最近看了Ongaro在2014年的博士论文《CONSENSUS: BRIDGING THEORY AND PRACTICE》的部分章节,对raft有了初步的理解。其中论文中提到用于教学的user study,个人感觉非常不错,言简意赅,特此分享出来。本文基本与原讲解一致,又加上了笔者的一点理解。
资源来源于Ongaro和Ousterhout在youtube上的分享(http://youtu.be/YbZ3zDzDnrw),共有31个slide,因篇幅字数限制分为上下:
上:分布式一致性算法Raft简介(上)
下:分布式一致性算法Raft简介(下)
slide 15:

这一节开始讲leader changes,即leader的变更过程中如何保证log的一致性:
1)需要明白的是,新leader上任后,各个server的log状态很可能是不一致的;因为旧leader可能只完成了部分server的log复制就挂掉了;(新君即位,一片狼藉)
2)需要特别注意的是,raft中新leader上任后,并不会立即对不一致的旧log进行clean up,而仍然是正常开始normal operation;clean up是在normal operation的过程中进行的;原因在于:新leader上任后,可能有些server仍然是宕机状态,新leader没有办法立即对其进行clean up(因为那些server宕机或网络不通,无法进行通讯),只能等到这些server恢复正常后再进行clean up;而新leader不知道这些server什么时候能恢复正常,如果傻傻地苦苦等待,很可能会导致整个系统无法运行;所以,我们设计的系统,必须要确保新leader上任后要立即开始normal operation,而在normal operation的过程中要确保最终所有log一致;
3)raft的做法是:总是认为leader的log是对的!(皇帝总是对的)
4)raft认为leader的log总是对的,总是包含所有重要的信息,因此leader的重任就是最终使得所有follower的日志与之完全相同。(皇帝总是对的,皇帝总是试图广播自己的想法,让其他所有人的想法与之最终一致)
5)但是新leader在clean up的过程中也有可能宕机,再有新的leader上任,它也可能还没完成重任就又宕机了;如此循环;长时间如此,最终会导致各个server的log混乱不堪,如图实例。
(备注:注意图中示例,只标注了某个entry的index和term,为什么不标注command了?因为前面已经说了,只要entry的index和term相同,则其command一定相同,所以没必要标注;图中展示的log混乱不堪,点评分析如下:term1时期的log都是一致的,谁是leader无从知晓;term2时期只有S4和S5两个server,但S5的entry更多,记住信息总是从leader流向follower,所以leader必定是S5;term3只有S5,无疑它就是leader,这种情况很可能是当选leader后与其他server网络隔离了;同理term4时期S4是leader,term5时期S3是leader,term6时期S1是leader,term7时期S2是leader;另外从图中场景来看,很可能在中间某段时间,S4、S5的网络,与S1、S2、S3的网络不通,即产生了网络隔离;)
需要特别注意的是,图中entry(1,1)、entry(2,1)、entry(3,5)都是已提交的(标记方法是entry(index,term),这些entry所在server数都已过半),而其余所有的entry都是未提交的;我们一定要确保的是那些已提交的entry必须保存下来且不可再变更;而那些未提交的entry,因为还未传给任何state machine执行过,client更没有收到执行结果,所以是保存还是丢弃都无关紧要;
例如图中S2成为term7时期的leader后,如果能够与其他所有server通信,那它最终要保证其他所有server的log与它的log相同,这就意味着与之有冲突的log entry必须被清除;后续会详细讲解leader如何进行clean up使得followers的log与之相同;特别强调一下correctness和safety,我们怎样才能确保系统正常运行,确保不丢失重要信息呢?如我们刚才为了保证一致性,丢弃了一些log,我们怎样做才是安全的呢?下节讲。
slide 16:

任何实现了replicated logs的系统都必须遵守的最基本的safety requirement原则是:
Once a log entry has been applied to a state machine, no other state machine must apply a different value for that log entry;即一旦某条log entry已经被某一个state machine执行,则其他任何state machine也必须执行这同一条log entry;即所有state machine都必须按照相同的顺序,执行完全相同的entry;(执行entry指的就是执行entry中的command)
为了实现这个整体的safety要求,raft采取了更严苛的准则,即如下的safety property:
如果某个leader发现某条log entry已经被提交,则这条entry必须存在于所有后续的leader中。这意味着,一旦某个leader即位,则在它的整个term时期内,它一定含有所有的已提交的log entries;
显而易见,只要leader满足了这条safety property,则一定能满足上面的safety requirement。(因为这是一个更窄的要求,简单推理:一个leader发现某条entry已被提交,则后续所有leader中都一定要有这条entry;这意味着leader中总是有所有的已提交entry;而raft能保证follower中的log最终一定与leader中的一致;所以所有server最终都会有这些已提交entry;而entry只有被提交后才能被state machine执行;所以最终所有的state machine必将按照相同的顺序执行相同的命令)
为了实现这一点,raft能够保证的safety requirement有:
1)leaders永远不会修改自己log中的entries,只能添加;(备注:这意思就是leader中的entry是不可变的;但注意,leader只是一种角色,是动态的不是永久的;只是说某个server当leader期间,它的entry是不可变的;而一旦下台,其entry是有可能被修改的;这类似于绕口令啊;)这条性质叫AppendOnlyProperty,即leader只能添加entry,但不能修改entry;这意味着leaders中log entries永远不会被修改;
2)只有leaders中的log才能被提交;言外之意是,某条entry即使过半server都存在了,但在leader中不存在,也是不能被提交的;(有人会想,会有这种情况吗?entry不都是从leader发给follower的吗,怎么会过半followers中有而leader中没有呢?再次强调,leader和follower只是角色,是动态的;正常情况下当然不会有这种情况,但是leader变更的时候就可能会出现,后续会有这种case)
3)entries在被提交给state machine执行之前,必须已被提交;即只有已被提交的entry才能被执行;
汇总1)、2)、3),我们可以保证上面的安全性。真的如此吗?有这三个条件就够了吗?
