Image Super-Resolution Using Deep Convolutional Networks by Chao Dong, et al.
概要:我们为图像提出一种基于深度学习的图像超分辨率重构方式。这种方式直接学习低/高分辨率之间的端到端映射。这种映射表现为一个以低分辨率图像为输入,输出高分辨率图像的深度CNN。我们发现传统的基于稀疏编码的图像超分辨率重构方法也可以被看作一个深度卷积网络。但与传统方式分块独立处理的方法不同,我们的方法联合优化所有层。我们的CNN模型结构是轻量级的,但却展示出高水准的恢复水平,且在实际的在线使用中处理速度很快。我们探索了不同的网络结构与参数设置以在处理效果与处理速度找到平衡。此外,我们拓展了模型以同时应对三通道彩色图像,并且达到了较好的重建效果。
1.介绍:单张图片超分辨率处理(目的在于从低分辨率图像恢复出高分辨率图像),是计算机视觉领域的经典问题。这个问题本身是不适定的,因为对于给定的任意低分辨率像素都存在多解。换句话来说,这是一个欠定的,解不唯一的反问题。对这类问题通常需要利用强先验信息约束解空间。当今领先的技术大多采用基于实例的方法学习先验信息,要么发掘同一张图像的内部相似性,要么学习外部样例低/高分辨率图像对之间的映射函数。后者的方式可以被用于更通用的图片超分辨率处理中,也可以经过改进后适应具体领域的任务,例如:参考给出的训练样例的人脸幻想。
基于稀疏编码的方法就是其中很有代表性的一种(采用基于外部样例的图像超分辨率重构方法)。采用这种方法处理图像的过程涉及多个步骤。首先,对输入的图像中密集切割部分重叠的像素块,并作预处理(例如,减去均值和标准化处理)。然后用低像素编码词典编码这些小块。稀疏系数则被传入高像素编码词典用于重建高像素的像素块。重建后的重叠像素块则被聚合在一起(例如,使用加权平均算法)产生最终的输出。大部分基于外部实例的方法都采用这个流程,这个流程专注于学习与优化编码词典,或者专注于构建有效率的映射函数。然而,流程中其他的步骤在整个优化框架中很少被优化甚至很少被纳入考虑。
在这篇论文中,我们说明了以上流程等价于一个深度CNN。因此我们考虑一个直接学习低/高分辨率图片之间映射的端到端映射的CNN。我们的方法从根本上区别于现存的基于外部样例的方法,因为我们的方法不是显性地学习用于模拟像素块空间的编码词典或者集合,而是隐性地通过隐藏层来达到目的。而且,像素块的提取与聚合也用卷积层来构造,也因此被包含在优化流程中。在我们的方法中,整个超分辨率处理流程通过学习来完成,几乎没有预处理与后加工工作。我们将模型命名为超分辨率CNN(SRCNN)。所提出的SRCNN有若干个优良特性。首先,对SRCNN的构造是精心设计的,因此可以达到超出现有方法表现的优良的准确率,Firgure 1 展示了对同一个例子的处理效果对比。

第二,在过滤器与网络层数适量的条件下,我们的方法在实际的在线使用过程中达到了很快的速度,即使是在CPU上运算。我们的方法比其他许多基于外部实例的方法都快,因为它完全是前馈的,而且在使用过程中不需要解决任何优化问题。第三,实验结果表明,网络的恢复能力通过以下措施还可以进一步改善:i)拥有更大更多样的数据集;ii)使用更大更深的模型。而且,我们提出的模型同时也可以应对三通道彩色图像,得到更好的超分辨率处理效果。
总的来讲,我们的研究作出的贡献有以下三方面:
- 我们为图像的超分辨率处理提出了一个完整的CNN模型。这个模型直接学习低/高分辨率图像之间的端到端映射,除了优化过程几乎没有其他预处理与后加工工作。
- 我们确立了基于深度学习的图像超分辨率处理方法,与传统的基于稀疏编码的图像超分辨率处理方法之间的关系。这个关系为网络模型的设计指引了方向。
- 我们证明了深度学习在处理超分辨率重建这一计算机视觉领域的经典问题上的有效性,高效性,高速性。
相关工作的早期版本之前已有呈现。现期的研究对早期的工作作了很大的补充。首先,我们通过在非线性层引入更大的过滤器改良了SRCNN模型,又通过添加非线性映射层探索了更深的网络结构。第二,我们拓展了SRCNN使之同时可以处理三通道图像(YCbCr或者RGB空间)。通过实验,我们证实了相对于单通道网络而言,新的模型处理效果是有所提升的。第三,我们对早期的结果添加了相当多新的分析与直观的解释。我们还将旧的实验测试集从set5和set14提升到BSD200(200张测试图像)。此外,我们使用多种评估方式将我们的模型与其他大量新发布的方法相对比,证实了我们的模型表现依旧胜过它们。
