4.4.存储文件组织与内存映射
RocketMQ 通过使用内存映射文件来提高IO 访问性能,无论是CommitLog 、ConsumeQueue 还是IndexFile ,单个文件都被设计为固定长度,如果一个文件写满以后再创建一个新文件,文件名就为该文件第一条消息对应的全局物理偏移量。例如CommitLog文件的组织方式如图4-6 所示。

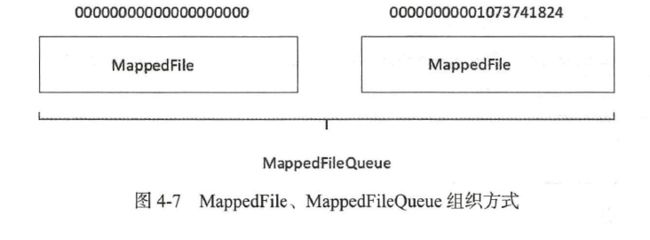
RocketMQ 使用MappedFile 、MappedFileQueue 来封装存储文件,其关系如图4-7 所示。
4.4.1.MappedFileQueue 映射文件队列
MappedFileQueu巳是MappedFile 的管理容器, MappedFileQueue 是对存储目录的封装,例如CommitLog 文件的存储路径{ ROCKET_HOME} /store/commitlog/ ,该目录下会存在多个内存映射文件(MappedFile) 。MappedFileQueue 类图如图4-8 所示。

下面让我们一一来介绍MappedFileQueue 的核心属性。
- String storePath :存储目录。
- int mappedFileSize : 单个文件的存储大小。
- CopyOnWriteArrayList
mappedFiles: MappedFile 文件集合。 - AllocateMappedFileService allocateMappedFileService :创建MappedFile 服务类。
- long flushedWhere = 0 : 当前刷盘指针, 表示该指针之前的所有数据全部持久化到磁盘。
- long committedWhere = 0 : 当前数据提交指针,内存中ByteBuffer 当前的写指针,该值大于等于flushedWhere 。
接下来重点分析一下根据不同查询维度查找MappedFile 。
public MappedFile getMappedFileByTime(final long timestamp) {
Object[] mfs = this.copyMappedFiles(0);
if (null == mfs)
return null;
for (int i = 0; i < mfs.length; i++) {
MappedFile mappedFile = (MappedFile) mfs[i];
if (mappedFile.getLastModifiedTimestamp() >= timestamp) {
return mappedFile;
}
}
return (MappedFile) mfs[mfs.length - 1];
}
根据消息存储时间戳来查找MappdFile 。从MappedFile 列表中第一个文件开始查找,找到第一个最后一次更新时间大于待查找时间戳的文件,如果不存在,则返回最后一个MappedFile 文件。
public MappedFile findMappedFileByOffset(final long offset, final boolean returnFirstOnNotFound) {
try {
MappedFile firstMappedFile = this.getFirstMappedFile();
MappedFile lastMappedFile = this.getLastMappedFile();
if (firstMappedFile != null && lastMappedFile != null) {
if (offset < firstMappedFile.getFileFromOffset() || offset >= lastMappedFile.getFileFromOffset() + this.mappedFileSize) {
LOG_ERROR.warn("Offset not matched. Request offset: {}, firstOffset: {}, lastOffset: {}, mappedFileSize: {}, mappedFiles count: {}",
offset,
firstMappedFile.getFileFromOffset(),
lastMappedFile.getFileFromOffset() + this.mappedFileSize,
this.mappedFileSize,
this.mappedFiles.size());
} else {
int index = (int) ((offset / this.mappedFileSize) - (firstMappedFile.getFileFromOffset() / this.mappedFileSize));
MappedFile targetFile = null;
try {
targetFile = this.mappedFiles.get(index);
} catch (Exception ignored) {
}
if (targetFile != null && offset >= targetFile.getFileFromOffset()
&& offset < targetFile.getFileFromOffset() + this.mappedFileSize) {
return targetFile;
}
for (MappedFile tmpMappedFile : this.mappedFiles) {
if (offset >= tmpMappedFile.getFileFromOffset()
&& offset < tmpMappedFile.getFileFromOffset() + this.mappedFileSize) {
return tmpMappedFile;
}
}
}
if (returnFirstOnNotFound) {
return firstMappedFile;
}
}
} catch (Exception e) {
log.error("findMappedFileByOffset Exception", e);
}
return null;
}
根据消息偏移量offset 查找MappedFile 。根据offet 查找MappedFile 直接使用offset%mappedFileSize是否可行?答案是否定的,由于使用了内存映射,只要存在于存储目录下的文件,都需要对应创建内存映射文件,如果不定时将已消费的消息从存储文件中删除,会造成极大的内存压力与资源浪费,所有RocketMQ 采取定时删除存储文件的策略,也就是说在存储文件中, 第一个文件不一定是00000000000000000000 ,因为该文件在某一时刻会被删除,故根据offset 定位MappedFile 的算法为( int) ((offset I this.mappedFileSize) -(mappedFile.getFileFromOffset() I this . MappedFileSize )) 。
public long getMinOffset() {
if (!this.mappedFiles.isEmpty()) {
try {
return this.mappedFiles.get(0).getFileFromOffset();
} catch (IndexOutOfBoundsException e) {
//continue;
} catch (Exception e) {
