温故而知新
子曰:“温故而知新,可以为师矣”。的确是这样,对于技术知识的学习,我深有感悟。每一本书,每一个知识点,不去认真的读上个2~3遍,根本无法理解其中的道理。借着最近在学习SSH框架的机会,也抽时间把Java基础知识好好再总结一遍,再系统的通过博文的形式将相关的知识树,知识模块总结出来。一来做到查缺补漏;二来从整体上再好好把握Java的基础脉络。
Java异常体系
写过C/C++的程序员无不佩服Java中的异常处理,功能强大不说,而且可以做到傻瓜式入门。想想当初写Java的时候,时不时就加上这么一段,管它对不对,反正是好的:
try {
// 可能会发生异常的程序代码
} catch (Exception ex) {
// 捕获并处理try抛出的异常类型ex
} finally {
// 无论是否发生异常,都将执行的语句块
} 就是这样无头无脑的用,但是这背后的东西并没有过多的去了解和学习,直至有一天发现,我需要去更多的学习一下Java的异常。先从Java异常的类体系说起,如下图所示:
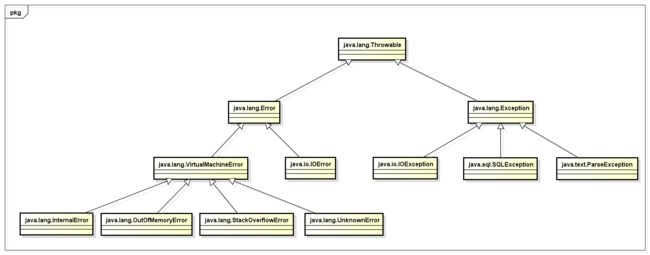
上图就是我们经常使用的一些类的继承结构图。这是一幅非常普通的类继承结构图,通过之后的学习,我们可以将上图继续总结,从而归纳为下面这样:
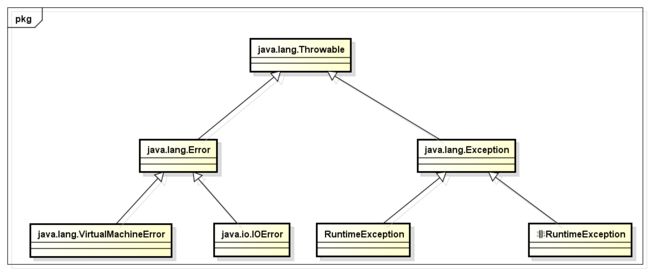
在Java中异常被当做对象来处理,根类是java.lang.Throwable类,所有异常类都必须直接或间接继承自Throwable类,Throwable类分为以下两个子类:
Error类,它是error类型异常的父类;error类型异常是程序无法处理的异常。一般发生这种异常时,JVM会选择终止程序,因此在我们编写程序时,并不需要关心error类异常Exception类,它是exception类型异常的父类,这类异常就是我们编码时需要注意的异常。而对于Exception类,它又分为以下两大类:- RuntimeException类,它是所有运行时异常的父类,典型的代表有:
NullPointerException、IndexOutOfBoundsException、IllegalArgumentException等 - 非RuntimeException类,它是所有非运行时异常的父类,典型的代表有:
IOException、SQLException等
- RuntimeException类,它是所有运行时异常的父类,典型的代表有:
关于RuntimeException和非RuntimeException,下面再进行详细的总结。
细说异常分类
上面说到Exception类可以分为RuntimeException类和非RuntimeException类。那么具体来说,何为RuntimeException类异常?何又为非RuntimeException类异常呢?
