'https://tieba.baidu.com/p/4366865181'
# 定义参数url
arg_url = seelz + pn
# 完整url
url = base_url + arg_url
# 看一下打出来的网址有没有达到预期效果
print(url)
try:
# 添加请求头,我发现贴吧不加头也能获取,不过最好还是加上
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}
# 创建对象
req = request.Request(url, headers=head)
# 打开网址
response = request.urlopen(req)
# 打印结果
print(response.read().decode('utf-8'))
except request.URLError as e:
if hasattr(e, 'code'):
print(e.code)
elif hasattr(e, 'reason'):
print(e.reason)
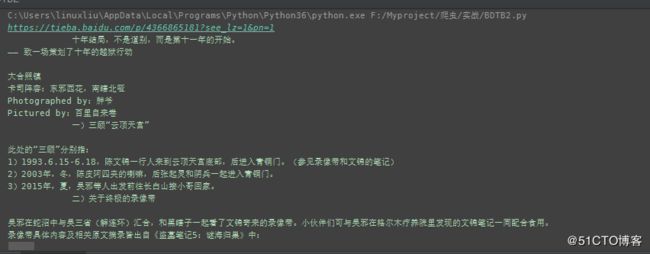
输出结果如下:
可以看出成功获取了网页的内容。
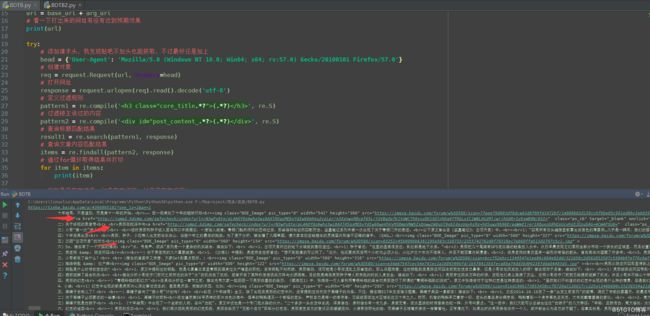
2.3 正则表达式提取信息
接着就是提取对我们有用的信息了,可以分步操作,大事化小,小事化了,我们先提取标题,可以看一下网页的源代码,找到标题(浏览器为火狐):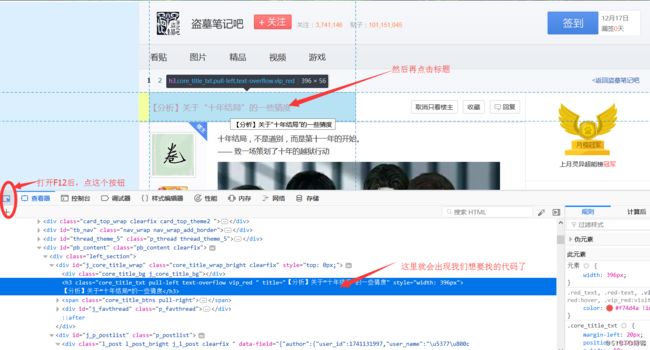
通过上图操作我们可以找到标题部分的代码:
【分析】关于“十年结局”的一些猜度
下面开始写pattern
pattern = re.compile('
(.?)
')含义如下:
代码实现效果如下:
# -*- coding: utf-8 -*-
# 爬取百度贴吧楼主发送的文字内容,存储在本地文件中
# 导入模块
import re
from urllib import request
# 定义查看楼主和页数
seelz = '?see_lz=' + '1'
pn = '&pn=' + '1'
# 定义基础url
base_url = 'https://tieba.baidu.com/p/4366865181'
# 定义参数url
arg_url = seelz + pn
# 完整url
url = base_url + arg_url
# 看一下打出来的网址有没有达到预期效果
print(url)
try:
# 添加请求头,我发现贴吧不加头也能获取,不过最好还是加上
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}
# 创建对象
req = request.Request(url, headers=head)
# 打开网址
response = request.urlopen(req).read().decode('utf-8')
# 定义过滤规则
pattern = re.compile('(.*?)
')
# 查询匹配结果
result = re.search(pattern, response)
# 判断是否存在结果,如果存在打印,如果不存在返回None
if result:
print(result.group(1).strip())
else:
print(None)
except request.URLError as e:
if hasattr(e, 'code'):
print(e.code)
elif hasattr(e, 'reason'):
print(e.reason)
执行结果如下:
好,基本满足我们的需求,那问题来了,如何获取本页所有的内容呢?我们继续,为了节省篇幅,代码只写修改的内容,其它部分和上面相同,如果参数不同,做替换即可
略
# 打开网址
response = request.urlopen(req).read().decode('utf-8')
# 定义过滤规则
pattern1 = re.compile('(.*?)
', re.S)
# 过滤楼主说过的内容
pattern2 = re.compile('