实际项目中,pythoner更加关注的是Python的性能问题,之前也写过一篇文章《Python性能优化》介绍Python性能优化的一些方法。而本文,关注的是Python的内存优化,一般说来,如果不发生内存泄露,运行在服务端的Python代码不用太关心内存,但是如果运行在客户端(比如移动平台上),那还是有优化的必要。具体而言,本文主要针对的Cpython,而且不涉及C扩展。
我们知道,Python使用引用技术和垃圾回收来管理内存,底层也有各种类型的内存池,那我们怎么得知一段代码使用的内存情况呢?工欲善其事必先利其器,直接看windows下的任务管理器或者linux下的top肯定是不准的。
本文地址:http://www.cnblogs.com/xybaby/p/7488216.html
Pytracemalloc
对于基本类型,可以通过sys.getsizeof()来查看对象占用的内存大小。以下是在64位Linux下的一些结果:
>>> import sys
>>> sys.getsizeof(1)24>>> sys.getsizeof([])72>>> sys.getsizeof(())56>>> sys.getsizeof({})280>>> sys.getsizeof(True)24
可以看到,即使是一个int类型(1)也需要占用24个字节,远远高于C语言中int的范围。因为Python中一切都是对象,int也不例外(事实上是PyIntObject),除了真正存储的数值,还需要保存引用计数信息、类型信息,更具体的可以参见《Python源码剖析》。
而对于更复杂的组合类型,复杂的代码,使用getsizeof来查看就不准确了,因为在Python中变量仅仅指向一个对象,这个时候就需要更高级的工具,比如guppy,pysizer,pytracemalloc,objgraph。在这里重点介绍pytracemalloc。
在Python3.4中,已经支持了pytracemalloc,如果使用python2.7版本,则需要对源码打补丁,然后重新编译。pytracemalloc在pep454中提出,主要有以下几个特点:
- Traceback where an object was allocated
- Statistics on allocated memory blocks per filename and per line number: total size, number and average size of allocated memory blocks
- Compute the differences between two snapshots to detect memory leaks
简单来说,pytracemalloc hook住了python申请和释放内存的接口,从而能够追踪对象的分配和回收情况。对内存分配的统计数据可以精确到每个文件、每一行代码,也可以按照调用栈做聚合分析。而且还支持快照(snapshot)功能,比较两个快照之间的差异可以发现潜在的内存泄露。
下面通过一个例子来简单介绍pytracemalloc的用法和接口,关于更详细用法和API,可以参考这份详尽的文档或者pytracemalloc的作者在pycon上的演讲ppt。
1 import tracemalloc 2 3 NUM_OF_ATTR = 10 4 NUM_OF_INSTANCE = 100 5 6 class Slots(object): 7 __slots__ = ['attr%s'%i for i in range(NUM_OF_ATTR)] 8 def __init__(self): 9 value_lst = (1.0, True, [], {}, ()) 10 for i in range(NUM_OF_ATTR): 11 setattr(self, 'attr%s'%i, value_lst[i % len(value_lst)]) 12 13 14 class NoSlots(object): 15 def __init__(self): 16 value_lst = (1.0, True, [], {}, ()) 17 for i in range(NUM_OF_ATTR): 18 setattr(self, 'attr%s'%i, value_lst[i % len(value_lst)]) 19 20 21 22 def generate_some_objs(): 23 lst = [] 24 for i in range(NUM_OF_INSTANCE): 25 o = Slots() if i % 2 else NoSlots() 26 lst.append(o) 27 return lst 28 29 30 if __name__ == '__main__': 31 tracemalloc.start(3) 32 33 t = generate_some_objs() 34 35 snapshot = tracemalloc.take_snapshot() 36 top_stats = snapshot.statistics('lineno') # lineno filename traceback 37 38 print(tracemalloc.get_traced_memory()) 39 for stat in top_stats[:10]: 40 print(stat)
在上面的代码中,用到了pytracemalloc几个核心的API:
start(nframe: int=1)
pytracemalloc的一大好处就是可以随时启停,start函数即开始追踪内存分配,相应的stop会停止追踪。start函数有一个参数,nframes : 内存分配时记录的栈的深度,这个值越大,pytracemalloc本身消耗的内存越多,在计算cumulative数据的时候有用。
get_traced_memory()
返回值是拥有两个元素的tuple,第一个元素是当前分配的内存,第二个元素是自内存追踪启动以来的内存峰值。
take_snapshot()
返回当前内存分配快照,返回值是Snapshot对象,该对象可以按照单个文件、单行、单个调用栈统计内存分配情况
运行环境:windows 64位python3.4
(62280, 62920)