2.相关工作
2.1 图像超分辨率处理
根据图像的先验知识,单张图像超分辨率算法可被分为四类:预测模型法,基于边缘检测法,图像统计学方法,以及基于像素块(基于实例)的方法。这些方法在Yang等人的研究里已被研究和评估地很彻底了。在这些方法之中,基于实例的方法处理效果最优。
基于外部实例的方法发掘自相似属性,从输入的图像中产生典型像素块。这种方法由Glasner首先提出,继而陆续出现多种加速优化过程的改良变体形式。这些基于外部实例的方法会从外部实例集中学习低/高分辨率像素块之间的映射关系。这些研究成果在如何学习到一个简洁的代码词典或多样的空间用于将低/高分辨率像素块联系到一起;以及在这样的空间实行怎样的代表机制等方面观点相左。在Freeman等人具先驱意义的研究中,代码词典被直接表示为低/高分辨率像素块对,输入像素块的最近邻存在于低分辨率空间,其对应的高分辨率像素块被用于重建过程。Chang等人的研究则提出了一种流形嵌入技巧作为最近邻策略的替代方法。在Yang等人的研究中,上述最近邻相当法进化成为一种更加复杂的稀疏编码公式。为了提高映射准确度和处理速度,研究者们提出了其他的映射函数例如核回归,简单函数,随机森林,以及锚邻里回归。基于稀疏编码的方法及其若干改良版本属于当今较为先进的超分辨率方法。在这些方法中,优化过程的关注点在像素块上,抽取与聚合像素块被认为是预处理/后加工工作,受到单独的处理。
大部分的超分辨率算法都是针对灰度图或单通道图的图像超分辨率问题的。对于彩色图像,上述方法首先将问题转化到一个不同的色彩空间(例如YCbCr或YUV),只对亮度信道进行超分辨率处理。也有一些研究工作试图同时超分辨率处理所有信道。例如Kim和Kwon以及Dai等人将他们的模型应用在每个RGB通道上,然后将处理结果组合成最终结果。然而,以上研究者们都没有研究过超分辨率方法在不同通道的处理效果,以及恢复三通道的必要性。
2.2 卷积神经网络
CNN的历史可以追溯到数十年前,深度CNN近期展现出爆发流行趋势,原因部分归结于它在图像分类方面的成功。CNN也被成功应用于其他计算机视觉领域,例如目标检测,脸部识别,以及行人检测。对实现这个进展,如下因素十分重要:(i)在当代强大的GPU上实现的高效训练优化过程,(ii)修正线性单元(ReLU)的提出,使得收敛速度在保持质量的情况下更快了,(iii)用于训练更大模型的大量数据(例如ImageNet)更易得到了。我们的方法也得益于这些进展。
2.3 基于深度学习的图像重建
现在已经有了一些利用深度学习技巧的图像重建研究。多层感知机(MLP),每层都为全连接的(而非卷积的),被应用于自然图像降噪与去模糊后降噪。与我们的研究关系更加密切的是,CNN被应用于自然语言降噪以及去噪模式(泥土/雨水)。这些重建问题或多或少受降噪目的驱使。Cui等人受到基于外部实例方法的观念影响,提出在他们的超分辨率处理流程中嵌入自编码网络。深度模型不是特别设计成端到端型的解决方法,因为每一层都需要对自相似性搜索过程和自编码模块进行独立的优化。与之相反,我们提出的SRCNN优化的是一个端到端映射。更何况SRCNN速度很快。它不仅是一个数量上优胜,在实际应用中也很有用。
** 3. 基于卷积神经网络的超分辨率重建**
3.1 构想
设想单低分辨率图像,我们首先使用双三次插值将它放大到想要的尺寸,这将是我们实施的唯一一个预处理过程。将这个插值处理过的图片表示为Y,我们的目标是从Y恢复出图片F(Y)使之尽可能与高分辨率原图X相像。为了陈述方便,我们依旧称Y为低分辨率图片,尽管它的尺寸与X相同。我们希望学习到映射F,F在概念上具有以下三个功能:
- 像素块提取与表示:这个功能从低像素图片Y中提取(部分重叠的)像素块,并将每个像素块表示为高维向量。这些向量包含一套特征映射,映射的个数等于向量的维度。
- 非线性映射:这个功能将每个高维向量非线性地映射成另外一个高维向量。每个映射后的向量从概念上来讲代表了一个高分辨率像素块。这些向量构成了另外一个特征映射集。