事实上,到现在的讲述为止,raft有这三个约束,并不能保证上面的安全性;我们必须增加额外的约束条件才能保证上面所述的安全性,后面会详细讲述我们是怎么解决的。先再回头想想我们需要达到的目标:
某个entry已被提交 -> 这条entry必定在后续leader中存在
为了实现这个安全性目标,我们必须从两方面修正raft算法:
a. 对leader election增加约束条件:如果某个server的log中缺少某个已提交entry,则不允许这个server当leader;
b. 必须改变对committed的定义:前面说的已过半即是committed,这是不够的;有时候我们必须延迟committed,直到我们认为安全了才能committed;所谓的安全,就是说我们认为能够保证后续leader有这条entry;
(点评:这两个约束条件非常绕口,大家认真领悟下:约束a是排除了某些server当leader,即不含有已提交entry的server不允许当leader;显而易见,只有约束a是不够的,因为a说的只是最低安全性条件,照此条件,有可能一个leader都选不出来;而b是对committed条件的加强,意味着对committed施加更严苛的条件,也意味着给更多server成为leader的机会,即能够保证最终能选出leader;后续会有相应case)
slide 17:

接着上个slide,先讲leader election过程的修正:
我们怎样挑选leader,才能保证这个leader有所有的已提交entries呢?
这个问题非常难,因为我们有时候根本无法判断某条entry是否已提交了!
看上图:图中有3个server,但是突然server3挂掉了,必须从server1和server2中挑选一个leader;而对于entry5而言,根本无法判断entry5是否是已提交的!因为这取决于server3,如果server3中有entry5,则是已提交的,如果server3中无entry5,则不是已提交的;而server3已宕机或网络不通,根本无法与server3通讯,所以根本不可能知道server3上到底有没有entry5,所以根本无法判断entry5是否是已提交!
既然我们根本无法判断某条entry是否是已提交,我们怎么挑选leader来确保leader中一定有所有已提交entry呢?我们只能尽我们所能,挑选最有可能含有所有已提交entry的server做leader,即挑选the best leader! 我们此处先从直觉上这样理解,下面会更精确详细地证明。
我们挑选best leader的方式就是通过对log进行比较,即comparing logs:
1)candidate发起的RequestVote RPC投票请求包含其log中最后一条entry的index和term:回忆我们前面所说,最后一条entry的index和term能唯一标记整条log,即如果last entry的index和term相同,则这两条log必定相同;(需从前面两个结论推知: a. index和term唯一标记一条entry; b. 某个entry相同,则其之前的entries也必定相同)
2)当其他server收到投票请求时,需要将收到的(index,term)与自己的相比较,如果认为自己的log更完整,则拒绝投票;更准确的定义如下:voting server V 收到candidate C的RequestVote请求,如果出现下面两种情况之一:
a. lastTerm_v > lastTerm_c 即server v的last entry所在term,即lastTerm比candidate的大;
b. (lastTerm_v == lastTerm_c) && (lastIndex_v > lastIndex_c) 即server v的lastTerm与candidate相同,但是lastIndex值比candidate大;
一旦出现a或b,则server V认为自己的log更complete,直接否决candidate的投票请求;
(点评:此处非常关键,务必理解;回想我们的目的是pick the best leader,即要求candidate的日志尽可能最complete!最显然直观的理解当然就是谁的log最长谁的最完整了;然而,不尽如此;还有一个更重要的要求是more informative!只最多是没用的,首先要确保的是你的信息是最权威的、最informative的;在raft中我们引入了term的概念,且总是认为更晚term的信息比更早term的信息权威,所以挑选leader的首要条件就是看,谁的term更晚更大,即a;第二才是比较谁的log更长,即b)
