ofo是国内共享单车模式的开创者,引航者。在18年之前的单车风口上一时风头无两,曾花费一千万购买行星命名权,可见其财大气粗。后来潮水褪去,ofo疯狂烧钱挤占市场倾轧对手的策略最终搁浅,风光不再,连退押金都成了问题。
现如今,退押金需要排队,很多人都已经排到了一千多万名的队伍。我爬取了某用户数天内的排名变化情况,进而推测到底该用户何时才能拿到押金。
数据集大致如图1所示。
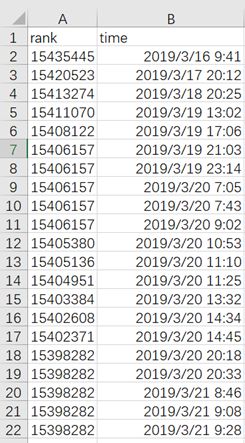
该数据集一共有两列,163行。记录了从2019/3/16-2019/3/22这七天的排名变化情况。先利用该数据集画一个最简单的散点图,观察大致的数据情况。
import pandas as pd
from pandas import DataFrame,Series
from dateutil import parser
from matplotlib import pyplot as plt
data = pd.read_csv('ofo.csv')
times = []
for i in range(len(data.loc[:,'time'])):
data.loc[i,'time'] = parser.parse(data.loc[i,'time'])#将每个字符串类型转换为时间类型
print(data) #输出data观察数据
plt.plot_date(data['time'],data['rank'])
plt.savefig('散点图.png', bbox_inches='tight') #保存图片并去掉周围空白
plt.xticks(rotation=45) #旋转横坐标
plt.show()
效果如图2所示。
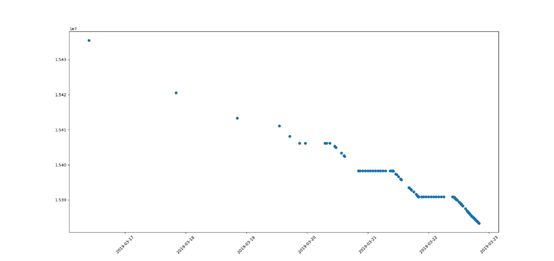
可以看出虽然该数据集时间范围包含了七天,可是从20号开始点才比较密集,因此缩小时间范围,重新观察。通过9.2图,发现22号的点最密集,覆盖时间范围也最完整,因此把时间范围缩减到22号这一点继续进行分析。
#引入包
import pandas as pd
from pandas import DataFrame,Series
from dateutil import parser
from matplotlib import pyplot as plt
data = pd.read_csv('ofo.csv')
times = []
for i in range(len(data.loc[:,'time'])):
data.loc[i,'time'] = parser.parse(data.loc[i,'time'])
data.set_index(['time'],inplace=True) #把时间列变为索引
ofo = data['2019-03-22'] #利用时间索引类型切片22号这天的时间序列
ofo['time'] = ofo.index #再将索引变为列
plt.plot_date(ofo['time'],ofo['rank']) #绘制散点图
plt.savefig('散点图.png', bbox_inches='tight') #保存图片并去掉周围空白
plt.xticks(rotation=45) #旋转横坐标
plt.show()
这里要提及一下代码逻辑。第一步通过循环把每个类型为字符串的时间点变为时间类型,然后把存有该类型的列变为索引。第二步通过索引提取时间序列切片。第三步再把索引变回列。最后第四步使用plot_date函数绘制散点图。
为什么这么麻烦?兜了一个圈子把时间这列变来变去。首先,只有当索引为时间类型时才可以如此切片,即直接传入’2019-03-22’就可以得到时间范围是该天的时间序列。其次,绘制散点图不可以用Series,只可以使用Dataframe。如果把时间列当为索引,该数据类型只有一列rank,就变成了Series。所以要把时间列再变回去,成为Dataframe才可以。
还有要注意一点的是,当使用传统的scatter函数时绘制散点图会失败。这是因为该函数绘制散点图时只接受x轴为数字。这里需要使用plot_date函数,该函数专门应对绘制时间序列的散点图。
代码效果如图3所示。
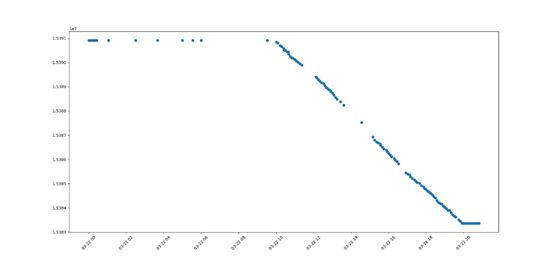
从该图中可以大致发现一些规律。在22号这天,早上十点之前,晚上八点以后,排名是没有变化的,推测这应该是ofo的下班时间。(一天工作10个小时,还算可以了,哈哈)然后在工作时间内,基本随着时间呈线性下降趋势。所以进一步研究,截取10:00-20:00这段时间来观察。
代码基本同上,做如下改动即可:
ofo = data['2019-03-22 10:00':'2019-03-22 20:00']
效果如图4所示。