- 重建:这个处理聚集以上高分辨率基于像素块的替代对象,用于生成最终的高分辨率图像。并且我们希望这个图像能尽可能与高分辨率原图相近。
我们会证明以上处理环节组合成一个卷积神经网。在Figure 2 中描绘了对这个模型的概述。接下来我们会具体描述对每个处理环节的定义。
3.1.1 像素块提取与表示方法
一种常用的图像复原策略是密集地抽取像素块然后用一组预先训练过的方法处理,例如:主成分分析(PCA),Haar分析法等等。这种做法等价于用一系列过滤层对图像做卷积处理。每一个过滤层相当于一个分析方法。在我们的构想当中,我们将对这些分析过程的优化转化为对整个网络模型的优化。正式来说,模型的第一层可以表示为F1运算:
F1(Y)=max(0,W1 ∗Y+B1) (1)
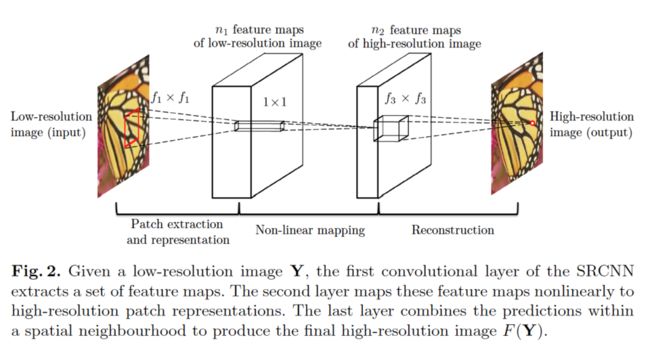
其中W1和B1分别代表过滤层与误差。这里W1的大小为:c × f1 × f1 × n1,其中c为输入图像的通道数,f1为过滤层的空间尺寸,n1 为过滤层的数量。直觉上讲,W1 对图像做n1次卷积操作,且每次卷积使用的核矩阵大小为c × f1 × f1。输出由n1个特征映射构成。B1是一个n1维向量,向量中每一维的元素对应一个过滤层。我们对每个过滤层的输出用ReLU(修正线性单元函数)作处理。
3.1.2 非线性映射
模型第一层为每个像素块提取出一个n1维向量。在第二个处理环节,我们将每个n1维向量映射成n2维向量。这等价于采用n2个过滤层,每层的空间大小为1×1。这种处理只对1×1层有用。但易于处理产生更大的层如3×3或5×5大小。在那种情况下,非线性映射不在一批输入图像上,而是在一个3×3或5×5“批”的属性映射。第二层的处理可表示为:
F2(Y)=max(0,W2*F1(Y)+B2) (2)
此处W2包含n2个大小为n1×f2×f2的层,B2为n2维的。输出的每一个n2维度的向量从概念上来说代表了一个高分辨率的应用在重建过程的像素块。
添加更多的空间大小为1×1的卷积层以提升非线性性能是有可能的。但这样做会极大地提高模型的复杂度(每层有n2f2f2*n2个参数),进而需要更多的训练数据与训练时间。我们会在4.3.3节介绍更多非线性映射层以探究更深的结构。
3.1.3 重建
在传统方法中,通常对预测出的部分重叠的高分辨率像素块求均值来产生最后的完整图像。求均值过程可被看作一个预定义的,被应用在一系列属性映射关系(在这些映射关系中,每个位置都是一个高分辨率像素块的“平整”形状)上的过滤层。由此,我们定义了用于产生最终的高分辨率图像的一个卷积层:
F(Y) = W3 *F2(Y) + B3 (3)
其中W3的大小为c个大小为n2 × f3 × f3的层,B3为一个维度为c的向量。
如果高分辨率像素块的表示是在图像定义域之中的(那么我们可以简单地修改每个表示来形成像素块),我们希望过滤层表现得像求均值过滤层一样;如果高分辨率像素块的表示在其他定义域(比如表示为其他坐标系系统中的一系列系数),我们希望W3的作用类似于:先将这些系数映射到图像域然后求均值。在这两个方法中,W3代表一系列的线性过滤层。
有趣的是,尽管以上三个处理流程是受不同的直觉驱动的,最终都导致相同的形式,也就是卷积层。我们将三个处理流程合并在一起,形成了一个卷积神经网络(Figure 2)。在这个模型中,每层的w和b都有待优化。除去整个结构的简洁性,我们的SCRNN模型是通过参考超分辨率处理方法的若干个巨大进展中的大量的经验,精心生成的。我们将在下个单元详细解释其中的关系。
3.2 与稀疏编码方法之间联系
我们发现基于稀疏编码的超分辨率处理方法可以被看作一个卷积神经网络。如Figure 3所示。

在基于稀疏编码的方法中,设从输入图像中提取一个f1×f1的低分辨率像素块。将这个像素块减去它的平均值,然后映射到一个(低分辨率的)编码词典上。如果编码词典大小为n1,这样做相当于对输入图像应用n1个(f1×f1)的过滤层(减去平均值的运算也是一个线性运算因此可以被涵盖在模型中)。如图Figure 3的左侧部分。
一个稀疏编码处理器会被应用于映射处理后的n1个系数上。处理后的输出为n2个系数,通常在稀疏编码的情况下n2=n1。这n2个系数分别代表了高分辨率像素块。从这层意义上说,稀疏编码处理器的作用体现为一个非线性的映射器,如图Figure 3的中间部分。然而稀疏编码处理器是非前馈的,也就是说它是一个迭代算法。相反地,我们的非线性处理器是全前馈的,且能够有效率地计算。我们的非线性处理器可被认为是一个智能像素点全连接层。