3)结合1)、2)最终确保选举出来的leader将会是大多数server中log“最完整”的(most complete);
听懂没?不要担心,下面上实例。
slide 18:
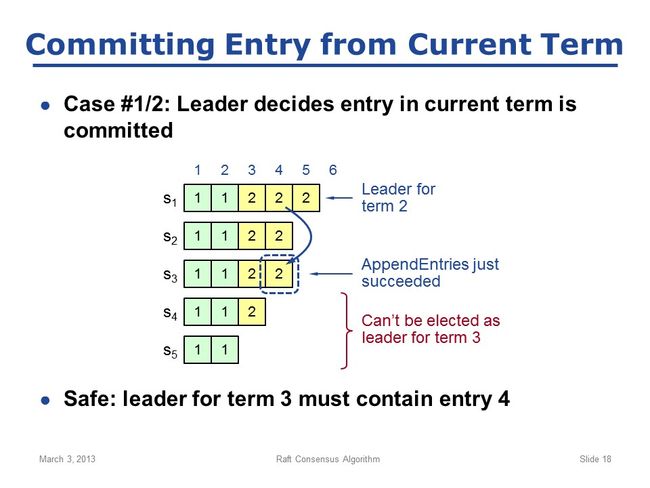
考虑最有趣的一种场景:leader刚刚确定某条entry被committed了(即刚收到来自大多数server的AppendEntries响应),就挂了。这种场景可以再分成两种独立case:1)这条entry属于current term;2)这条entry属于prior term;
先说case1,如图:
S1是term2时期的leader,刚把entry4复制到S2、S3成功,立马宣布entry4已安全(即在大多数server中都有,已被committed),立即在state machine上执行entry4;这意味着entry4是已提交的,后续的leader中必须包含这条entry,我们怎么确保呢?就是通过上一个slide中的leader election中的pick the best leader;设想,此时S1突然网络不通,需要重新选举leader,我们逐个分析:
a. S5绝不可能成为leader,因为其他server都处于term2,它还在term1,即其他server的lastTerm更大,会直接拒绝给它投票;
b. S4处于term2,但它若想成为leader,还需要至少2台server给它投票,而它最多只能得到S5的投票;因为其他server也都处于term2,但是log更长,即lastIndex更大,所以都会拒绝投票;因此S4加上自身最多得2票,也不可能成为leader;
c. S2和S3都可能成为leader,例如收到来自S4、S5的投票;显然,S1也可能成为leader;
综合abc发现,可能成为leader的server都含有entry4,即新的term3时期的leader必定含有entry4;换言之,最终新leader必定含有已committed的entry;
slide 19:

现在考虑case 2:leader尽力使得一条entry被提交,而这条entry来自上一个term时期。
如图:
1)S1是term2时期的leader,S1刚将entry3复制到S2,就挂掉了,即此时entry3只在S1、S2两个server上有;
2)接着S5发起leader竞选,收到来自S3、S4的投票(此时S3、S4、S5都只有term1时期的entry1、entry2,所以不会拒绝投票),成功当选成为term3时期的leader;接着S5收到client请求,在本地log中产生了3条entry,但由于种种原因(如与其他server网络忽然不通),并未复制到其他server上就挂掉了;
3)接着S1再次竞选,成功当选为term4时期的leader;S1成为leader后,会尽力使得其他server的log与之相同,所以会将entry3、entry4复制到其他server上;一旦将entry3复制到server3上,则此时entry3已经形成大多数,即是已被committed了;entry3上的command就会被state machines执行,client就会收到entry3的执行结果。
最危险的情况出现了!注意,这种场景下entry3并不能认为是safely committed!因为它仍可能被覆盖,仍可能丢失!
考虑接下来可能发生的情况,就会明白为什么了:
4)S1成为term4时期的leader后,刚在本地产生entry4就挂掉了;而此时,S5可以再次当选,成为term5时期的leader(考虑下可能性,是完全有可能的,虽然entry3是committed了,但是S5很可能并不知道;因为可能网络分割,S1无法与其他server通信,只有S2、S3、S4、S5可以互相通信,此时S5不可能知道entry3是否已committed,S5完全可以当选leader)
5)S5当选leader之后,就会尽力使得其他server的log与之相同,就会term3时期的entry3、entry4、entry5复制到其他server;
很显然,之前的term2时期的entry3虽然已被认为是committed了,但仍会被覆盖导致丢失!显然,这与我们要求的safety原则相悖,无法容忍!必须加上新的限制条件,避免这种情况发生。
slide 20:

接前文;目前为止,new leader election rules并不足以保证安全性,我们必须还要修改已有的commitment rules!