通过这张图以及结合原始数据集可知,ofo界面每五分钟刷新一次,更改一次退押金排队位置。可以大致看出,一天内十个小时,rank的变化速率比较均匀,基本是在匀速降低。接下来,具体求解到底这个速率是多少。
引入包上面已经给出
data = pd.read_csv('ofo.csv')
times = []
for i in range(len(data.loc[:,'time'])):
data.loc[i,'time'] = parser.parse(data.loc[i,'time'])
data.set_index(['time'],inplace=True)
ofo = data['2019-03-22 10:00':'2019-03-22 20:00']
ofo_shift = ofo.shift(1) #滞后,方便后面进行减法运算
ofo_speed_rank = ofo_shift – ofo #两个Series相减
ofo_speed_rank.plot()
plt.show()
通过shift函数实现时间序列的滞后(函数参数正为滞后,负为超前),方便了之后两个Series之间相减,然后绘制简单的折线图,观察每五分钟,排名变化情况。
效果如图5所示。

结合图4可以发现如下几个问题。
一、有几个时间段没有数据(数据缺失),造成中间间隔较大,并不是每五分钟都有数据的。二、有几个时间点速率为0,这是由于间隔点太密集造成排名无变化造成的。通过折线图大致看出正常情况下每五分钟rank降低个数都不会超过200,因此,利用数据过滤功能,重新绘图。效果如图6。
代码改动如下:
ofo_speed_rank = ofo_speed_rank[ofo_speed_rank['rank']<200]
ofo_speed_rank = ofo_speed_rank[ofo_speed_rank['rank']>0]
ofo_speed_rank['time'] = ofo_speed_rank.index
print(ofo_speed_rank)
plt.plot_date(ofo_speed_rank['time'],ofo_speed_rank['rank'])
plt.show()
从该散点图中可以大致看出,点主要集中在40-100之间。可以添加直线更加直观得观察。如图7所示。
plt.plot_date(ofo_speed_rank['time'],ofo_speed_rank['rank'])
x = pd.date_range(start='2019-3-22 09:00', periods=13, freq='H')
y1=[]
y2=[]
for i in range(13):
y1.append(40)
y2.append(100)
plt.plot(x,y1)
plt.plot(x,y2)
plt.show()

而且在40-100之间分布得相当均匀,并且从时间线上来观察,也相当得均匀,可以推测ofo是通过机器来管控押金退款的,而不是人工管理。接下来求落在40-100之间的点的平均值即可。
ofo_speed_rank = ofo_speed_rank[ofo_speed_rank['rank']<100]
ofo_speed_rank = ofo_speed_rank[ofo_speed_rank['rank']>40]
print(ofo_speed_rank.describe())
结果如下。
rank
count 63.000000
mean 66.365079
std 14.520621
min 44.000000
25% 53.000000
50% 66.000000
75% 77.500000
max 99.000000
最大值99,最小值44,平均值66,标准差14.52。就以每五分钟处理66个押金退款来说,每天工作十小时可处理7920个退款。像文中使用者一千五百万的排名,需要等1894天,也就是大约五年的时间。
未来可期!