Surrogate loss function,中文可以译为代理损失函数。当原本的loss function不便计算的时候,我们就会考虑使用surrogate loss function。
在二元分类问题中,假如我们有\(n\)个训练样本\(\{(X_1,y_1),(X_2,y_2),\cdots,(X_n,y_n)\}\),其中\(y_i\in\{0,1\}\)。为了量化一个模型的好坏,我们通常使用一些损失函数,损失函数越小,模型越好。最常用的损失函数就是零一损失函数\(l(\hat y,y)\)。
\[ l(y, \hat y)=\sum_{i=1}^m\chi(y_i\neq\hat y_i). \]
比如说,测试集里有5个数据点,真实分类为\(y=(1,1,1,-1,-1)\),预测分类为\(\hat y =(1,-1,1,1,-1)\)。那么
\[ l(y, \hat y)=0+1+0+1+0=2. \]
对于一个loss function\(l\),我们的目标是要找到一个最优的分类器\(h\),使得这个分类器在测试样本上的期望损失最小。数学式子表达是
\[ \min_{h}\mathbb{E}_{X\times y}[l(y, h(X))]. \]
理论上,我们是可以直接对上式进行优化,得到最优的分类器\(h\)。然而这个过程是非常困难的(甚至不可行)。其一是因为\(X\times y\)的概率分布是未知的,所以计算loss的期望是不可行的。另外一个难处是这个期望值很难进行优化,因为这个loss function是非连续的,这个优化问题本质是NP-Hard的。举个例子来说,假定\(X\in\mathbb{R}^2\),我们希望找一个线性分类器
\[ h(X)=\begin{cases}1, ~Xw\geq 0\\ -1, ~Xw<0 \end{cases} \]
使得loss的期望最小化。所以我们也就是求解\(w=(w_1, w_2)^T\)。关于\(w_1,w_2\)以及loss的图像大致如下,
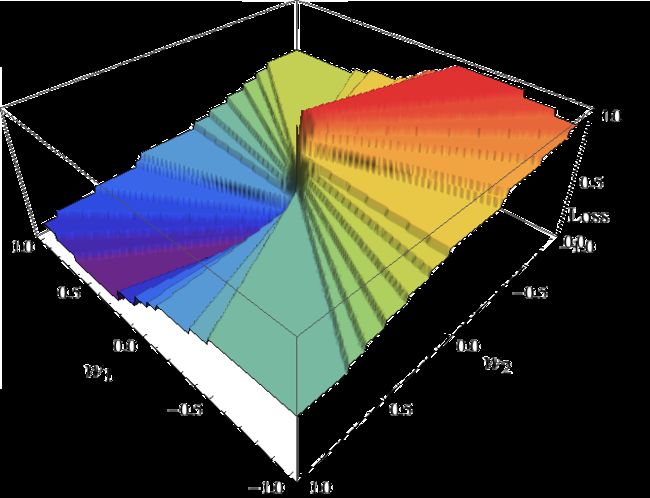
这个函数显然是非连续的。我们常用的优化方法,比如梯度下降,对此都失效了。正因此,我们可以考虑一个与零一损失相接近的函数,作为零一损失的替身。这个替身我们就称作surrogate loss function代理损失函数。为了计算的便利,这个函数通常是凸函数。例如逻辑回归的loss function,\(\log(1+e^{-yXw})\),就是光滑可导的,更容易被求解。
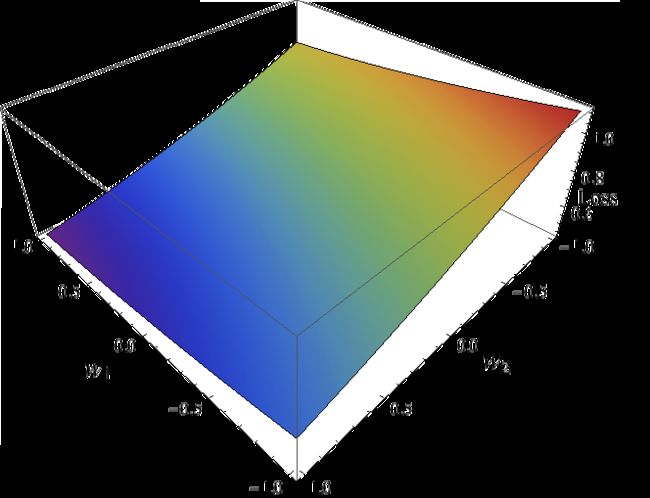
最后补充几句。当我们把原来的零一损失函数替代为其他损失函数的时候,我们自然会问,当我们对代理损失函数进行优化的时候,原来的零一损失是否也被最小化了?它们的差距是多少呢?如果最优化代理损失函数的同时我们也最优化了原本的损失函数,我们就称校对性(calibration)或者一致性(consistency)。这个性质与我们所选择的代理损失函数相关。一个重要的定理是,如果代理损失函数是凸函数,并且在0点可导,其导数小于0,那么它一定是具有一致性的。这也是为什么我们通常选择凸函数作为我们的loss function的原因之一。
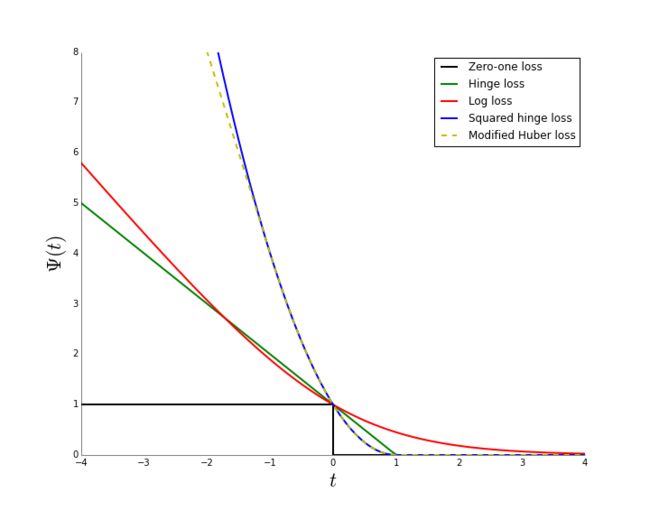
下图是零一损失函数与logloss,hinge loss,squared hinge loss以及modified Huber loss的联系。