回想一下,到目前为止,我们的commitment rules是:
1)只要leader看到某条entry存在majority of servers上(过半即可),则认为这条entry是committed;
为了保证安全性,我们必须添加一个额外的rule:
2)leader必须看到至少一条来自leader term(即leader的current term)的entry也存在于大多数的server上;
同时,rule 1)之前是充要条件,现在变成了必要非充分条件,新的commitment ruels是:
1)leader必须看到某条entry存在于大多数server上;
2)另外,leader必须看到至少一条来自其current term的entry也存在于大多数server上;
只有同时满足1)2)才能认为某条entry是committed的。
很明显,新加的rule 2)主要是针对上面说的case2场景的,即当新leader看到某条来自之前term的entry已经存在于大多数server上时,它不能再认为这条entry是committed了,必须等到来自其自身term的第一条entry也存在于大多数server上,才能认为之前term的那条entry是committed的;这其实相当于一种leader change场景下的延迟commitment吧,或者换种思路,相当于将上一个term时期的entry的commitment与当前term时期的commitment绑定在了一起。
回到前面的case2,接着看新commitment rules是如何保证安全性的:
1)当S5成为term4时期的leader后,它将entry3复制到S3,此时entry3已经存在于过半server上,但是并不能认为entry3是committed的,即并不会将entry3传给state machines执行;
2)必须等到entry4也复制到过半机器上,此时才能认为entry3、entry4是committed了(相当于延迟与绑定)。
那这样就是安全的了吗?是的。设想一下:
1)如果S1复制完成entry3、entry4到大多数server上,即entry3、entry4都已被committed了,此时S1挂掉了;那么显然,S4、S5不可能成为新的leader(因为term太低会被拒绝投票),只有S1、S2、S3有可能成为新leader,而这些server上都有entry3、entry4,所以entry3、entry4是安全的;
2)那么如果S1还没将entry3、entry4复制到大多数server上就挂了呢?那S5有可能成为新leader,即意味着entry3、entry4可能会被覆盖。这有什么关系呢?这种情况下entry3、entry4并没被认为是committed的,其命令被没有被state machine执行,client更没有收到其执行结果;这种情况下,entry3、entry4被覆盖而丢失是无关紧要的;
我们只保证已committed的entries的safety,并不对未committed的entries的安全性做任何保证。
因此,据上分析可知,new commitment rules是能够保证committed entries的safety的。
综上可知,new election rules和new commitment rules结合起来,能够保证raft的safety特性总是成立;即,一旦leader认为某条entry已被committed,则这条entry必然存在于后续所有leader的log中(就是说已committe的entries永不丢失);虽然我们这里只证明了已committed的entry必然存在于紧接着它的后续一个leader中,但很显然容易证明,这条entry在后续所有leader中都会有;
而一旦raft的safety特性成立,根据我们之前所说,所有的replicated logs都是安全的。
(点评:raft的safety property是整个raft系统的基石,是整个系统运行可靠性的最基本要求;需要认真理解领悟,结合实例认真体会raft是如何面对这些问题的,如何一步步修正完善rules来保证安全性的)
slide 21:

现在,我们保证了raft的safety,并且知道leader的log永远是对的,那么我们怎么使得followers的log与leader的log相同呢?
首先让我们看下,followers的log有哪些与leader可能不同的情况呢:
1)missing entries:即follower的log与leader相比缺少某些entries,如图中的a/b/e follower;
2)extraneous entries:即follower的log与leader相比多出某些entries,如图中的c/d/f follower;
我们需要做的是:删除所有follower log中的多余entries,并用leader log中的entries填充follower中缺失的entries。
slide 22:
接上文继续讲述,leader到底如何修复follower的logs使其与之相同呢?
上个slide已说了,leader为了保证follower的log与之相同,必须:
1)删除follower中的多余entries;
2)用自己的entries填充follower中的缺失entries;
那leader具体是如何做的呢?