log.error("getMinOffset has exception.", e);
}
}
return -1;
}
获取存储文件最小偏移量,从这里也可以看出,并不是直接返回0 ,而是返回MappedFile的getFileFormOffset() 。
public long getMaxOffset() {
MappedFile mappedFile = getLastMappedFile();
if (mappedFile != null) {
return mappedFile.getFileFromOffset() + mappedFile.getReadPosition();
}
return 0;
}
获取存储文件的最大偏移量。返回最后一个Mapp巳dFile 文件的fileFromOffset 加上MappedFile 文件当前的写指针。
public long getMaxWrotePosition() {
MappedFile mappedFile = getLastMappedFile();
if (mappedFile != null) {
return mappedFile.getFileFromOffset() + mappedFile.getWrotePosition();
}
return 0;
}
返回存储文件当前的写指针。返回最后一个文件的fil eF rom Offset 加上当前写指针位置。MappedFileQueue 的相关业务方法在具体使用到时再去剖析。
4.4.2.MappedFile内存映射文件
MappedFile 是RocketMQ 内存映射文件的具体实现,如图4 -9 所示。

下面让我们一一来介绍MappedFile 的核心属性。
- int OS_PAGE_SIZE :操作系统每页大小,默认4k 。
- AtomicLong TOTAL_MAPPED_VIRTUAL_MEMORY : 当前JVM 实例中MappedFile虚拟内存。
- Atomiclnteger TOTAL_MAPPED_FILES :当前JVM 实例中MappedFile 对象个数。
- Atomiclnteger wrotePosition : 当前该文件的写指针,从0 开始(内存映射文件中的写指针) 。
- Atomiclnteger committedPosition :当前文件的提交指针,如果开启transientStore PoolEnable, 则数据会存储在TransientStorePool 中, 然后提交到内存映射ByteBuffer 中, 再刷写到磁盘。
- Atomiclnteger flushedPosition :刷写到磁盘指针,该指针之前的数据持久化到磁盘中。
- int fileSize :文件大小。
- FileChannel fileChannel : 文件通道。
- ByteBuffer writeBuffer :堆内存ByteBuffer , 如果不为空,数据首先将存储在该Buffer 中, 然后提交到MappedFile 对应的内存映射文件Buffer 。transientStorePoolEnable为true 时不为空。
- TransientStorePool transientStorePool :堆内存池, transientStorePoolEnable 为true时启用。
- String fileName :文件名称。
- long fileFromOffset :该文件的初始偏移量。
- File file :物理文件。
- MappedByteBuffer mappedByteBuffer :物理文件对应的内存映射Buffer 。
- volatile long storeTimestamp = 0 :文件最后一次内容写入时间。
- boolean firstCreatelnQueue :是否是MappedFileQueue 队列中第一个文件。
MappedFile 初始化
根据是否开启transientStorePoolEnable 存在两种初始化情况。transientStorePoolEnable为true 表示内容先存储在堆外内存,然后通过Commit 线程将数据提交到内存映射Buffer中,再通过Flush 线程将内存映射Buffer 中的数据持久化到磁盘中。
private void init(final String fileName, final int fileSize) throws IOException {
this.fileName = fileName;
this.fileSize = fileSize;
this.file = new File(fileName);
this.fileFromOffset = Long.parseLong(this.file.getName());
boolean ok = false;
ensureDirOK(this.file.getParent());
try {
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
TOTAL_MAPPED_FILES.incrementAndGet();
ok = true;
} catch (FileNotFoundException e) {
log.error("create file channel " + this.fileName + " Failed. ", e);
throw e;
} catch (IOException e) {
log.error("map file " + this.fileName + " Failed. ", e);
throw e;
} finally {
if (!ok && this.fileChannel != null) {
this.fileChannel.close();
}
}
}
初始化fileFromOffset 为文件名,也就是文件名代表该文件的起始偏移量,通过RandomAccessFile 创建读写文件通道,并将文件内容使用NIO 的内存映射Buffer 将文件映射到内存中。
public void init(final String fileName, final int fileSize,
final TransientStorePool transientStorePool) throws IOException {
init(fileName, fileSize);
this.writeBuffer = transientStorePool.borrowBuffer();
this.transientStorePool = transientStorePool;
}
如果transientStorePoolEnable为true ,则初始化MappedFile 的writeBuffer , 该buffer从transientStorePool ,下一节重点分析一下TransientStorePool 。
MappedFile 提交(commit)
内存映射文件的提交动作由MappedFile 的commit 方法实现,如代码清单4-18 所示。
public int commit(final int commitLeastPages) {
if (writeBuffer == null) {
//no need to commit data to file channel, so just regard wrotePosition as committedPosition.
