文章转载自 这里
最近在看数学建模的一些算法..一愣一愣的..发现一篇博客讲解得很易懂..转载收藏。转载正文之后可能自己添加一些别的内容。
正文开始
注:文章内容主要参阅 《matlab数学建模算法实例与分析》,部分图片来源于WIKI
文章分为2部分:
- 第一部分以通俗的方式简述一下层次分析法的基本步骤和思想
- 第二部分介绍一下我们队伍数学建模过程中,对层次分析法的应用,中间有些地方做了不严谨的推理,例如关于一致性的检验,如有人发现不正确,希望可以指正
第一部分
层次分析法(Analytic Hierarchy Process ,简称 AHP )是对一些较为复杂、较为模糊的问题作出决策的简易方法,它特别适用于那些难于完全定量分析的问题。它是美国运筹学家T. L. Saaty 教授于上世纪 70 年代初期提出的一种简便、灵活而又实用的多准则决策方法。
人们在进行社会的、经济的以及科学管理领域问题的系统分析中,面临的常常是一个由相互关联、相互制约的众多因素构成的复杂而往往缺少定量数据的系统。层次分析法为这类问题的决策和排序提供了一种新的、简洁而实用的建模方法。
运用层次分析法建模,大体上可按下面四个步骤进行:
(i )建立递阶层次结构模型;
(ii )构造出各层次中的所有判断矩阵;
(iii )层次单排序及一致性检验;
(iv )层次总排序及一致性检验。
这四个步骤中,前两个步骤最容易理解,后两个步骤需要一点时间理解
首先从层次结构模型说起
层次分析法是用来根据多种准则,或是说因素从候选方案中选出最优的一种数学方法
![层次分析法[转]_第1张图片](http://img.e-com-net.com/image/info10/fd6cea3ad4784360ac3d3bac6034f887.jpg)
最顶层是我们的目标,比如说选leader,选工作,选旅游目的地
中间层是判断候选方物或人优劣的因素或标准
选工作时有:发展前途 ,待遇 ,工作环境等
选leader时有:年龄,经验,教育背景,魅力
在分层以后,为了选出最优候选
给目标层分配值1.000
然后将这一值作为权重,分配给不同因素,对应因素的权重大小代表该因素在整个选择过程中的重要性程度
然后对于候选方案,每一个标准再将其权重值分配给所有的候选方案,每一方案获得权重值,来源于不同因素分得的权重值的和
如下图:(alternative1)0.333=0.250/4(criterion1)+0.250/4(criterion2)+0.250/4(criterion3)+0.250/4(criterion4)
最终获得的各个方案的的权重值的和依然为1
![层次分析法[转]_第2张图片](http://img.e-com-net.com/image/info10/976661848ef84f5aa68c66010ccbf364.jpg)
例如选工作时,待遇所占的比重为0.8, 有工作1,2,3候选, 如果工作1的待遇最高,工作2的待遇次之,工作3最差,则可将0.8的值按0.4,0.3,0.1分给工作1,2,3,
这不就是一个简单的权重打分的过程吗?为什么还要层次分析呢。这里就有两个关键问题:
- 每个准则(因素)权重具体应该分配多少
- 每一个候选方案在每一个因素下又应该获得多少权重
这里便进入层次分析法的第二个步骤,也是层次分析法的一个精华(构造比较矩阵(判断矩阵)comparison matrix):
首先解决第一个问题:每个准则(因素)权重具体应该分配多少?