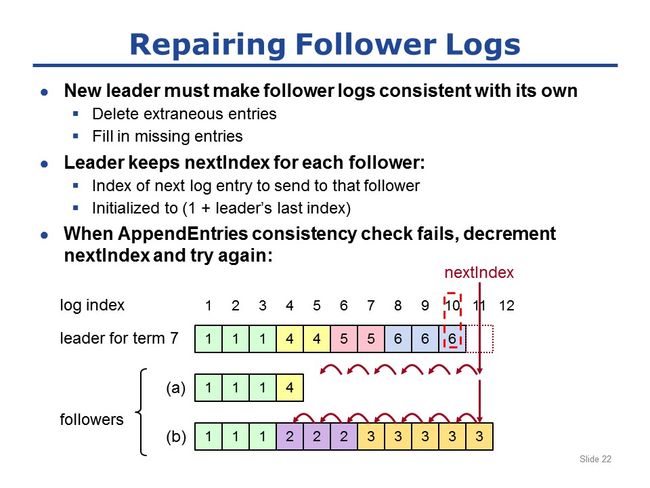
为了恢复log一致性,leader为集群中所有follower都保存一个状态变量,即nextIndex:
1)nextIndex是leader准备向某个follower发送的下一个log entry的index;
2)当leader刚刚即位后,nextIndex的初始值是(1+leader's last index);
如图举例:
某个server成为term7时期的新leader,其log中的最后一条是entry10,所以这个leader会将所有follower的nextIndex都设为11;
leader可以通过AppendEntries RPC请求发现log之间的一致性问题;回想前面说过的,follower收到AppendEntries RPC请求的时候,会进行log一致性检查,所以一旦有不一致情况就会被检查出来;
因此,当leader试图与集群中的follower通讯时候,会带上nextIndex前面的一个entry的index和term(回想下,这是之前说过的,AppendEntries RPC请求会带上前一个entry的index和term用于进行一致性检查,这里的前一个entry就是entry10,对应的index和term分别是10和6);
顺便说下,新leader即位后,立即发出的请求很可能是heartbeat(心跳请求)!回忆之前说的,心跳请求跟普通的AppendEntries RPC是一样的,只是不带新values而已,但心跳请求仍然可以进行一致性检查;
因此,当这个请求(可能是心跳也可能是普通的AppendEntries )到达follower a时,follower会拿这个index和term(这里就是(10,6))与自己的log相比较;很显然,follower a中没有与之相匹配的;所以follower a会直接拒绝这个请求!
当leader看到请求被拒绝时,其动作非常简单:只需将nextIndex-1,再次尝试。
如此往复,再失败,nextIndex再减1,再重试;直到nextIndex=5,此时leader会带上(4,4)这个entry,follower a发现能与之匹配,所以接收;一旦follower a接受,则最终后续所有的missing entry都会被添加上;
follower b的情况也类似,当nextIndex=11时,一致性检查会失败;每次失败leader都会将nextIndex-1,然后重试;直到nextIndex=4,才会成功;最终follower b中的log也会被重新填充上;
slide 23:

接上文,修复log的过程中,需要注意的一点是:
一旦follower收到某个log entry,且这条entry会覆盖掉follower 自身的与之不一致的entry,则follower会删掉自己所有后续的entries;
如图举例:当leader将entry4发送给follower,则follower的对应位置的entry与之冲突(仍处于term2而不是term4),因此entry4会覆盖follower的entry,且会将follower中entry4后面的所有entries都删除掉(即图中的before变成after);因为我们知道,某条多余的entry后面的所有entry也都是多余的。
这里简要总结下leader change这部分的关键点:
有两个overall problems我们需要处理:一是确保系统的safety,即怎么挑选leader、何时认为某条entry是committed的;二是当新leader上任后,会尽力使所有followers的log与之相匹配,而AppendEntries一致性检查提供了所有我们需要的信息。
slide 24:

raft协议的第4部分也是关于leader change的,即old leader可能并没有真的死掉。如:
1)可能存在网络隔离或不稳定,导致leader暂时性地断网,即无法与其他servers通信;
2)其余servers等待到election timeout,然后选举出新的leader;
3)这时,如果旧leader的网络恢复了,它并不知道已经进行了选举,并不知道已有新的leader了;所以它仍认为自己是leader,并像leader一样行动,如尝试复制log entries;
事实上,确实还可能有client请求旧leader:旧leader接收到请求,记录到自己的log里,并尝试复制到集群中的其他servers中;我们必须阻止这种情况发生,方法就是使用term。
terms被用来识别过期的leader和candidate:
1)所有RPC请求都会带上sender(发送者)的term信息;当receiver收到RPC请求时,会将sender的term与其自身的term相比较,一旦不匹配,过期的一方必须更新term;
2)如果sender的term更低(更老),意味着sender是过期的;此时receiver会立即拒绝该请求,即不会执行该请求;并再给sender的response中带上receiver的term信息;当sender收到response之后,会意识到它的term已经过时,因此会主动下台,再次回到follower状态,同时更新自己的term;此时其term状态与其他servers是一致的;
3)相反,如果receiver的term更旧,则:如果此时receiver不是follower的状态,它也会主动下台,再次回到follower状态,同时更新自己的term(如果本来就是follower只需更新term即可);接着正常处理该RPC请求;这种情况下receiver不会拒绝RPC请求,因为它没有必要这样做;它只需主动下台且更新term即可;
