数据头User-Agent反爬虫机制解析:
当我们使用浏览器访问网站的时候,浏览器会发送一小段信息给网站,我们称为Request Headers,在这个头部信息里面包含了本次访问的一些信息,例如编码方式,当前地址,将要访问的地址等等。这些信息一般来说是不必要的,但是现在很多网站会把这些信息利用起来。其中最常被用到的一个信息,叫做“User-Agent”。网站可以通过User-Agent来判断用户是使用什么浏览器访问。不同浏览器的User-Agent是不一样的,但都有遵循一定的规则。
但是如果我们使用 Python 的 Requests 直接访问网站,除了网址不提供其他的信息,那么网站收到的User-Agent是空。这个时候网站就知道我们不是使用浏览器访问的,于是它就可以拒绝我们的访问。
如何获取网站的 User-Agent 呢?
请打开 Chrome,任意打开一个网站,然后右键,“检查” 打开开发者工具,定位到 “Network” 选项卡,并刷新网页,如下图所示:
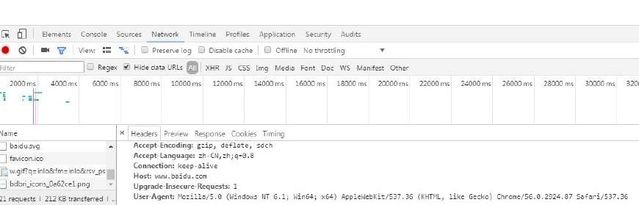
在左下角会出现当前网页加载的所有元素。随便点一个元素,于是在右下角会出现对当前元素的请求信息。在里面找到Request Headers这一项,里面的内容即为我们需要的内容。
host 提供了主机名及端口号
Accept 告诉服务器能够发送哪些媒体类型
Accept-Charset 告诉服务器能够发送哪些字符集
Accept-Encoding 告诉服务器能够发送哪些编码方式(最常见的是utf-8)
Accept-Language 告诉服务器能够发送哪些语言
Cache-control 这个字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令
User agent 发送请求的应用程序名(一些网站会根据UA访问的频率间隔时间进行反爬)
cookie 特定的标记信息,一般可以直接复制,对于一些变化的可以选择构造(有关cookie的内容将在另一篇博文中进行详细介绍)
不同的网站,Request Headers 是不同的
提示:post方法,session模块的get方法,以及Session模块的get方法,post方法,都支持自定义Headers,参数名为headers,他可以接收字典作为参数。我们可以通过字典来设定Headers,例如:

所以,检查User-Agent是一种最简单的反爬虫机制,而通过设定Request Headers中的User-Agent,可以突破这种机制。
除此之外呢,下面介绍一个python下非常好用的伪装请求头的库:fake-useragent,具体使用说明如下:
安装fake-useragent库
pip install fake-useragent
获取各浏览器的fake-useragent
1 from fake_useragent import UserAgent
2 ua = UserAgent()
3 #ie浏览器的user agent
4 print(ua.ie)
5
6 #opera浏览器
7 print(ua.opera)
8
9 #chrome浏览器
10 print(ua.chrome)
11
12 #firefox浏览器
13 print(ua.firefox)
14
15 #safri浏览器
16 print(ua.safari)
17
18 #最常用的方式
19 #写爬虫最实用的是可以随意变换headers,一定要有随机性。支持随机生成请求头
20 print(ua.random)
21 print(ua.random)
22 print(ua.random)
示例代码
1 from fake_useragent import UserAgent
2 import requests
3 ua=UserAgent()
4 #请求的网址
5 url="http://www.baidu.com"
6 #请求头
7 headers={"User-Agent":ua.random}
8 #请求网址
9 response=requests.get(url=url,headers=headers)
10 #响应体内容
11 print(response.text)
12 #响应状态信息
13 print(response.status_code)
14 #响应头信息
15 print(response.headers)
原文:https://blog.csdn.net/qq_29186489/article/details/78496747