如果直接要给各个因素分配权重比较困难,在不同因素之间两两比较其重要程度是相对容易的
![层次分析法[转]_第3张图片](http://img.e-com-net.com/image/info10/29a4944b16ca45f58ed7b9db296f9c79.jpg)
现在将不同因素两两作比获得的值aij 填入到矩阵的 i 行 j 列的位置,则构造了所谓的比较矩阵,对角线上都是1, 因为是自己和自己比
这个矩阵容易获得,我们如何从这一矩阵获得对应的权重分配呢
这里便出现了一个比较高级的概念,正互反矩阵和一致性矩阵
首先正互反矩阵的定义是:
![层次分析法[转]_第4张图片](http://img.e-com-net.com/image/info10/3325b9c2cf344250af543d4fbfd13be4.jpg)
我们目前构造出的矩阵很明显就是正互反矩阵
而一致性矩阵的定义是:

这里我们构造出的矩阵就不一定满足一致性,比如我们做因素1:因素2= 4:1 因素2:因素3=2:1 因素1:因素3=6:1(如果满足一致性就应该是8:1),我们就是因为难以确定各因素比例分配才做两两比较的,如果认为判断中就能保证一致性,就直接给出权重分配了
到了关键部分,一致性矩阵有一个性质可以算出不同因素的比例

这里的w就是我们想要知道的权重,所以通过 求比较矩阵的最大特征值所对应的特征向量,就可以获得不同因素的权重,归一化一下(每个权重除以权重和作为自己的值,最终总和为1)就更便于使用了。(实际上写这篇博客就是因为,重新翻了线代的书才好不容易理解这里的,就想记录下来)
这里补充一点线性代数的知识:
n阶矩阵有n个特征值,每个特征值对应一个n维特征列向量,特征值和特征向量的计算方法这里就省略了,反正书中的程序是直接用matlab 的eig函数求的
这里不能忘了,我们给出的比较矩阵一般是不满足一致性的,但是我们还是把它当做一致矩阵来处理,也可以获得一组权重,但是这组权重能不能被接受,需要进一步考量
例如在判断因素1,2,3重要性时,可以存在一些差异,但是不能太大,1比2重要,2比3 重要,1和3比时却成了3比1重要,这显然不能被接受
于是引入了一致性检验
一致性的检验是通过计算一致性比例CR 来进行的
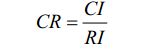
当 CR<0.1 时,认为判断矩阵的一致性是可以接受的,否则应对判断矩阵作适当修正。
CI的值由判断矩阵计算获得,RI的值查表获得,具体的计算公式这里就略去,重点是理解为什么要做一致性检验
接下来解决第二个问题:每一个候选方案在每一个因素下又应该获得多少权重
这里则需要将不同候选方案,在不同因素下分别比较,具体的比较方法,还是使用比较矩阵,只不过之前准则层的比较矩阵比较的对象是因素,这里比较的是某一因素下,候选方案的优劣, n个因素则需构造出来n个比较矩阵
例如在工作环境的因素下,工作1与工作2相比为 :4:2,工作2与工作3=2:1 工作1:工作3=6:1.,这样构造一个矩阵,再用之前的一致性矩阵的方法就可以求出一个权重,然后相对应因素(这里是工作环境)所拥有的权值就可以按这个权重比例分配给不同候选物或人。
其他因素同理
至此两个问题就都得到了解决
最终将每个候选物、人从不同因素获得的权值求和,就可以得到不同候选对于目标层的权值大小,继而可以根据值的大小,来选出优劣
对于第一部分的总结
通过对层次分析法的基本了解,不难发现层次分析法对人们的思维过程进行了加工整理,提出了一套系统分析问题的方法,为
科学管理和决策提供了较有说服力的依据,但很明显的缺点是,整个分析过程似乎都是依赖于人的主观判断思维,一来不够客观,二来两两比较全部人为完成,还是非常耗费精力的,尤其是当候选方案比较多的时候。
文章的第二部分
层次分析法的变形应用(也可能本来就是这样用的,只不过参考书上没这样说,外语
论文没细看)解决最优教练选择问题
目标:选最优教练
准则: 职业生涯所带队伍的胜率
职业生涯所带队伍的胜场
从教时长(年)
职业生涯所带队伍获奖状况(化成分数)
候选: 众多教练
准则层的比较矩阵好构造 ,作6次两两比较,就可以获得4*4的比较矩阵
问题在于候选层的比较矩阵怎么获得,有4000个教练的话,得比4000*3999次,这里就不必人为比较了,引入定量的数据用程序控制作比即可
胜率因素下就用胜率两两作比构造矩阵,从教时长因素下就用年长来做比
这里又有两点可以注意:
不同因素下数据的量纲和性质不一样,直接用数据作比来分配,不一定合适,比如胜率越要接近1越难,0.7比胜率0.5 和胜率0.9比0.7 ,后者比值比前者小,这显然不合适。建模中我们结合了幂函数和对数函数处理。
这里的用定量数据作比获得的矩阵显然满足一致性要求,不需要做一致性检验(想做还不好做,计算CR的值要有RI,RI的值查表只给出9个,计算4000个教练,需要4000个RI呢)
综上就对层次分析法完成了定性定量结合的应用,以及对多个候选方案的比较(其实只是就是用程序控制数据作比,我们水平有限,能成功应用该方法已经不容易了)
很遗憾的是比赛时编写的代码存放的优盘不慎丢失, 没有办法把代码共享出来, 这里只能将书中的代码贴出。比赛建模时, 就是在这个代码基础上进行修改实现。 只要理解了下列代码,编写符合自己需求的程序, 应当是水到渠成的事。
正文结束