有趣的是,leader election过程会使得集群中大多数server都更新term,因为当candidate请求投票时,它必须与集群中大多数server通信;而RequestVote RPC会带上candidate的term信息;而所有的接收者都会更新自身的term信息使之与candidate的相同;因此,当新leader上任后,集群中的大多数server都会反映出新的term信息;这意味着,一旦新的leader election完成,旧leader就不可能再接受请求并复制log entries到其他server了。因为为了复制log entries,旧leader必须与具有新term的server中的至少一台通讯,而一旦这样做,就会被发现term不匹配,而导致旧leader下台。(此处较为拗口,道理很显然,新的leader当选必然意味着过半server的term都是最新的;而旧leader复制log也必须与过半server通讯;而过半与过半之间,必然有至少一个公共server;而这个server的term检查就会使得旧leader暴露,从而下台)
因此,综上所述,可以用term检查识别过期信息。
(点评:分布式系统中的时期、任期的概念非常关键,如raft中的term、zab中的epoch等,道理都是类似的;其核心用意只有一个,即识别过期信息)
slide 25:

现在讲raft的第5部分,即client如何与raft系统交互。
大部分情况下,这都很简单,即:client将command请求发送给leader,然后接收leader的response。
但是,如果client不知道谁是leader呢?没关系,client可以请求集群中的任意server;如果那个server不是leader,它会告诉client谁是leader;然后client可以重新请求leader。
之前说过,leader并不会立即响应client,直到:command被记录到log中,并复制到大多数server上,即被committed,接着leader的state machine执行该command。此时,leader才会向client返回请求结果。
唯一需要注意的地方是,如果此时请求超时了(如leader突然挂掉导致),会怎么样?答案是:
1)client会请求集群中任意一个server,不断重试;
2)最终,client会发现集群中的新leader;
3)client会向新leader重试请求;
新leader会执行client的command,并发送请求结果。因此这能保证,command总是能够被执行。
slide 26:

然而,上一个slide中说的,总能保证command最终被执行,会带来command被重复执行的风险。
问题的关键是:leader可能在执行完某个command,但是还未向client发送结果时挂掉。而一旦出现这种情况,client不可能知道这个command到底是否被执行了,所以它会不断重试,并最终请求到新leader上,而这会导致该command被执行两次。
显然,这是无法接受的!我们要求command必须最终被执行,且只能执行一次(once and exactly once)。
raft的解决思路是:client为每个command生成一个唯一id,并在发送command时候带上该id。
1)当leader记录command时,会将command的id也记录到log entry中;
2)在leader接受command之前,会先检查log中是否有带该id的entry;
3)leader一旦发现log中已有该id的entry,则会忽略这个new command,并将old command的结果返回给client(如果此时old command还没执行完,会等待其完成再返回);
因此,只要client不crash,我们就能实现exactly-once语义,即每个command只会被执行一次。这也是我们希望系统具有的,被叫做linearize ability。
(点评:类似于幂等性,即client重试不会导致重复执行。系统本身要支持这种重入、重试,保证有且仅有一次执行。)
slide 27:

这是raft协议的第6部分:系统配置的变更机制。
系统配置指的是组成集群的各个server的信息。如每个server的id、用于通讯的网络地址等。这些信息非常重要,因为这些决定了集群中“大多数”(majority)的组成,而选举leader、commit log entry等都取决于majority vote。
我们必须要支持系统配置变更,因为机器可能宕机,我们需要用新机器替代老机器;或集群管理员想更改集群的degree of replication(复制因子、副本系数)。我们想让系统自动而安全(automatic and safe)地完成这些,而不至于变更配置导致系统崩溃。
slide 28:

重要的是,我们必须意识到:我们不能直接地将旧配置切换成新配置。为什么呢?看图中例子:
设想系统正在运行,系统配置中有3台机器,即server1/server2/server3;而我们现在想添加2台机器,即添加后应该有5台机器组成新的集群。
如果我们要求每个server直接更改配置,从旧配置改为新配置,就会产生问题。问题就是我们没办法做到所有server同时更改配置,变更过程总要花点时间,而这会导致conflicting majoritys(大多数冲突)。
例如图中某个时刻,server1、server2仍是旧配置;而server3、server4、server5已经是新配置。这样server1、server2能够形成旧集群中的大多数,它们可以基于此进行leader election、commit log entry等;而与此同时,另外3台机器,即server3、server4、server5已经是新配置了,它们也可以形成新配置集群中的大多数,也可能commit与前2台server相同位置的log entry,而这很可能会产生冲突。
这意味着,我们必须用two-phase protocol(两阶段协议),我们没办法在one-phase中完成。当然,所有的分布式系统中的decision-making都会采取这种典型办法;如果有人告诉你,他能在one-phase中完成分布式系统的decision-making,你需要提出严重质疑!要么是他错了,要么是他发现了这个世界上从来没人知道的新东西!
