最近遇到一例,HBase 指定大量列集合的场景下,并发拉取数据,应用卡住不响应的情形。记录一下。
问题背景
退款导出中,为了获取商品规格编码,需要从 HBase 表 T 里拉取对应的数据。 T 对商品数据的存储采用了 表名:字段名:id 的列存储方式。由于这个表很大,且为详情公用,因此不方便使用 scanByPrefixFilter 的方式,担心引起这个表访问的不稳定,进而影响详情和导出的整体稳定性。
要用 multiGet 的方式来获取多个订单的指定列字段的数据,需要动态生成相应的列名集合,然后在 HBase 获取数据的 API 参数里指定。比如有订单 E 含有三个商品 ID, I001, I002, I003, 数据库里的表名为 item , 字段名为 sku , 就需要动态生成列名集合: item:sku:I001, item:sku:I002, item:sku:I003 。
现有记录集合 List
然而,当 HBase 指定列名集合比较大的时候, 似乎是有问题的。堆内存爆了。

CPU 曲线也是随之陡然飙升。
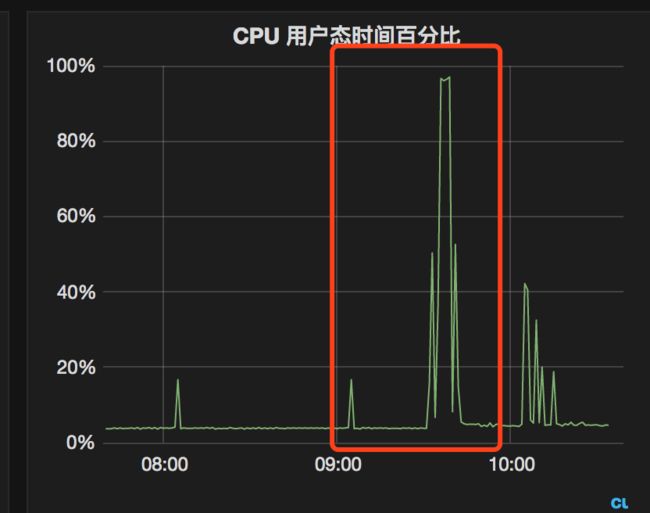
排查求解
锁定疑点
在预发环境可以容易地复现。这为排查解决问题提供了很大的便利。
排查问题的第一要务是缩小范围,检查是什么变更导致了问题。从错误日志上看,很容易看出是 HBase 获取数据卡住了。 而此次的变更是增加了一个可以并发获取 HBase 指定列集合的数据的插件。这个 HBase 插件是复用了原来的 HAHBaseService 获取数据的能力,而这个能力线上运行一直稳定良好。不同在于,这次会指定大量的列名去查询。难道 HBase 在指定大量列名集合时拉取数据会有问题? 咨询数据大佬原大哥,答复是不会。 那是为什么呢 ? 做个实验尝试解决下。
尝试解决
原来的代码如下:
private List fetchDataFromHBase(List data, List rowKeys, HBaseDataConf hbaseDataConf) {
List hbaseResults = multiTaskExecutor.exec(rowKeys, subRowkeys -> haHbaseService.getRawData(subRowkeys, hbaseDataConf.getTable(), "cf", generateCols(hbaseDataConf.getFetchDataConf(), data), "", true), 200);
return hbaseResults;
} 这里使用了一个通用的并发获取数据的能力 multiTaskExecutor.exec ,只需要指定处理函数即可。详见: “精练代码:一次Java函数式编程的重构之旅” 的“抽离并发处理”部分。
问题出在 subRowkeys -> haHbaseService.getRawData(subRowkeys, hbaseDataConf.getTable(), "cf", generateCols(hbaseDataConf.getFetchDataConf(), data) 这一行上。 data 是记录全集,generalCols 会拿到所有订单的商品 ID 对应的列集合。而 subRowkeys 是按照指定任务数分割后的 HBase Rowkeys 子集合。这意味着每个子任务都拿到全部的列集合去拉取 HBase 数据。 假如 data 有 8000 条记录,subRowkeys 有 200 条, 那么会生成 400 个任务,每个任务都针对 generateCols(hbaseDataConf.getFetchDataConf(), data) 会生成几万条动态列集合。 显然, generateCols 里的 data 应该是对应划分后的 subRowkeys 的那些子记录集合,而不是全部记录集合。 也就是说,动态列数量应该是 200 * 指定列字段数量,而不是 8000 * 指定列字段数量。
试着先减少列集合,看看是否能解决问题。
修改后的代码如下:
private List fetchDataFromHBase(List data, HBaseDataConf hbaseDataConf) {
List hbaseResults = multiTaskExecutor.exec(data, partData -> fetchDataFromHBasePartially(partData, hbaseDataConf), 200);
return hbaseResults;
}
private List fetchDataFromHBasePartially(List partData, HBaseDataConf hbaseDataConf) {
List rowKeys = RowkeyUtil.buildRowKeys(partData, hbaseDataConf.getRowkeyConf());
logger.info("hbase-rowkeys: {}", rowKeys.size());
return haHbaseService.getRawData(rowKeys, hbaseDataConf.getTable(),
"cf", generateCols(hbaseDataConf.getFetchDataConf(), partData), "", true);
} 这里,generalCols 用来生成的动态列集合就只对应分割后的记录集合。修改后,问题就解决了。
原因探求
调试日志
为什么指定数万条列名时 HBase 获取数据内存爆掉了呢? 是 HBase 不支持拉取大量指定列的数据吗?