return this.wrotePosition.get();
}
if (this.isAbleToCommit(commitLeastPages)) {
if (this.hold()) {
commit0(commitLeastPages);
this.release();
} else {
log.warn("in commit, hold failed, commit offset = " + this.committedPosition.get());
}
}
// All dirty data has been committed to FileChannel.
if (writeBuffer != null && this.transientStorePool != null && this.fileSize == this.committedPosition.get()) {
this.transientStorePool.returnBuffer(writeBuffer);
this.writeBuffer = null;
}
return this.committedPosition.get();
}
执行提交操作, commitLeastPages 为本次提交最小的页数,如果待提交数据不满commitLeastPages ,则不执行本次提交操作,待下次提交。writeBuffer 如果为空,直接返回wrotePosition 指针,无须执行commit操作, 表明commit 操作主体是writeBuffer。
protected boolean isAbleToCommit(final int commitLeastPages) {
int flush = this.committedPosition.get();
int write = this.wrotePosition.get();
if (this.isFull()) {
return true;
}
if (commitLeastPages > 0) {
return ((write / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE)) >= commitLeastPages;
}
return write > flush;
}
判断是否执行commit 操作。如果文件己满返回true ;如果commitLeastPages 大于0,则比较wrotePosition ( 当前writeBuffe 的写指针)与上一次提交的指针(committedPosition)的差值,除以OS_PAGE_SIZE 得到当前脏页的数量,如果大于commitLeastPages 则返回 true ;如果commitLeastPages 小于0 表示只要存在脏页就提交。
protected void commit0(final int commitLeastPages) {
int writePos = this.wrotePosition.get();
int lastCommittedPosition = this.committedPosition.get();
if (writePos - this.committedPosition.get() > 0) {
try {
ByteBuffer byteBuffer = writeBuffer.slice();
byteBuffer.position(lastCommittedPosition);
byteBuffer.limit(writePos);
this.fileChannel.position(lastCommittedPosition);
this.fileChannel.write(byteBuffer);
this.committedPosition.set(writePos);
} catch (Throwable e) {
log.error("Error occurred when commit data to FileChannel.", e);
}
}
}
具体的提交实现。首先创建writeBuffer 的共享缓存区,然后将新创建的position 回退到上一次提交的位置( committedPosition ) , 设置limit 为wrotePosition (当前最大有效数据指针),然后把commitedPosition 到wrotePosition 的数据复制(写入)到FileChannel中, 然后更新committedPosition 指针为wrotePosition.commit 的作用就是将MappedFile#writeBuffer中的数据提交到文件通道FileChannel 中。
ByteBuffer 使用技巧: slice () 方法创建一个共享缓存区, 与原先的ByteBuffer 共享内存但维护一套独立的指针( position 、mark 、limit) 。
MappedFile刷盘(flush)
刷盘指的是将内存中的数据刷写到磁盘,永久存储在磁盘中,其具体实现由MappedFile 的flush 方法实现,如代码清单4-21 所示。
public int flush(final int flushLeastPages) {
if (this.isAbleToFlush(flushLeastPages)) {
if (this.hold()) {
int value = getReadPosition();
try {
//We only append data to fileChannel or mappedByteBuffer, never both.
