源码阅读:究竟怎样才算是读懂了?
市面上有很多源码分析的文章,就我看到的而言,基本的套路就是梳理流程,讲一讲每个模块的功能,整篇文章有一大半都是直接挂源码。我不禁怀疑,作者真的看懂了吗?为什么我看完后还是什么都不懂呢?
事实上一个经过无数次版本迭代的框架源码并不适合初学者直接阅读,因为里面有太多细节,太多噪点,太多枝枝蔓蔓。要想真正理解框架的核心逻辑,必须剥茧抽丝,还原出一个纯净的雏形。如同 jQuery 最早的版本只有六百多行,我相信 Vue 的核心功能也只需要几百行就能实现。所以,读懂源码的标志就是还原,码越薄,真相就越清晰。
如何还原雏形?
一开始我设想的还原过程就是先删后拆。什么报错信息、参数校验、非核心功能全部砍掉,八千行变成了五千行。然后再拆,按功能模块将一个 Vue.js 拆分成 util.js, observer.js, watcher.js …
理想状态下,我应该能够理解源码了吧,可做完解剖手术后,我发现里面的逻辑依然纷繁复杂,剪不断,理还乱,草蛇灰线,伏脉千里,即便换了一个更早期更简短的版本,仍然很快又陷入了永无止境的细节中。
最终我得出结论:与其根据源码还原雏形,不如参考源码自己从头实现一个雏形。
定义核心
Version:2.0.4
只考虑 runtime 版本,不考虑模板编译,不考虑服务端渲染。
核心功能:响应式的数据绑定、虚拟 DOM、diff 算法、patch 方法(用于更新真实 DOM)
如果你对上述基础概念完全不熟,建议先积累一些背景知识:关于响应式绑定参考这篇文章,关于 virtual dom 和 diff 算法参考这个视频。当然,这些并不是必须的。
目标

事实上,Vue-cli 生成的项目中, 标签中的内容都会被编译为 render 函数,render 函数返回整棵虚拟节点树。我们最终要实现一个 Vue,来完成上面的示例。
当 new Vue() 的时候发生了什么?
我们的实现会参考源码的套路,但会大量的简化其中的细节。为了理解源码的结构,最好的突破口就是了解程序的起点 new Vue() 的背后究竟发生了什么。
简单梳理下源码的执行流:
=> 初始化生命周期
=> 初始化事件系统
=> 初始化state,依次处理 props、data、computed …
=> 开始渲染 _mount() => _render() 返回 vdom=> _update() => __patch__() 更新真实DOM
更详细的说明可以参考这篇文章,我们只会实现其中最核心的部分
第一步:将虚拟 DOM 树渲染到真实的 DOM
每一个 DOM 节点都是一个 node 对象,这个对象含有大量的属性与方法,虚拟 DOM 其实就是超轻量版的 node 对象。

我们要生成的 DOM 树看上去是这样的:
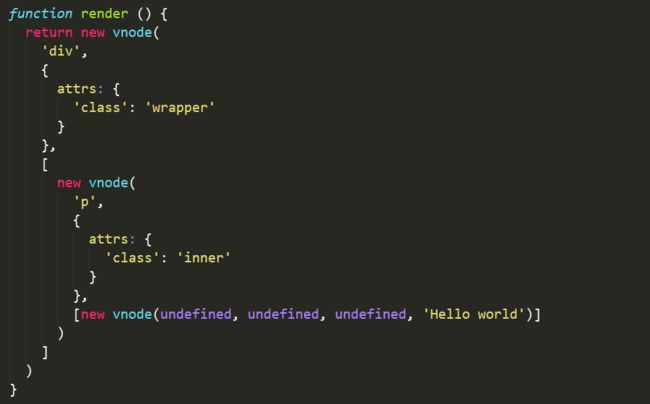
关于 data 参数的属性,请参考官方文档
随后我们会通过 createElm 方法和 createChildren 方法的相互调用,遍历整棵虚拟节点树,生成真实的 DOM 节点树,最后替换到挂载点。
完整代码
第二步:修改数据,执行 diff 算法,并将变化的部分 patch 到真实 DOM

diff 算法的逻辑比较复杂,可以单独摘出来研究,由于我们的目的是理解框架的核心逻辑,因此代码实现里只考虑了最简单的情形。
完整代码
第三步:对数据做响应式处理,当数据变化时,自动执行更新方法

data 中的每一个属性都会被处理为存取器属性,同时每一个属性都会在闭包中维护一个属于自己的 dep 对象,用于存放该属性的依赖项。当属性被赋予新的值时,就会触发 set 方法,并通知所有依赖项进行更新。
完整代码
Vue 渐进式的特点,使其上手极其容易,我相信,渐进式的展现框架逻辑的实现过程,也会使理解变得更容易。