test.py:10: size=16.8 KiB, count=144, average=120 Btest.py:17: size=16.7 KiB, count=142, average=120 Btest.py:19: size=9952 B, count=100, average=100 Btest.py:26: size=9792 B, count=102, average=96 Btest.py:27: size=848 B, count=1, average=848 Btest.py:34: size=456 B, count=1, average=456 Btest.py:36: size=448 B, count=1, average=448 BD:\Python3.4\lib\tracemalloc.py:474: size=64 B, count=1, average=64 B
如果将第36行的“lineno“改成“filename”,那么结果如下
(62136, 62764)
test.py:0: size=54.5 KiB, count=491, average=114 BD:\Python3.4\lib\tracemalloc.py:0: size=64 B, count=1, average=64 B
有了Profile结果之后,可以看出来在哪个文件中有大量的内存分配。与性能优化相同,造成瓶颈的有两种情况:单个对象占用了大量的内存;同时大量存在的小对象。对于前者,优化的手段并不多,惰性初始化属性可能有一些帮助;而对于后者,当同样类型的对象大量存在时,可以使用slots进行优化。
Slots
默认情况下,自定义的对象都使用dict来存储属性(通过obj.__dict__查看),而python中的dict大小一般比实际存储的元素个数要大(以此降低hash冲突概率),因此会浪费一定的空间。在新式类中使用__slots__,就是告诉Python虚拟机,这种类型的对象只会用到这些属性,因此虚拟机预留足够的空间就行了,如果声明了__slots__,那么对象就不会再有__dict__属性。
使用slots到底能带来多少内存优化呢,首先看看这篇文章,对于一个只有三个属性的Image类,使用__slots__之后内存从25.5G下降到16.2G,节省了9G的空间!

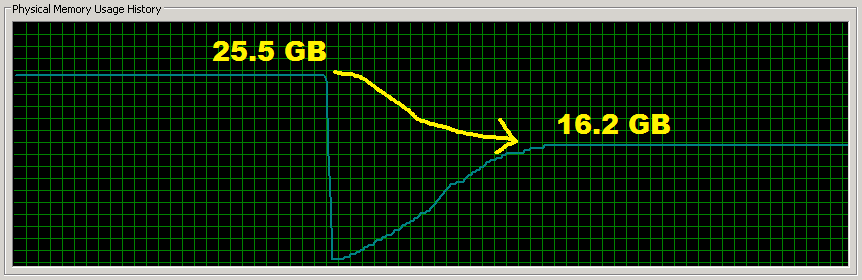
到底能省多少,取决于类自身有多少属性、属性的类型,以及同时存在多少个类的实例。下面通过一段简单代码测试一下:
1 # -*- coding: utf-8 -*- 2 import sys 3 import tracemalloc 4 5 NUM_OF_ATTR = 3 #3 # 10 # 30 #90 6 NUM_OF_INSTANCE = 10 # 10 # 100 7 8 class Slots(object): 9 __slots__ = ['attr%s'%i for i in range(NUM_OF_ATTR)] 10 def __init__(self): 11 value_lst = (1.0, True, [], {}, ()) 12 for i in range(NUM_OF_ATTR): 13 setattr(self, 'attr%s'%i, value_lst[i % len(value_lst)]) 14 15 16 class NoSlots(object): 17 def __init__(self): 18 value_lst = (1.0, True, [], {}, ()) 19 for i in range(NUM_OF_ATTR): 20 setattr(self, 'attr%s'%i, value_lst[i % len(value_lst)]) 21 22 if __name__ == '__main__': 23 clz = Slots if len(sys.argv) > 1 else NoSlots 24 tracemalloc.start() 25 objs = [clz() for i in range(NUM_OF_INSTANCE)] 26 print(tracemalloc.get_traced_memory()[0])
上面的代码,主要是在每个实例的属性数目、并发存在的实例数目两个维度进行测试,并没有测试不同的属性类型。结果如下表:

百分比为内存优化百分比,计算公式为(b - a) / b, 其中b为没有使用__slots__时分配的内存, a为使用了__slots__时分配的内存。
注意事项
关于__slots__,Python文档有非常详尽的介绍,这里只强调几点注意事项
第一:基类和子类都必须__slots__,即使基类或者子类没有属性
>>> class Base(object):
... pass...>>> class Derived(Base):... __slots__ = ('a', )...>>> d.__slots__('a',)>>> getattr(d, '__dict__', 'No Dict'){}
从上面的示例可以看到,子类的对象还是有__dict__属性,原因就在于基类没有声明__slots__。因此,可以通过看子类的实例有没有__dict__属性来判断slots的使用是否正确
第二:子类会继承基类的__slots__
>>> class Base(object):
... __slots__ = ('a',)...>>> class Derived(Base):... __slots__ = ('b', )...>>> d = Derived()>>> d.__slots__('b',)>>> getattr(d, '__dict__', 'No Dict')'No Dict'>>> d.a = 1>>> d.c = 0Traceback (most recent call last):File "", line 1, in AttributeError: 'Derived' object has no attribute 'c'
objgraph
import objgraph
objgraph.show_most_common_types(25)
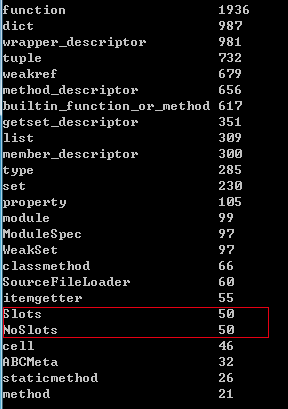
再论Python dict