if (writeBuffer != null || this.fileChannel.position() != 0) {
this.fileChannel.force(false);
} else {
this.mappedByteBuffer.force();
}
} catch (Throwable e) {
log.error("Error occurred when force data to disk.", e);
}
this.flushedPosition.set(value);
this.release();
} else {
log.warn("in flush, hold failed, flush offset = " + this.flushedPosition.get());
this.flushedPosition.set(getReadPosition());
}
}
return this.getFlushedPosition();
}
刷写磁盘,直接调用mappedByteBuffer 或fileChannel 的force 方法将内存中的数据持久化到磁盘,那么flushedPosition 应该等于MappedByteBuffer 中的写指针;如果writeBuffer不为空, 则flushedPosition 应等于上一次commit 指针;因为上一次提交的数据就是进入到MappedByteBuffer 中的数据;如果writeBuffer 为空,数据是直接进入到MappedByteBuffer,wrotePosition 代表的是MappedByteBuffer 中的指针,故设置flushedPosition 为wrotePosition 。
获取MappedFile 最大读指针(getReadPosition)
RocketMQ 文件的一个组织方式是内存映射文件,预先申请一块连续的固定大小的内存, 需要一套指针标识当前最大有效数据的位置,获取最大有效数据偏移量的方法由MappedFile 的getReadPosition 方法实现,如代码清单4-22 所示。
public int getReadPosition() {
return this.writeBuffer == null ? this.wrotePosition.get() : this.committedPosition.get();
}
获取当前文件最大的可读指针。如果writeBuffer 为空, 则直接返回当前的写指针;如果writeBuffer 不为空, 则返回上一次提交的指针。在MappedFile 设计中,只有提交了的数据(写入到MappedByteBuffer 或FileChannel 中的数据)才是安全的数据。
public SelectMappedBufferResult selectMappedBuffer(int pos, int size) {
int readPosition = getReadPosition();
if ((pos + size) <= readPosition) {
if (this.hold()) {
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
byteBuffer.position(pos);
ByteBuffer byteBufferNew = byteBuffer.slice();
byteBufferNew.limit(size);
return new SelectMappedBufferResult(this.fileFromOffset + pos, byteBufferNew, size, this);
} else {
log.warn("matched, but hold failed, request pos: " + pos + ", fileFromOffset: "
+ this.fileFromOffset);
}
} else {
log.warn("selectMappedBuffer request pos invalid, request pos: " + pos + ", size: " + size
+ ", fileFromOffset: " + this.fileFromOffset);
}
return null;
}
public SelectMappedBufferResult selectMappedBuffer(int pos) {
int readPosition = getReadPosition();
if (pos < readPosition && pos >= 0) {
if (this.hold()) {
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
byteBuffer.position(pos);
int size = readPosition - pos;
ByteBuffer byteBufferNew = byteBuffer.slice();
byteBufferNew.limit(size);
return new SelectMappedBufferResult(this.fileFromOffset + pos, byteBufferNew, size, this);
}
}
return null;
}
查找pos 到当前最大可读之间的数据,由于在整个写入期间都未曾改变MappedByteBuffer的指针,所以mappedByteBuffer.slice()方法返回的共享缓存区空间为整个MappedFile,然后通过设置byteBuffer 的position 为待查找的值,读取字节为当前可读字节长度,最终返回的ByteBuffer 的limit ( 可读最大长度)为size 。整个共享缓存区的容量为( MappedFile#fileSize -pos ) ,故在操作SelectMappedBufferResult 不能对包含在里面的
ByteBuffer 调用flip 方法。
操作ByteBuffer 时如果使用了slice () 方法,对其ByteBuffer 进行读取时一般手动指定position 与limit 指针,而不是调用flip 方法来切换读写状态。
MappedFile 销毁( destory)
MappedFile 文件销毁的实现方法为public boolean destroy(final long intervalForcibly),intervalForcibly 表示拒绝被销毁的最大存活时间。
public boolean destroy(final long intervalForcibly) {