(点评:two-phase protocol即两阶段协议,是所有分布式系统中做decision-making的套路。问题的核心与关键就在于“分布式”,意味着系统中不是一个单一的个体,而是众多个体组成的整体;而遗憾的是这个整体不可能像单一个体那样行为,例如众多个体不可能同时完成某项动作,也即不可能完全地把一个整体等价于一个个体;而client又需要整体像一个体一样地运行。)
slide 29:
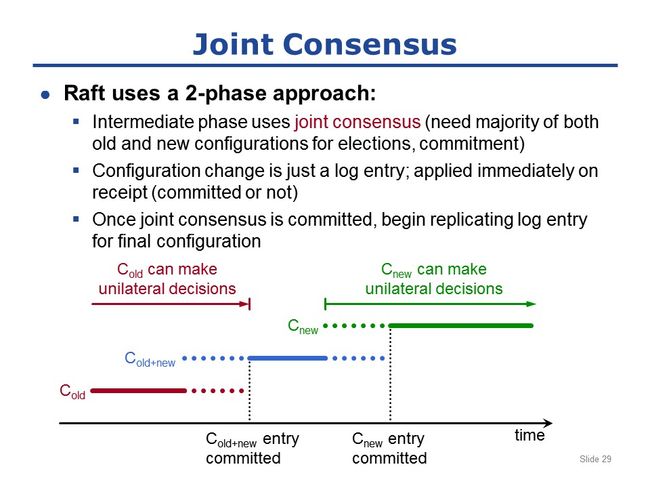
raft采用2-phase的方式进行配置变更:
raft先立即进入一个中间状态,叫joint-consensus;这个状态包含旧配置和新配置的所有机器;但是decision-making,如leader election和log commitment,需要同时满足旧配置的大多数和新配置的大多数(need majority of both old and new configurations for election and commitment);
如图中举例说明:
集群最初的已有配置是Cold,而在某个时刻,由client发起集群配置变更,即client向leader发送配置变更请求(类似普通的operation请求);当leader接收到配置变更请求时,就向自己的log中插入一条entry(跟普通的log entry是一样的),用于描述配置变更,如Cold+new;然后leader通过AppendEntries RPC请求将该配置变更log entry复制到其他server上(跟普通的AppendEntries RPC复制log entry一样);需要特别注意的是,配置变更立即生效!即一旦server将新配置的log entry写入自己的log,它就立即生存在新的配置之下;它不需要等待大多数server都有这条entry,即不需要等待这条entry提交,一旦写入自己的log中就立即生效(这点与普通entry不同,普通的entry必须等到已提交才能被执行而生效);
回到图中的时间线,leader将新配置的log entry写入自己的log,并立即生效;之后leader所做的所有decisions,都必须基于old+new的配置,如后续某条普通的entry要想被提交,必须同时存在于大多数的旧配置的server上,和大多数的新配置的server上;
过一小段时间,Cold+new这条log entry总会复制到大多数的server上而变成被提交状态;而在此之前,decision-making有可能是基于Cold,也有可能是基于Cold+new;如leader刚收到Cold+new的配置变更,还没来得及复制到更多server上就宕机了,此时处于Cold配置的server有可能当选并掌控集群;
但是,总有一个时间点,最终Cold+new这条entry能够复制到大多数server上而成为committed状态;一旦Cold+new被提交,则意味着任何server都不能再仅仅基于Cold来make decision了。简单解释:如果一个server想成为leader,它必须具有所有的已committed的log entries,而Cold+new一旦被committed,就保证了后续任何leader都一定有Cold+new这条entry,这意味着那个leader必定在Cold+new的配置下生存(living by it),即leader选举过程必须获得old配置中的大多数和new配置中的大多数同时投票,某条entry提交也必须要求这条entry存在于old配置中的大多数servers和new配置中的大多数servers上;因此,集群中不可能再有任何server仅仅基于old配置中的大多数来做决定。
所以在Cold+new已被committed的之后,集群就会在joint-consensus(联合一致性)下运行;而一旦joint-consensus被committed,leader就会传播Cnew这条log entry,即将配置变更为Cnew这条entry写入自己的log,并复制到其他servers上;
同样,在其后一段时间内,集群有可能在joint-consensus下运行(即Cold+new下),有可能在Cnew下运行;但最终,Cnew这条entry总能被committed;而一旦Cnew被committed,后续的所有decision-making都必须基于Cnew了;
因此,这里的关键点在于:决不允许Cold和Cnew都能make decision,而不互相consult(参考、询问)!最初的一段时间,仅仅依靠Cold就可以make decison;最终的一段时间,仅仅依靠Cnew就可以make decison;但是我们能确保这两个时间段没有重叠。而在这两段时间之间,两个配置必须互相consult,这就确保了集群在任何时候都不可能同时形成两个独立的consensus。