前面介绍slots的时候,就提到Python自定义的对象中通过dict来管理属性。这种机制极大的提高了Python的灵活性 -- 可以随时给对象增加属性,但是其实现机制也带来了内存上的浪费。不管是python源码,还是Python程序,都大量使用了dict,因此这部分内存浪费不容小视。
python中的dict使用的是散列表(类似C++中的std::unordered_map),当计算出的hash值冲突的时候,采用开放地址法解决冲突(另一种常见的冲突解决算法是链表法)。为了降低冲突概率,当装填因子(实际存储的元素与散列表长度的比值)超过2/3的时候就会对散列表进行扩容,因此散列表中一定会存在一些未使用的槽。
下面简单看看PyDictObject的数据结构(python2.7.3 dictobject.h)
1 #define PyDict_MINSIZE 8 2 3 typedef struct { 4 /* Cached hash code of me_key. Note that hash codes are C longs. 5 * We have to use Py_ssize_t instead because dict_popitem() abuses 6 * me_hash to hold a search finger. 7 */ 8 Py_ssize_t me_hash; 9 PyObject *me_key; 10 PyObject *me_value; 11 } PyDictEntry; 12 13 14 typedef struct _dictobject PyDictObject; 15 struct _dictobject { 16 PyObject_HEAD 17 Py_ssize_t ma_fill; /* # Active + # Dummy */ 18 Py_ssize_t ma_used; /* # Active */ 19 20 /* The table contains ma_mask + 1 slots, and that's a power of 2. 21 * We store the mask instead of the size because the mask is more 22 * frequently needed. 23 */ 24 Py_ssize_t ma_mask; 25 26 /* ma_table points to ma_smalltable for small tables, else to 27 * additional malloc'ed memory. ma_table is never NULL! This rule 28 * saves repeated runtime null-tests in the workhorse getitem and 29 * setitem calls. 30 */ 31 PyDictEntry *ma_table; 32 PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash); 33 PyDictEntry ma_smalltable[PyDict_MINSIZE]; 34 };
从定义可以看出,除了固定的部分(几个Py_ssize_t),PyDictObject中主要是PyDictEntry对象,PyDictEntrty包含一个Py_ssize_t(int)和两个指针。上面源码中的注释(第26行)指出,当dict的元素比较少时,ma_table指向ma_smalltable,当元素增多时,ma_table会指向新申请的空间。ma_smalltable的作用在于Python(不管是源码还是代码)都大量使用dict,一般来说,存储的元素也不会太多,因此Python就先开辟好PyDict_MINSIZE(默认为8)个空间。
为什么说PyDictObject存在浪费呢,PyDictEntry在32位下也有12个字节,那么即使在ma_smalltable(ma_table)中大量的位置没有被使用时,也要占用这么多字节。用这篇文章中的例子:
假设有这么一个dict: d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
在Python源码中的视图就是这样的:
# 下面的entries就是ma_smalltable
entries = [['--', '--', '--'], [-8522787127447073495, 'barry', 'green'], ['--', '--', '--'], ['--', '--', '--'], ['--', '--', '--'], [-9092791511155847987, 'timmy', 'red'], ['--', '--', '--'], [-6480567542315338377, 'guido', 'blue']]
然而,完全可以这么存储:
indices = [None, 1, None, None, None, 0, None, 2]
entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
indices的作用类似ma_smalltable,但只存储一个数组的索引值,数组只存储实际存在的元素(PyDictEntry),当dict中的元素越稀疏,相比上一种存储方式使用的内存越少。而且,这种实现, dict就是有序的(按插入时间排序)
这就是python3.6中新的dict实现,Compact dict! Stackoverflow上也有相关讨论。
总结
本文中介绍了Python内存优化的Profile工具,最有效的优化方法:使用slots,也介绍了在python3.6中新的dict实现。
当然,还有一些良好的编码习惯。比如尽量使用immutable而不是mutable对象:使用tuple而不是list,使用frozenset而不是set;另外,就是尽量使用迭代器,比如python2.7中,使用xrange而不是range,dict的iterxx版本。
references
pytracemalloc
pep454: Add a new tracemalloc module to trace Python memory allocations
save-ram-with-python-slots/
Python源码分析-PyDictObject
More compact dictionaries with faster iteration