this.shutdown(intervalForcibly);
if (this.isCleanupOver()) {
try {
this.fileChannel.close();
log.info("close file channel " + this.fileName + " OK");
long beginTime = System.currentTimeMillis();
boolean result = this.file.delete();
log.info("delete file[REF:" + this.getRefCount() + "] " + this.fileName
+ (result ? " OK, " : " Failed, ") + "W:" + this.getWrotePosition() + " M:"
+ this.getFlushedPosition() + ", "
+ UtilAll.computeEclipseTimeMilliseconds(beginTime));
} catch (Exception e) {
log.warn("close file channel " + this.fileName + " Failed. ", e);
}
return true;
} else {
log.warn("destroy mapped file[REF:" + this.getRefCount() + "] " + this.fileName
+ " Failed. cleanupOver: " + this.cleanupOver);
}
return false;
}
public void shutdown(final long intervalForcibly) {
if (this.available) {
this.available = false;
this.firstShutdownTimestamp = System.currentTimeMillis();
this.release();
} else if (this.getRefCount() > 0) {
if ((System.currentTimeMillis() - this.firstShutdownTimestamp) >= intervalForcibly) {
this.refCount.set(-1000 - this.getRefCount());
this.release();
}
}
}
Step1:关闭MappedFile 。初次调用时this.available 为true ,设置available 为false ,并设置初次关闭的时间戳( firstShutdownTimestamp )为当前时间戳, 然后调用release() 方法尝试释放资源, release 只有在引用次数小于1 的情况下才会释放资源;如果引用次数大于0 ,对比当前时间与firstShutdownTimestamp ,如果已经超过了其最大拒绝存活期,每执行一次,将引用数减少1000 ,直到引用数小于0 时通过执行realse 方法释放资源。
public boolean isCleanupOver() {
return this.refCount.get() <= 0 && this.cleanupOver;
}
Step2 : 判断是否清理完成,判断标准是引用次数小于等于0 并且cleanupOver 为true,cleanupOver 为true 的触发条件是release 成功将MappedByteBuffer 资源释放。稍后详细分析release 方法。
this.fileChannel.close();
log.info("close file channel " + this.fileName + " OK");
long beginTime = System.currentTimeMillis();
boolean result = this.file.delete();
Step3 : 关闭文件通道, 删除物理文件。
在整个MappedFile 销毁过程,首先需要释放资源,释放资源的前提条件是该MappedFile的引用小于等于0 ,接下来重点看一下release 方法的实现原理。
public void release() {
long value = this.refCount.decrementAndGet();
if (value > 0)
return;
synchronized (this) {
this.cleanupOver = this.cleanup(value);
}
}
将引用次数减1,如果引用数小于等于0 ,则执行cleanup 方法,接下来重点分析一下cleanup 方法的实现。
@Override
public boolean cleanup(final long currentRef) {
if (this.isAvailable()) {
log.error("this file[REF:" + currentRef + "] " + this.fileName
+ " have not shutdown, stop unmapping.");
return false;
}
if (this.isCleanupOver()) {
log.error("this file[REF:" + currentRef + "] " + this.fileName
+ " have cleanup, do not do it again.");
return true;
}
clean(this.mappedByteBuffer);
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(this.fileSize * (-1));
TOTAL_MAPPED_FILES.decrementAndGet();
log.info("unmap file[REF:" + currentRef + "] " + this.fileName + " OK");
return true;
}
如果available 为true ,表示MappedFile 当前可用,无须清理,返回false ;如果资源已经被清除,返回true ;如果是堆外内存,调用堆外内存的cleanup 方法清除,维护MappedFile 类变量TOTAL_MAPPED_VIRTUAL_MEMORY 、TOTAL_MAPPED_FILES 并返回true,表示cleanupOver 为true 。
4.4.3.TransientStorePool