打印调试日志是排查问题的第一利器。在获取 HBase 数据的地方打印调试日志:
String cf = (cfName == null) ? "cf" : cfName;
logger.info("columns: {}", columns);
List gets = buildGets(rowKeyList, cf, columns, columnPrefixFilters);
logger.info("after buildGet: {}", gets.size());
Result[] results = getFromHbaseFunc.apply(tableName, gets);
logger.info("after getHBase: {}", results.length); 发现: columns 日志打出来了, after buildGet 没有打出来。程序卡住了。可以推断,是 buildGets 这一步卡住了。 与我想象中的不太符合。我以为是 buildGets 不大可能出问题,而更可能在拉取数据本身上出问题。 不过,现在现实明白滴告诉我们: buildGets 卡住了。 而且这一步是 CPU 操作,与之前的 CPU 曲线飙升是很吻合的。
确定嫌疑
写一个单测,做个小实验。 先弄个串行的实验。 1000个订单, 列数从 2000 增长 24000
@Test
def "testMultiGetsSerial"() {
expect:
def columnSize = 12
def rowkeyNums = 1000
def rowkeys = (1..rowkeyNums).collect { "E001" + it }
(1..columnSize).each { colsSize ->
def columns = (1..(colsSize*2000)).collect { "item:sku:" + it }
def start = System.currentTimeMillis()
List gets = new HAHbaseService().invokeMethod("buildGets", [rowkeys, "cf", columns, null])
gets.size() == rowkeyNums
def end = System.currentTimeMillis()
def cost = end - start
println "num = $rowkeyNums , colsSize = ${columns.size()}, cost (ms) = $cost"
}
} 耗时如下:
num = 1000 , colsSize = 2000, cost (ms) = 2143
num = 1000 , colsSize = 4000, cost (ms) = 3610
num = 1000 , colsSize = 6000, cost (ms) = 5006
num = 1000 , colsSize = 8000, cost (ms) = 8389
num = 1000 , colsSize = 10000, cost (ms) = 8921
num = 1000 , colsSize = 12000, cost (ms) = 12467
num = 1000 , colsSize = 14000, cost (ms) = 11845
num = 1000 , colsSize = 16000, cost (ms) = 12589
num = 1000 , colsSize = 18000, cost (ms) = 20068
java.lang.OutOfMemoryError: GC overhead limit exceeded再针对实际运行的并发情况做个实验。 从 1000 到 6000 个订单,列集合数量 从 1000 - 10000。 用并发来构建 gets 。
@Test
def "testMultiGetsConcurrent"() {
expect:
def num = 4
def columnSize = 9
(1..num).each { n ->
def rowkeyNums = n*1000
def rowkeys = (1..rowkeyNums).collect { "E001" + it }
(1..columnSize).each { colsSize ->
def columns = (1..(colsSize*1000)).collect { "tc_order_item:sku_code:" + it }
def start = System.currentTimeMillis()
List gets = taskExecutor.exec(
rowkeys, { new HAHbaseService().invokeMethod("buildGets", [it, "cf", columns, null]) } as Function, 200)
gets.size() == rowkeyNums
def end = System.currentTimeMillis()
def cost = end - start
println "num = $rowkeyNums , colsSize = ${columns.size()}, cost (ms) = $cost"
println "analysis:$rowkeyNums,${columns.size()},$cost"
}
}
} 耗时如下:
num = 1000 , colsSize = 1000, cost (ms) = 716
num = 1000 , colsSize = 2000, cost (ms) = 1180
num = 1000 , colsSize = 3000, cost (ms) = 1378
num = 1000 , colsSize = 4000, cost (ms) = 2632
num = 1000 , colsSize = 5000, cost (ms) = 2130
num = 1000 , colsSize = 6000, cost (ms) = 4328
num = 1000 , colsSize = 7000, cost (ms) = 4524
num = 1000 , colsSize = 8000, cost (ms) = 5612
num = 1000 , colsSize = 9000, cost (ms) = 5804
num = 2000 , colsSize = 1000, cost (ms) = 1416
num = 2000 , colsSize = 2000, cost (ms) = 1486
num = 2000 , colsSize = 3000, cost (ms) = 2434
num = 2000 , colsSize = 4000, cost (ms) = 4925
num = 2000 , colsSize = 5000, cost (ms) = 5176
num = 2000 , colsSize = 6000, cost (ms) = 7217