以上的n2个系数(通过稀疏编码以后的)接下来被映射到另外一个(高分辨率的)编码词典上,以产生一个高分辨率像素块。这些部分重叠的高分辨率像素块接下来则被求均值。像之前所说的,这个过程等价于对n2个属性映射做线性卷积处理。如果被用于重建的高分辨率像素块的大小为f3×f3,则线性过滤层的空间支持大小为f3×f3。如图Figure 3的右侧部分。
以上内容表明:基于稀疏编码的超分辨率处理方法可被看做是一种(采用不同非线性映射的)卷积神经网络。但基于稀疏编码的超分辨率处理方法并未在优化过程中考虑到所有的处理流程。相反地,在我们的卷积神经网络模型中,低分辨率编码词典,高分辨率编码词典,非线性映射,以及减去平均数和做均值计算等处理流程,全都包含在了需要优化的过滤层中。因而我们的方法中,优化的对象是一个涵盖所有运算流程的端到端映射。
以上的类比过程也可以帮助我们设计超参数。比方说,我们可以将最后一层的尺寸设定为比第一层的尺寸小,那么我们更依赖高分辨率像素块的中间部分(从极限角度来讲,若f3=1,我们可以不加求平均数处理地使用中间的像素点)。我们也可以设置n2
3.3 训练
端到端映射F的学习需要估计参数Θ={W1,W2,W3,B1,B2,B3}。这一步是通过最小化重建图像F(Y;Θ)与对应的实际高分辨率图片X之间的损失达到的。给定一个高分辨率图片集{Xi}与其对应的低分辨率图像{Yi},我们利用均方误差函数(MSE)作为损失函数:

其中n为训练样本个数。损失函数的最小化利用标准反向传播的梯度随机下降法实现。使用MSE作为损失函数倾向于高的峰值信噪比(PSNR)。PSNR是一种被广泛运用于数值化评估图像重建质量的评估标准,且至少部分地与感知质量相关。值得一提的是,卷积神经网络并不排除对其他损失函数的采用,只要这种损失函数是可推导的。如果训练中发现了一种更好的感知驱动的评估标准,网络模型也可以灵活得采用那种评估标准。未来我们会研究这个问题。相反的是,这样的灵活性对传统的“手工”方式来说是难以达到的。提出的模型是倾向于高PSNR的方向训练出来的,除此以外,我们也使用其他评估标准例如SSIM,MSSIM等评估了我们的模型的表现。
损失值利用标准反向传播随机梯度下降法缩小。特别地,权值矩阵的更新式子为:

其中l∈{1,2,3}且i为层数与循环的的指数,η为学习率,

在训练阶段,真实图片{Xi}被预处理为
sub-image为被从训练图像中随机切割出的图像。之所以称之为“sub-image”是因为我们视这些样例为亚图像,而不是图块,因为图块意味着可能存在重叠情况,且需要一些求均值之类的后处理,而亚图像不需要。为了合成低分辨率样本{Yi},我们使用高斯核模糊处理每个亚图像,使用放大因子对其进行子采样,并通过双三次插值利用相同的因子将其升级。
为了避免在训练期间的边界效应,所有的卷积层没有填充,并且网络产生较小的输出((fsub-f1-f2-f3+3)^2*c). MSE损失函数仅根据Xi的中心像素和网络输出之间的差值评估。 虽然我们在训练中使用固定的图像大小,但是卷积神经网络可以在测试期间应用于任意大小的图像。
我们使用cuda-convnet包[26]来实现我们的模型。我们还尝试了Caffe包[24],并观察到类似的性能。
4. 实验过程
我们首先研究使用不同的数据集对模型性能的影响。接下来,我们检查通过我们的方法学习的过滤层。然后我们探索网络的不同架构设计,并研究超分辨率性能与深度,过滤层的数量以及过滤层大小等因素之间的关系。随后,我们将我们的方法与目前最前沿的方法在数量与质量上作对比。在[42]之后,超分辨率仅应用于第4.1-4.4节中的亮度通道(YCbCr颜色空间中的Y通道),因此在第一/最后一层中c=1,并且性能(例如PSNR和SSIM)在Y通道上评估。最后,我们扩展网络以处理彩色图像并评估不同通道的性能。
4.1 训练集数据