TransientStorePool : 短暂的存储池。RocketMQ 单独创建一个MappedByteBuffer 内存缓存池,用来临时存储数据,数据先写人该内存映射中,然后由commit 线程定时将数据从该内存复制到与目的物理文件对应的内存映射中。RokcetMQ 引人该机制主要的原因是仅供提供一种内存锁定,将当前堆外内存一直锁定在内存中,避免被进程将内存交换到磁盘。
TransientStorePool 类图如图4-10 所示。

下面让我们一一介绍Trans i entStorePool 的核心属性。
- int poolSize: avaliableBuffers 个数,可通过在broker 中配置文件中设置transientStorePoolSize, 默认为5 。
- int fileSize: 每个ByteBuffer 大小, 默认为mapedFileSizeCommitLog ,表明TransientStorePool 为commitlog 文件服务。
- Deque< ByteBuffer> availableBuffers: ByteBuffer 容器,双端队列。
public void init() {
for (int i = 0; i < poolSize; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(fileSize);
final long address = ((DirectBuffer) byteBuffer).address();
Pointer pointer = new Pointer(address);
LibC.INSTANCE.mlock(pointer, new NativeLong(fileSize));
availableBuffers.offer(byteBuffer);
}
}
创建poolSize 个堆外内存, 并利用com.sun.jna.Library 类库将该批内存锁定,避免被置换到交换区,提高存储性能。
4.5.RocketMQ存储文件
RocketMQ 存储路径为${ROCKET_HOME}/store ,主要存储文件如图4-11 所示。下面让我们一一介绍一下RocketMQ 主要的存储文件夹。
- commitlog :消息存储目录。
- config :运行期间一些配置信息,主要包括下列信息。
- consumerFilter.json : 主题消息过滤信息。
- consumerOffset.json : 集群消费模式消息消费进度。
- delayOffset.json :延时消息队列拉取进度。
- subscriptionGroup.json : 消息消费组配置信息。
- topics.json: topic 配置属性。
- consumequeue :消息消费队列存储目录。
- index :消息索引文件存储目录。
- abort :如果存在abort 文件说明Broker 非正常关闭,该文件默认启动时创建,正常退出之前删除。
- checkpoint :文件检测点,存储commitlog 文件最后一次刷盘时间戳、consumequeue最后一次刷盘时间、index 索引文件最后一次刷盘时间戳。
4.5.1.Commitlog 文件
commitlog 目录的组织方式在4.4 节中已经详细介绍过了,该目录下的文件主要存储消息,其特点是每一条消息长度不相同,消息存储协议已在4.3 节中详细描述, Commitlog 文件存储的逻辑视图如图4-12 所示,每条消息的前面4 个字节存储该条消息的总长度。

Commitlog 文件的存储目录默认为${ ROCKET_HOME } /store/commitlog ,可以通过在broker 配置文件中设置storePathRootDir 属性来改变默认路径。commitlog 文件默认大小为1G ,可通过在broker 配置文件中设置mapedFileSizeCommitLog 属性来改变默认大小。本节将基于上述存储结构重点分析消息的查找实现,其他诸如文件刷盘、文件恢复机制等将在下文中详细介绍。
public long getMinOffset() {
MappedFile mappedFile = this.mappedFileQueue.getFirstMappedFile();
if (mappedFile != null) {
if (mappedFile.isAvailable()) {
return mappedFile.getFileFromOffset();
} else {
return this.rollNextFile(mappedFile.getFileFromOffset());
}
}
return -1;
}
获取当前Commitlog 目录最小偏移量,首先获取目录下的第一个文件,如果该文件可用, 则返回该文件的起始偏移量,否则返回下一个文件的起始偏移量。
public long rollNextFile(final long offset) {
int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMapedFileSizeCommitLog();
return offset + mappedFileSize - offset % mappedFileSize;
}
根据该offset 返回下一个文件的起始偏移量。首先获取一个文件的大小, 减去(offset%mappedFileSize)其目的是回到下一文件的起始偏移量。
public SelectMappedBufferResult getMessage(final long offset, final int size) {
int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMapedFileSizeCommitLog();
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset, offset == 0);
if (mappedFile != null) {
int pos = (int) (offset % mappedFileSize);
return mappedFile.selectMappedBuffer(pos, size);
}
return null;
}
根据偏移量与消息长度查找消息。首先根据偏移找到所在的物理偏移量,然后用offset与文件长度取余得到在文件内的偏移量,从该偏移量读取size 长度的内容返回即可。如果只根据消息偏移查找消息, 则首先找到文件内的偏移量,然后尝试读取4个字节获取消息的实际长度, 最后读取指定字节即可。
4.5.2.ConsumeQueue文件