num = 2000 , colsSize = 7000, cost (ms) = 9298
num = 2000 , colsSize = 8000, cost (ms) = 11979
num = 2000 , colsSize = 9000, cost (ms) = 20156
num = 3000 , colsSize = 1000, cost (ms) = 1837
num = 3000 , colsSize = 2000, cost (ms) = 2460
num = 3000 , colsSize = 3000, cost (ms) = 4516
num = 3000 , colsSize = 4000, cost (ms) = 7556
num = 3000 , colsSize = 5000, cost (ms) = 6169
num = 3000 , colsSize = 6000, cost (ms) = 19211
num = 3000 , colsSize = 7000, cost (ms) = 180950
……可见,耗时随着rowkey 数应该是线性增长; 而随着指定列集合的增大,会有超过线性的增长和波动。超线性增长是算法引起的,波动应该是由线程池执行引起的。
如果有 8800 个订单,指定 24000 个列, 可想而知,有多慢了。 上帝都在排队了。
探究原理
查看 buildGets 代码,其中嫌疑最大的就是 addColumn 方法。这个方法添加列时,将列加入了 NavigableSet
那么, HBase 列数据集的结构为什么要用排序的 Set 而不用普通的 Set 呢?是因为指定列名集合从 HBase 获取数据时,HBase 会将满足条件的数据拿出来,依次与指定列进行匹配过滤,这时候要应用到查找列功能。当指定列非常大时,TreeSet 的效率比 HashSet 的要大。
为什么内存爆掉了
回到那个串行的单测实验 testMultiGetsSerial, 打印下不同列数目下生成每一个 Get 的列结构中的 familyMap 的大小:
try {
ObjectInfo objectInfo = new ClassIntrospector().introspect(gets.get(0).getFamilyMap());
System.out.println("columnSize: " + columns.size() + ", columnMap: " + objectInfo.getDeepSize());
} catch (IllegalAccessException e) {
}运行结果如下:
columnSize: 2000, columnMap: 137112
columnSize: 4000, columnMap: 275112
columnSize: 6000, columnMap: 413112
columnSize: 8000, columnMap: 551112
columnSize: 10000, columnMap: 689112
columnSize: 12000, columnMap: 829112
columnSize: 14000, columnMap: 969112
columnSize: 16000, columnMap: 1109112
columnSize: 18000, columnMap: 1249112
columnSize: 20000, columnMap: 1389112
columnSize: 22000, columnMap: 1529112也就是说,HBase 指定列名有 22000 个时,每个 Get 的列对象都会占用 1.46 MB 的大小,每个 column 平均占用 68 - 69 个字节。 1000 个订单会占用 1.46 G 的大小。在串行的情形下, 8000 个订单会占用 11.664 G 的内存。如果内存不及时释放,显然就会堆内存爆掉了。
为什么CPU飙升
HBase 列的结构是 Map , NavigableSet 是基于 TreeMap 来实现的。因此,添加大量列名时,是一个构建红黑树的过程,涉及到大量比较运算(列名前缀还是相同的,每次都需要重复比较列名前缀),是 CPU 密集型,因此 CPU 曲线会飙升。 从前面的耗时来看,添加一个元素平均约 1ms 左右,这个时间不随 TreeMap 已有元素数目而变化。 添加 22000 个元素则需要 20s 左右了。
TreeMap 及红黑树的实现,将在专门的文章进行讨论。
附录
在网上找的程序,查看对象的占用内存大小。
package zzz.study.util;
import java.lang.reflect.Array;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.IdentityHashMap;
import java.util.List;
import java.util.Map;
import sun.misc.Unsafe;
public class ClassIntrospector {
private static final Unsafe unsafe;
/** Size of any Object reference */
private static final int objectRefSize;
static {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
// 可以通过Object[]数组得到oop指针究竟是压缩后的4个字节还是未压缩的8个字节
objectRefSize = unsafe.arrayIndexScale(Object[].class);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/** Sizes of all primitive values */
private static final Map, Integer> primitiveSizes;
static {
primitiveSizes = new HashMap, Integer>(10);
primitiveSizes.put(byte.class, 1);
primitiveSizes.put(char.class, 2);
primitiveSizes.put(int.class, 4);
primitiveSizes.put(long.class, 8);
primitiveSizes.put(float.class, 4);
primitiveSizes.put(double.class, 8);
primitiveSizes.put(boolean.class, 1);
}
/**
* Get object information for any Java object. Do not pass primitives to
* this method because they will boxed and the information you will get will
* be related to a boxed version of your value.