如文献所示,深度学习通常受益于大数据训练。为了比较,我们使用了一个相对较小的训练集[41],[50],它包括91个图像和一个大的训练集,包括来自ILSVRC 2013 ImageNet检测训练分区的395,909幅图像。训练子图像的大小为fsub=33。因此,91图像数据集可以被分解成24,800个子图像,其从具有14的步幅的原始图像提取。而ImageNet可提供超过500万个子图像,即使使用的步幅仅为33.我们使用基本网络设置,例如f1=9,f2=1,f3=5,n1=64和n2=32.我们使用Set5[2]作为验证集。即使使用更大的Set14集[51],我们也有观察到类似的趋势。放大因子是3。我们使用基于稀疏编码的方法[50]作为我们的基准,并实现了31.42dB的PSNR值。
使用不同训练集的测试收敛曲线如图4所示。由于反向传播的数量是相同的,ImageNet上的训练时间与91图像数据集大致相同。可以观察到,利用相同数量的反向传播(例如8*10^8),SRCNN+ImageNet实现了32.52dB,高于在91图像数据集上训练的32.39dB。结果肯定地表明,SRCNN的性能可以通过使用更大的训练集进一步提高,但大数据的影响不如高水平视觉问题[26]所示。这主要是因为91个图像已经捕获到自然图像的足够的变化性。另一方面,我们的SRCNN是相对较小的网络(8032个参数),其不能过度拟合91个图像(24800个样本)。然而,我们采用ImageNet,其包含更多样的数据,作为接下来实验中的默认训练集。
4.2 超分辨率的学习
4.2超分辨率的学习过滤器图5显示了通过放大因子3在ImageNet上训练的学习的第一层过滤器的示例。请参考我们发布的用于放大因子2和4的实现。有趣的是,每个学习的过滤器都有其特定的功能。 例如,滤波器g和h类似于拉普拉斯/高斯滤波器,滤波器a-e类似于在不同方向上的边缘检测器,并且滤波器f像纹理提取器。 不同层的示例特征图示于图6中。显然,第一层的特征图包含不同的结构(例如,不同方向的边缘),而第二层的特征图主要在强度上不同。
4.2 Learned Filters for Super-Resolution Figure 5 shows examples of learned first-layer filters trained on the ImageNet by an upscaling factor 3. Please refer to our published implementation for upscaling
factors 2 and 4. Interestingly, each learned filter has its specific functionality. For instance, the filters g and h are like Laplacian/Gaussian filters, the filters a - e are like edge detectors at different directions, and the filter f is like a texture extractor. Example feature maps of different layers are shown in figure 6. Obviously, feature maps of the first layer contain different structures (e.g., edges at different directions), while that of the second layer are mainly different on intensities.
数据集。 为了公平地与传统的基于样例的方法作对比,我们使用与【20】中相同的训练集,测试集以及协议。具体来说,训练集中一共有91张图片。【2】中的set5(5张图片)被用来评估在放大因子2,3,4下的表现,【28】中的set14(14张图片)被用来评估在放大因子3下的表现。除了这个91张图像的训练集,我们在5.2节中研究了一个更大的训练集的效果。
比较。我们将我们的SRCNN模型与当前领先的超分辨率处理方法对比:Yang等人的基于稀疏编码的方法(SC),基于K-SVD算法的方法,NE+LLE(邻嵌入+本地线性嵌入)方法,NE+NNLS(邻嵌入+非负最小平方)方法,以及ANR(锚邻里回归)方法。