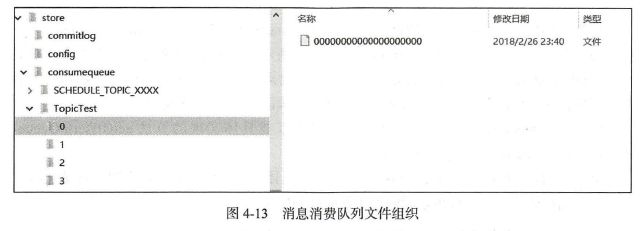
RocketMQ 基于主题订阅模式实现消息消费,消费者关心的是一个主题下的所有消息,但由于同一主题的消息不连续地存储在commitlog 文件中,试想一下如果消息消费者直接从消息存储文件(commitlog)中去遍历查找订阅主题下的消息,效率将极其低下,RocketMQ 为了适应消息消费的检索需求,设计了消息消费队列文件(Consumequeue),该文件可以看成是Commitlog 关于消息消费的“索引”文件, consumequeue 的第一级目录为消息主题,第二级目录为主题的消息队列,如图4-13 所示。
为了加速ConsumeQueue 消息条目的检索速度与节省磁盘空间,每一个Consumequeue条目不会存储消息的全量信息,其存储格式如图4-14 所示。
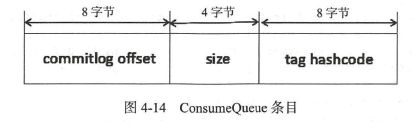
单个ConsumeQueue 文件中默认包含30 万个条目,单个文件的长度为30w × 20 字节,单个ConsumeQueue 文件可以看出是一个ConsumeQueue 条目的数组,其下标为ConsumeQueue的逻辑偏移量,消息消费进度存储的偏移量即逻辑偏移量。ConsumeQueue 即为Commitlog 文件的索引文件, 其构建机制是当消息到达Commitlog 文件后, 由专门的线程产生消息转发任务,从而构建消息消费队列文件与下文提到的索引文件。
本节只分析如何根据消息逻辑偏移量、时间戳查找消息的实现,下一节将重点讨论消息消费队列的构建、恢复等。
public SelectMappedBufferResult getIndexBuffer(final long startIndex) {
int mappedFileSize = this.mappedFileSize;
long offset = startIndex * CQ_STORE_UNIT_SIZE;
if (offset >= this.getMinLogicOffset()) {
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset);
if (mappedFile != null) {
SelectMappedBufferResult result = mappedFile.selectMappedBuffer((int) (offset % mappedFileSize));
return result;
}
}
return null;
}
根据startIndex 获取消息消费队列条目。首先startIndex*20 得到在consumequeue 中的物理偏移量,如果该offset 小于minLogicOffset ,则返回null ,说明该消息已被删除;如果大于minLogicOffset ,则根据偏移量定位到具体的物理文件,然后通过offset 与物理文大小取模获取在该文件的偏移量,从而从偏移量开始连续读取20个字节即可。
ConsumeQueue 提供了根据消息存储时间来查找具体实现的算法getOffsetInQueueByTime(final long timestamp) , 其具体实现如下。
public long getOffsetInQueueByTime(final long timestamp) {
MappedFile mappedFile = this.mappedFileQueue.getMappedFileByTime(timestamp);
if (mappedFile != null) {
long offset = 0;
int low = minLogicOffset > mappedFile.getFileFromOffset() ? (int) (minLogicOffset - mappedFile.getFileFromOffset()) : 0;
int high = 0;
int midOffset = -1, targetOffset = -1, leftOffset = -1, rightOffset = -1;
long leftIndexValue = -1L, rightIndexValue = -1L;
long minPhysicOffset = this.defaultMessageStore.getMinPhyOffset();
SelectMappedBufferResult sbr = mappedFile.selectMappedBuffer(0);
if (null != sbr) {
ByteBuffer byteBuffer = sbr.getByteBuffer();
high = byteBuffer.limit() - CQ_STORE_UNIT_SIZE;
try {
while (high >= low) {
midOffset = (low + high) / (2 * CQ_STORE_UNIT_SIZE) * CQ_STORE_UNIT_SIZE;
byteBuffer.position(midOffset);
long phyOffset = byteBuffer.getLong();
int size = byteBuffer.getInt();
if (phyOffset < minPhysicOffset) {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
continue;
}
long storeTime =
this.defaultMessageStore.getCommitLog().pickupStoreTimestamp(phyOffset, size);
if (storeTime < 0) {
return 0;
} else if (storeTime == timestamp) {
targetOffset = midOffset;
break;
} else if (storeTime > timestamp) {
high = midOffset - CQ_STORE_UNIT_SIZE;
rightOffset = midOffset;
rightIndexValue = storeTime;
} else {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
leftIndexValue = storeTime;
}
}
if (targetOffset != -1) {
offset = targetOffset;
} else {