*
* @param obj
* Object to introspect
* @return Object info
* @throws IllegalAccessException
*/
public ObjectInfo introspect(final Object obj)
throws IllegalAccessException {
try {
return introspect(obj, null);
} finally { // clean visited cache before returning in order to make
// this object reusable
m_visited.clear();
}
}
// we need to keep track of already visited objects in order to support
// cycles in the object graphs
private IdentityHashMap m_visited = new IdentityHashMap(
100);
private ObjectInfo introspect(final Object obj, final Field fld)
throws IllegalAccessException {
// use Field type only if the field contains null. In this case we will
// at least know what's expected to be
// stored in this field. Otherwise, if a field has interface type, we
// won't see what's really stored in it.
// Besides, we should be careful about primitives, because they are
// passed as boxed values in this method
// (first arg is object) - for them we should still rely on the field
// type.
boolean isPrimitive = fld != null && fld.getType().isPrimitive();
boolean isRecursive = false; // will be set to true if we have already
// seen this object
if (!isPrimitive) {
if (m_visited.containsKey(obj))
isRecursive = true;
m_visited.put(obj, true);
}
final Class type = (fld == null || (obj != null && !isPrimitive)) ? obj
.getClass() : fld.getType();
int arraySize = 0;
int baseOffset = 0;
int indexScale = 0;
if (type.isArray() && obj != null) {
baseOffset = unsafe.arrayBaseOffset(type);
indexScale = unsafe.arrayIndexScale(type);
arraySize = baseOffset + indexScale * Array.getLength(obj);
}
final ObjectInfo root;
if (fld == null) {
root = new ObjectInfo("", type.getCanonicalName(), getContents(obj,
type), 0, getShallowSize(type), arraySize, baseOffset,
indexScale);
} else {
final int offset = (int) unsafe.objectFieldOffset(fld);
root = new ObjectInfo(fld.getName(), type.getCanonicalName(),
getContents(obj, type), offset, getShallowSize(type),
arraySize, baseOffset, indexScale);
}
if (!isRecursive && obj != null) {
if (isObjectArray(type)) {
// introspect object arrays
final Object[] ar = (Object[]) obj;
for (final Object item : ar)
if (item != null)
root.addChild(introspect(item, null));
} else {
for (final Field field : getAllFields(type)) {
if ((field.getModifiers() & Modifier.STATIC) != 0) {
continue;
}
field.setAccessible(true);
root.addChild(introspect(field.get(obj), field));
}
}
}
root.sort(); // sort by offset
return root;
}
// get all fields for this class, including all superclasses fields
private static List getAllFields(final Class type) {
if (type.isPrimitive())
return Collections.emptyList();
Class cur = type;
final List res = new ArrayList(10);
while (true) {
Collections.addAll(res, cur.getDeclaredFields());
if (cur == Object.class)
break;
cur = cur.getSuperclass();
}
return res;
}
// check if it is an array of objects. I suspect there must be a more
// API-friendly way to make this check.