RuntimeException类异常,又被称为Unchecked Exception(非检查异常);Unchecked表示在编译阶段,Java编译器不要求必须进行异常捕获处理或者抛出声明,而要到运行期间才能由JVM去决定是否要抛出这类异常。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。需要注意的是,Error类错误也是属于RuntimeException类异常。例如下面这段代码:
public class Test
{
public static void main(String[] args)
{
int[] intArray = { 1, 2, 3, 4, 5 };
System.out.println(intArray[7]); // 越界访问数组
}
}很明显的,我越界访问数组了;但是在编译的时候,这并没有问题,直到运行时,才会抛出java.lang.ArrayIndexOutOfBoundsException异常。
非RuntimeException类异常,又被称为Checked Exceptions(检查异常);这类异常表示在编译阶段,编译器会检查此类异常,如果代码中有明确标明抛出此类异常的代码,而却没有try...catch...这类异常处理结构,此时就会出现编译错误。例如下面这段代码:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
public class Test
{
public static void main(String[] args)
{
File file = new File("c:/city.xml");
BufferedReader reader = null;
reader = new BufferedReader(new FileReader(file));
}
}由于new FileReader(file)的声明中明确表明了会抛出java.io.FileNotFoundException异常,而我在代码中却没有明确的try...catch...代码块,导致在编译的时候,上面这段代码都无法通过。
这就是所谓的RuntimeException类和非RuntimeException类异常。
那些不好的习惯
在编码的时候,必不可少的要写各种try...catch...finally...。虽然写的不少,基本上都是千篇一律,并没有真正的考虑过如何把这个try...catch...finally...写好,因此养成了以下这些毛病。
直接打印异常信息到页面上
大家可能都见过这样的情况,访问某个JSP页面出错了以后,在页面上显示一堆的错误堆栈信息。这些信息对于开发人员来说是非常重要的,但是对于用户来说就是“天书”。为了避免这种情况的发生,我们在编码时就需要格外的注意,逻辑处理要正确,防止出现非检查异常。异常耦合
我们在开发的时候,都是分模块的,比如最流行的MVC结构,它要求各个部分应尽最大可能的解耦。但是不尽人意的是,如果处理不好异常处理代码,则会增加模块之间的耦合度。例如以下这段代码:public UserInfo getUserInfoById(String id) throw SQLException { // 根据ID查询数据库,获取用户信息 }上面这段代码咋一看没什么问题,但是从设计耦合角度仔细考虑一下,这里的
SQLException污染到了上层调用代码,调用层需要显式的利用try...catch...捕捉,或者向更上层次进一步抛出。根据设计隔离原则,我们可以适当修改成:public UserInfo getUserInfoById(String id) { try{ // 根据ID查询数据库,获取用户信息 } catch(SQLException e){ //利用非检测异常封装检测异常,降低层次耦合 throw new RuntimeException(ErrorCode, e); } finally{ //关闭连接,清理资源 } }忽略异常
我们经常写出这样的代码:public UserInfo getUserInfoById(String id) { try{ // 根据ID查询数据库,获取用户信息 } catch(SQLException e){ // 打印错误信息 ex.printStacktrace(); } }我们捕获了异常以后,就打印了异常堆栈信息;对于开发调试来说,还有用处,但是对于生产环境来说,我们需要将异常信息写到日志文件,而此处只是打印了异常,并没有处理,接下来程序还会继续执行,这样就会进一步导致更严重的问题。所以,在代码中这种简单的打印错误,却忽略了正确的处理异常。
利用
Exception捕捉所有潜在的异常
我们也经常写出这样的代码:public UserInfo getUserInfoById(String id) { try{ // 根据ID查询数据库,获取用户信息 } catch(Exception e){ // 打印错误信息 throw new RuntimeException(ErrorCode, e); } }有的时候,我们会为了偷懒,就使用一个
Exception来捕获所有的异常;但是如果这样,如果真的出现了异常,我们就无法准确的定位具体的异常,从而为解决问题增加了难度。对此,我们就需要对抛出的异常进行细分,单独处理每个异常。多次打印异常
有些时候,我们编写代码很谨慎,一旦出现了异常就赶紧捕获异常,记录异常堆栈,比如这样的[代码][3]:class A { private static Logger logger = LoggerFactory.getLogger(A.class); public void process(){ try{ //实例化 B 类,可以换成其它注入等方式 B b = new B(); b.process(); //other code might cause exception } catch(XXXException e){ //如果 B 类 process 方法抛出异常,异常会在 B 类中被打印,在这里也会被打印,从而会打印 2 次 logger.error(e); throw new RuntimeException(/* 错误代码 */ errorCode, /*异常信息*/msg, e); } } } class B{ private static Logger logger = LoggerFactory.getLogger(B.class); public void process(){ try{ //可能抛出异常的代码 } catch(XXXException e){ logger.error(e); throw new RuntimeException(/* 错误代码 */ errorCode, /*异常信息*/msg, e); } } }通过仔细的阅读代码,我们就会发现会多次记录异常堆栈信息,不仅带来效率问题,同时也会记录了很多的冗余信息,给问题定位带来了麻烦;如果调用层次更多一些的话,那更不敢想象会记录多少异常堆栈。
除了上面这些坏习惯,我们在编码时还要注意很多,很多,这里就不一一举例了。
设计一个异常处理框架
说的再多,我们终究需要在我们的代码中使用异常,那么如何设计一个简单、易用的异常处理框架呢?当设计一个异常处理框架时,需要基于以下几点去考虑:
- 用户不明白什么是异常;出现异常时,上层一定要具有良好的用户体验
- 自定义一个异常,将所有其它标准异常均转为自定义异常,实现异常的统一管理
- 下层只捕获异常,抛出异常;异常的处理统一交给上层
- 异常信息一定要可配置化
基于上面几点进行考虑,以后在阅读开源代码时,也可以基于上述几点去分析。
总结
基础知识的重要性不言而喻,只有明白了其中的缘由,在编码时才能做到心中有数。希望这篇文章对大家有帮助。
2015年12月22日 于呼和浩特。