redis-cluster
1.并发问题
redis官方生成可以达到 10万/每秒,每秒执行10万条命令
假如业务需要每秒100万的命令执行呢?2.客户端分片
redis3.0集群采用P2P模式,完全去中心化,将redis所有的key分成了16384个槽位,每个redis实例负责一部分slot,集群中的所有信息通过节点数据交换而更新
redis实例集群主要思想是将redis数据的key进行散列,通过hash函数特定的key会映射到指定的redis节点上
3.数据分布原理
分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整个数据的一个子集。
- 常见的分区规则有哈希分区和顺序分区。
Redis Cluster采用哈希分区规则,因此接下来会讨论哈希分区规则。- 节点取余分区
- 一致性哈希分区
- 虚拟槽分区(redis-cluster采用的方式)
顺序分区

- 例如按照节点取余方式,分三个节点
- 1~100的数据对3取余,可以分为三类
- 余数为0
- 余数为1
- 余数为2
哈希分区

按照节点取余的方式,分三个节点:
- 1~100 的数据对3取余,可以分为三类
- 余数为0
- 余数为1
- 余数为2
- 那么同样的分4个节点就是hash(key)%4,节点取余的优点是简单,客户端分片直接是哈希+取余
- 1~100 的数据对3取余,可以分为三类
一致性哈希
- 客户端进行分片,哈希+顺时针取余
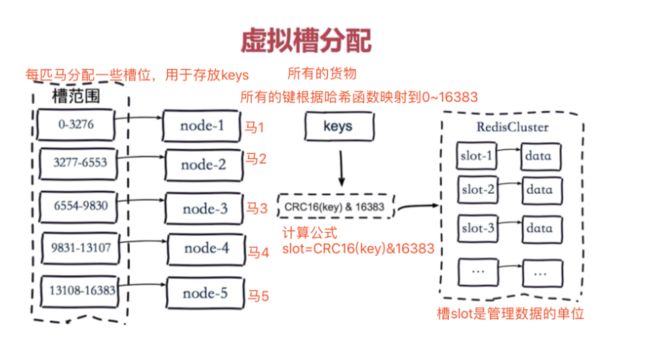
虚拟槽分区
把redis库分成16384个槽位,通过槽位管理key.
拿马儿举例子:
4.环境准备
#1.这里创建6个redis 的节点试验:
redis-7001.conf
redis-7002.conf
redis-7003.conf
redis-7004.conf
redis-7005.conf
redis-7006.conf
#2.创建文件夹存放6个节点
[root@xujunk data]#mkdir s21cluster
#3.写入配置:
[root@xujunk data]#cd s21cluster/
[root@xujunk s21cluster]#touch 7000.conf
[root@xujunk s21cluster]#vim 7000.conf
"""
port 7000
daemonize yes
dir "/opt/redis/data"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage no
"""
#4.另外5个节点也生成:
[root@xujunk s21cluster]#sed "s/7000/7001/g" 7000.conf > 7001.conf
[root@xujunk s21cluster]#sed "s/7000/7002/g" 7000.conf > 7002.conf
[root@xujunk s21cluster]#sed "s/7000/7003/g" 7000.conf > 7003.conf
[root@xujunk s21cluster]#sed "s/7000/7004/g" 7000.conf > 7004.conf
[root@xujunk s21cluster]#sed "s/7000/7005/g" 7000.conf > 7005.conf
[root@xujunk s21cluster]#ls
7000.conf 7001.conf 7002.conf 7003.conf 7004.conf 7005.conf
#创建存放日志文件:
[root@xujunk s21cluster]#mkdir -p /opt/redis/data
#启动集群
[root@xujunk s21cluster]#redis-server 7000.conf
[root@xujunk s21cluster]#redis-server 7001.conf
[root@xujunk s21cluster]#redis-server 7002.conf
[root@xujunk s21cluster]#redis-server 7003.conf
[root@xujunk s21cluster]#redis-server 7004.conf
[root@xujunk s21cluster]#redis-server 7005.conf
[root@xujunk s21cluster]#!ps
"""
ps -ef |grep redis
root 41169 1 0 23:11 ? 00:00:00 redis-server *:7000 [cluster]
root 41176 1 0 23:11 ? 00:00:00 redis-server *:7001 [cluster]
root 41183 1 0 23:11 ? 00:00:00 redis-server *:7002 [cluster]
root 41191 1 0 23:11 ? 00:00:00 redis-server *:7003 [cluster]
root 41198 1 0 23:11 ? 00:00:00 redis-server *:7004 [cluster]
root 41213 1 0 23:11 ? 00:00:00 redis-server *:7005 [cluster]
"""- 配置文件介绍
daemonize yes
dir "/opt/redis/data"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes #开启集群模式
cluster-config-file nodes-7000.conf #集群内部的配置文件
cluster-require-full-coverage no #redis cluster需要16384个slot都正常的时候才能对外提供服务,换句话说,只要任何一个slot异常那么整个cluster不对外提供服务。 因此生产环境一般为no5.分槽定位
- 法1:手动写C语言
法2:使用ruby大神,写的一个redis模块,自动分配
配置ruby脚本环境
yum install ruby #自动配置好,PATH环境变量下载ruby操作redis的模块
wget http://rubygems.org/downloads/redis-3.3.0.gem用ruby的包管理工具 gem 安装这个模块
gem install -l redis-3.3.0.gem通过ruby一键分配redis-cluster集群的槽位,找到机器上的redis-trib.rb命令,用绝对命令创建
开启集群,分配槽位。#找到机器上的redis-trib.rb命令 [root@xujunk s21cluster]#find / -name redis-trib.rb /opt/my_redis/redis-4.0.10/src/redis-trib.rb #开启集群,分配槽位 /opt/my_redis/redis-4.0.10/src/redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
6.验证
分配好集群后,可以向集群内写入数据了
[root@xujunk s21cluster]#redis-cli -c -p 7000
127.0.0.1:7000> keys *
(empty list or set)
127.0.0.1:7000> set name "Tom"
-> Redirected to slot [5798] located at 127.0.0.1:7001
OK
127.0.0.1:7001> keys *
1) "name"
#数据写入到了127.0.0.1:7001 里工作原理:
redis客户端任意访问一个redis实例,如果数据不在该实例中,通过重定向引导客户端访问所需要的redis实例。
总结:
redis主从:是备份关系, 我们操作主库,数据也会同步到从库。 如果主库机器坏了,从库可以上。就好比你 D盘的片丢了,但是你移动硬盘里边备份有。
redis哨兵:哨兵保证的是HA,保证特殊情况故障自动切换,哨兵盯着你的“redis主从集群”,如果主库死了,它会告诉你新的老大是谁。
redis集群:集群保证的是高并发,因为多了一些兄弟帮忙一起扛。同时集群会导致数据的分散,整个redis集群会分成一堆数据槽,即不同的key会放到不不同的槽中。
主从保证了数据备份,哨兵保证了HA 即故障时切换,集群保证了高并发性。