if (leftIndexValue == -1) {
offset = rightOffset;
} else if (rightIndexValue == -1) {
offset = leftOffset;
} else {
offset =
Math.abs(timestamp - leftIndexValue) > Math.abs(timestamp
- rightIndexValue) ? rightOffset : leftOffset;
}
}
return (mappedFile.getFileFromOffset() + offset) / CQ_STORE_UNIT_SIZE;
} finally {
sbr.release();
}
}
}
return 0;
}
Step1 :首先根据时间戳定位到物理文件,其具体实现在前面有详细介绍,就是从第一个文件开始找到第一个文件更新时间大于该时间戳的文件。
int high = 0;
int midOffset = -1, targetOffset = -1, leftOffset = -1, rightOffset = -1;
long leftIndexValue = -1L, rightIndexValue = -1L;
long minPhysicOffset = this.defaultMessageStore.getMinPhyOffset();
SelectMappedBufferResult sbr = mappedFile.selectMappedBuffer(0);
if (null != sbr) {
ByteBuffer byteBuffer = sbr.getByteBuffer();
high = byteBuffer.limit() - CQ_STORE_UNIT_SIZE;
Step2 : 采用二分查找来加速检索。首先计算最低查找偏移量,取消息队列最小偏移量与该文件最小偏移量二者中的最小偏移量为low 。获取当前存储文件中有效的最小消息物理偏移量minPhysicOffset ,如果查找到消息偏移量小于该物理偏移量, 则结束该查找过程。
while (high >= low) {
midOffset = (low + high) / (2 * CQ_STORE_UNIT_SIZE) * CQ_STORE_UNIT_SIZE;
byteBuffer.position(midOffset);
long phyOffset = byteBuffer.getLong();
int size = byteBuffer.getInt();
if (phyOffset < minPhysicOffset) {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
continue;
}
long storeTime =
this.defaultMessageStore.getCommitLog().pickupStoreTimestamp(phyOffset, size);
if (storeTime < 0) {
return 0;
} else if (storeTime == timestamp) {
targetOffset = midOffset;
break;
} else if (storeTime > timestamp) {
high = midOffset - CQ_STORE_UNIT_SIZE;
rightOffset = midOffset;
rightIndexValue = storeTime;
} else {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
leftIndexValue = storeTime;
}
}
二分查找的常规退出循环为( low>high ), 首先查找中间的偏移量midOffset ,将整个Consume Queue 文件对应的ByteBuffer 定位到midOffset ,然后读取4 个字节获取该消息的物理偏移量offset 。
- 如果得到的物理偏移量小于当前的最小物理偏移量,说明待查找的物理偏移量肯定大于midOffset,所以将low 设置为midOffset ,然后继续折半查找。
- 如果offset 大于最小物理偏移量,说明该消息是有效消息,则根据消息偏移量和消息长度获取消息的存储时间戳。
- 如果存储时间小于0 ,消息为无效消息,直接返回0 。
- 如果存储时间戳等于待查找时间戳,说明查找到匹配消息,设置targetOffset 并跳出循环。
- 如果存储时间戳大于待查找时间戳,说明待查找信息小于mi dOffset ,则设置high为midOffset , 并设置rightIndexValue 等于midOffset 。
- 如果存储时间小于待查找时间戳,说明待查找消息在大于midOffset ,则设置low为midOffset ,并设置leftIndexValue巳等于midOffset。
if (targetOffset != -1) {
offset = targetOffset;
} else {
if (leftIndexValue == -1) {
offset = rightOffset;
} else if (rightIndexValue == -1) {
offset = leftOffset;
} else {
offset =
Math.abs(timestamp - leftIndexValue) > Math.abs(timestamp
- rightIndexValue) ? rightOffset : leftOffset;
}
}
Step3 : 如果targetOffset 不等于-1 表示找到了存储时间戳等于待查找时间戳的消息;如果leftIndexValue等于-1 , 表示返回当前时间戳大并且最接近待查找的偏移量;如果rightIndexValue 等于-1 , 表示返回的消息比待查找时间戳小并且最接近查找的偏移量。
public long rollNextFile(final long index) {
int mappedFileSize = this.mappedFileSize;
int totalUnitsInFile = mappedFileSize / CQ_STORE_UNIT_SIZE;
return index + totalUnitsInFile - index % totalUnitsInFile;
}
根据当前偏移量获取下一个文件的起始偏移量。首先获取一个文件包含多少个消息消费队列条目,减去index%totalUnitslnF ile 的目的是选中下一个文件的起始偏移量。