另外说明下,这种2-phase特性是非常基本的,任何一致性算法都会采用某种形式的2-phase来变更配置。事实上,任何形式的distributed agreement都要求two phases;如果有人发明了新的distributed agreement algorithm,并声称可以在single phase内完成,你需要严重质疑他:要么他们错了,要么他们发现了我们都不知道的新东西。
(点评:joint-consensus的核心关键点在于:如何避免新旧配置同时存在而产生majority conflict,进而导致decision conflict,从而产生不一致。这里采用了过渡方法,认真思考,其实单独地只有2种形式的decison-making依据:a.获取Cold中的majority的支持 b.获得Cnew中的majority的支持;但是如果简单粗暴地从a切换到b,其实是做不到的,因为不可能是一个原子操作,中间必然有一段时间,会存在a和b都生效,那么就可能会产生冲突。这里采用了一种渐进的思路:
a -> a || (a&b) -> a&b -> (a&b) || b -> b
实质上,将整个集群可能的decison-making依赖的majority状态空间分成了5个阶段,分别是:
old中大多数做决定 -> (old中的大多数做决定) 或者 (old和new中的大多数同时做决定) ->
(old和new中的大多数同时做决定)-> (old和new中的大多数同时做决定) 或者 (new中的大多数做决定) -> new中的大多数做决定
这种状态变迁的核心与关键在于:这种变迁是渐进的,每一个阶段都不会产生decison-conflict,从而保证变更过程的平稳。如果不这样做,直接变更 a ->b,显然这种粗暴的做法会导致decison-conflict。)
slide 30:
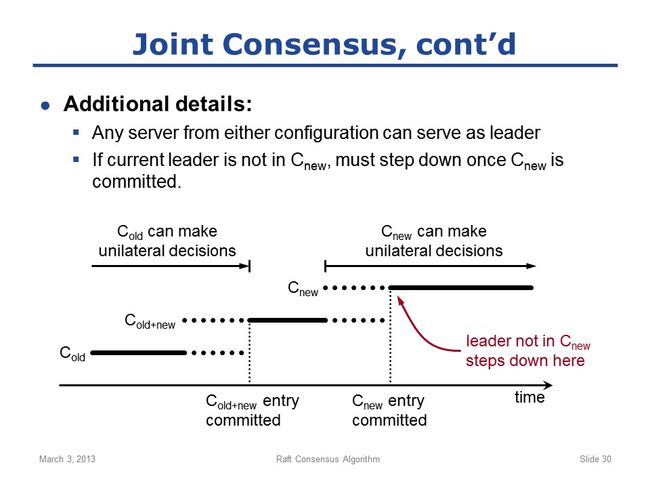
Joint-consensus这部分还有一些细节:
1)在变更的过程中,来自新旧配置的server都有可能成为leader;
2)如果当前leader不在Cnew配置里面,则一旦Cnew提交,它必须step down(下台);
这意味着,旧leader不再是新配置的成员之后,还有可能继续服务一小段时间;即旧leader可能在Cnew配置下继续当leader(虽然实质上并不是leader,但仍发挥leader的作用),直到Cnew的entry能够复制到足够多的server上而被committed;
slide 31:

Congratulations!终于介绍完了raft。这里简要回顾下raft的6个部分:
1)leader election:我们确保任何时间,一个term内至多只有一个leader;
2)normal operation:leader接收client的请求,写log并复制到集群中其他机器;注意AppendEntries时非常重要的consistency check,用于确保log的一致性,并在log不一致时用来恢复一致性;
3)safety and consistency:主要讲leader changeovers,涉及两个重大问题。一是保证系统safety,我们展示了如何保证某条entry一旦被committed就永久存在;二是确保一致性,即leader如何确保最终所有followers的log都与其完全相同;
4)neutralize old leaders:一旦有新leader,旧leader就不能再发号施令。
5)client protocol:简要介绍了client与raft的交互,特别是raft中server crash之后,client需要怎么做;
6)configuration changes:讲了raft如何自动并安全地进行配置变更。
最后,对整个raft算法进行整体评论:这个算法的核心是系统必须完美运行,即使只有majority的servers在线。这意味着,永远不能依赖全部server的信息,因为总可能会有server宕机,这完全是未知的,算法必须考虑到这点并完美处理。
(点评:raft的核心思想跟其他一致性算法是相同的,即你不能要求系统中所有个体都运行良好,你必须要做出让步,即不要求系统中所有个体良好,只要系统中大部分个体良好,系统就要能良好地运行下去。而如何保证系统中大多数行为一致,就能达到最终系统所有个体作为一个整体行为一致呢?这其实就是分布式一致性算法需要解决的问题,其实是提出了更高的要求。其中最核心的要求就是两点:一是safety,即无论如何都要保证系统不出问题;二是liveness,即系统要前进、要运行、要为client服务,不能只是不出问题,还要保证能及时地干活、能良好地运转下去。)