private static boolean isObjectArray(final Class type) {
if (!type.isArray())
return false;
if (type == byte[].class || type == boolean[].class
|| type == char[].class || type == short[].class
|| type == int[].class || type == long[].class
|| type == float[].class || type == double[].class)
return false;
return true;
}
// advanced toString logic
private static String getContents(final Object val, final Class type) {
if (val == null)
return "null";
if (type.isArray()) {
if (type == byte[].class)
return Arrays.toString((byte[]) val);
else if (type == boolean[].class)
return Arrays.toString((boolean[]) val);
else if (type == char[].class)
return Arrays.toString((char[]) val);
else if (type == short[].class)
return Arrays.toString((short[]) val);
else if (type == int[].class)
return Arrays.toString((int[]) val);
else if (type == long[].class)
return Arrays.toString((long[]) val);
else if (type == float[].class)
return Arrays.toString((float[]) val);
else if (type == double[].class)
return Arrays.toString((double[]) val);
else
return Arrays.toString((Object[]) val);
}
return val.toString();
}
// obtain a shallow size of a field of given class (primitive or object
// reference size)
private static int getShallowSize(final Class type) {
if (type.isPrimitive()) {
final Integer res = primitiveSizes.get(type);
return res != null ? res : 0;
} else
return objectRefSize;
}
}
package zzz.study.util;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class ObjectInfo {
/** Field name */
public final String name;
/** Field type name */
public final String type;
/** Field data formatted as string */
public final String contents;
/** Field offset from the start of parent object */
public final int offset;
/** Memory occupied by this field */
public final int length;
/** Offset of the first cell in the array */
public final int arrayBase;
/** Size of a cell in the array */
public final int arrayElementSize;
/** Memory occupied by underlying array (shallow), if this is array type */
public final int arraySize;
/** This object fields */
public final List children;
public ObjectInfo(String name, String type, String contents, int offset, int length, int arraySize,
int arrayBase, int arrayElementSize)
{
this.name = name;
this.type = type;
this.contents = contents;
this.offset = offset;
this.length = length;
this.arraySize = arraySize;
this.arrayBase = arrayBase;
this.arrayElementSize = arrayElementSize;
children = new ArrayList( 1 );
}
public void addChild( final ObjectInfo info )
{
if ( info != null )
children.add( info );
}
/**
* Get the full amount of memory occupied by a given object. This value may be slightly less than
* an actual value because we don't worry about memory alignment - possible padding after the last object field.
*
* The result is equal to the last field offset + last field length + all array sizes + all child objects deep sizes
* @return Deep object size
*/
public long getDeepSize()
{
//return length + arraySize + getUnderlyingSize( arraySize != 0 );
return addPaddingSize(arraySize + getUnderlyingSize( arraySize != 0 ));
}
long size = 0;
private long getUnderlyingSize( final boolean isArray )
{
//long size = 0;
for ( final ObjectInfo child : children )
size += child.arraySize + child.getUnderlyingSize( child.arraySize != 0 );
if ( !isArray && !children.isEmpty() ){
int tempSize = children.get( children.size() - 1 ).offset + children.get( children.size() - 1 ).length;
size += addPaddingSize(tempSize);
}
return size;
}
private static final class OffsetComparator implements Comparator
{
@Override
public int compare( final ObjectInfo o1, final ObjectInfo o2 )
{
return o1.offset - o2.offset; //safe because offsets are small non-negative numbers
}
}
//sort all children by their offset
public void sort()
{
Collections.sort( children, new OffsetComparator() );
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder();
toStringHelper( sb, 0 );
return sb.toString();
}
private void toStringHelper( final StringBuilder sb, final int depth )
{
depth( sb, depth ).append("name=").append( name ).append(", type=").append( type )
.append( ", contents=").append( contents ).append(", offset=").append( offset )
.append(", length=").append( length );
if ( arraySize > 0 )
{
sb.append(", arrayBase=").append( arrayBase );
sb.append(", arrayElemSize=").append( arrayElementSize );
sb.append( ", arraySize=").append( arraySize );
}
for ( final ObjectInfo child : children )
{
sb.append( '\n' );
child.toStringHelper(sb, depth + 1);
}
}
private StringBuilder depth( final StringBuilder sb, final int depth )
{
for ( int i = 0; i < depth; ++i )
sb.append( "\t");
return sb;
}
private long addPaddingSize(long size){
if(size % 8 != 0){
return (size / 8 + 1) * 8;
}
return size;
}
}
结语
因为一个比较粗糙的编码错误,堆内存爆了; 又因为这个错误,深入了解了 HBase 指定列名集合时获取数据的一些内幕。 实际上,这是一个数据结构与算法引发的问题。 可见,数据结构与算法在实际工作中还是非常重要的。
任务: 学习 TreeMap 及红黑树的实现。
【完】