20172313 2018-2019-1 《程序设计与数据结构》实验一报告
课程:《程序设计与数据结构》
班级: 1723
姓名: 余坤澎
学号:20172313
实验教师:王志强
实验日期:2018年9月26日
必修/选修: 必修
1.实验内容
- 实验一 参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder),用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台。
- 实验二 基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树,用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台。
- 实验三 自己设计并实现一颗决策树,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台。
- 实验四 输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分),提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台。
- 实验五 完成PP11.3,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台。
- 实验六 参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
2. 实验过程及结果
实验一
- getRight方法只需要新定义一个LinkedBinaryTree类,令它的根结点等于原树的右子树的结点即可。注意:首先要判断原树的根结点是否为空,若空,则抛出异常。
public LinkedBinaryTree getRight()
{
if(root == null)
throw new EmptyCollectionException("Get right operation failed. The tree is empty.");
LinkedBinaryTree result = new LinkedBinaryTree<>();
result.root = root.getRight();
return result;
} - contains方法调用findNode方法即可。当findNode返回值不为空时,该方法返回true,即存在,否则不存在。
public boolean contains(T targetElement)
{
if(findNode(targetElement,root) != null)
return true;
else
return false;
}- 在这里toString我使用的是原先学习的按照树的形状打印树的方法。
public String toString() {
UnorderedListADT nodes =
new ArrayUnorderedList();
UnorderedListADT levelList =
new ArrayUnorderedList();
BinaryTreeNode current;
String result = "";
int printDepth = this.getHeight();
int possibleNodes = (int)Math.pow(2, printDepth + 1);
int countNodes = 0;
nodes.addToRear(root);
Integer currentLevel = 0;
Integer previousLevel = -1;
levelList.addToRear(currentLevel);
while (countNodes < possibleNodes)
{
countNodes = countNodes + 1;
current = nodes.removeFirst();
currentLevel = levelList.removeFirst();
if (currentLevel > previousLevel)
{
result = result + "\n\n";
previousLevel = currentLevel;
for (int j = 0; j < ((Math.pow(2, (printDepth - currentLevel))) - 1); j++)
result = result + " ";
}
else
{
for (int i = 0; i < ((Math.pow(2, (printDepth - currentLevel + 1)) - 1)) ; i++)
{
result = result + " ";
}
}
if (current != null)
{
result = result + (current.getElement()).toString();
nodes.addToRear(current.getLeft());
levelList.addToRear(currentLevel + 1);
nodes.addToRear(current.getRight());
levelList.addToRear(currentLevel + 1);
}
else {
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
result = result + " ";
}
}
return result;
}
- preorder,postorder方法参考书上inorder方法即可。(在这里只列举preorder方法的代码)
public Iterator iteratorPreOrder()
{
ArrayUnorderedList tempList = new ArrayUnorderedList();
preOrder(root, tempList);
return new TreeIterator(tempList.iterator());
}
protected void preOrder(BinaryTreeNode node,
ArrayUnorderedList tempList)
{
if (node != null)
{
tempList.addToRear(node.getElement());
preOrder(node.getLeft(), tempList);
preOrder(node.getRight(), tempList);
}
} - 所有方法实现之后,编写驱动类对LinkedBinaryTree进行测试。
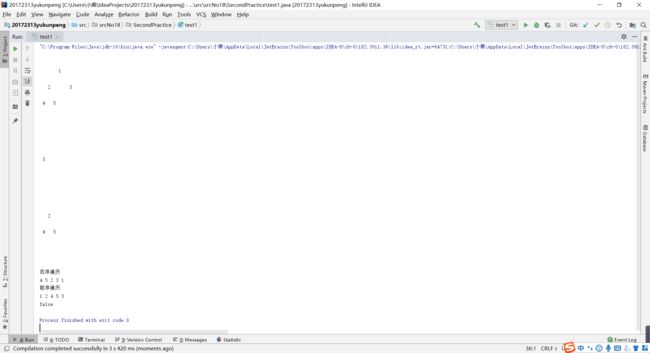
实验二
- 实验一比较容易,所有的代码基本上在以前都实现过,稍加参考就能完成。实验二就比较难了,要使用中序序列和前序序列构造二叉树。设计思路如下:
- ①我们要确定根节点的位置,先序遍历的第一个结点就是该二叉树的根。
- ② 确定根的子树,有中序遍历可知,我们在中序遍历中找到根结点的位置,左边是它的左孩子,右边是它的右孩子,如果根结点左边或右边为空,那么在该方向上子树为空,如果根结点左边和右边都为空,那么该结点是叶子结点。
- ③对二叉树的左、右子树分别进行步骤①②,直到求出二叉树的结构为止。
- 该实验的主要难度在于如何使用递归不断对左右子树重复进行①②步骤,可根据传入的序列的数组的索引值进行分割,在中序序列中但凡比根元素索引值小的即为根元素的左结点,大的即为根元素的右结点。按照中序序列分成的两部分元素又可以把前序序列分成两部分,接下来用递归,把新得到的序列数组作为参数,直到形成二叉树的结构。
public void buildTree(T[] inorder, T[] postorder) {
BinaryTreeNode temp=makeTree(inorder, 0, inorder.length, postorder, 0, postorder.length);
root = temp;
}
public BinaryTreeNode makeTree(T[] inorder,int startIn,int lenIn,T[] postorder,int startPos,int lenPos){
if(lenIn<1){
return null;
}
BinaryTreeNode root;
T rootelement=postorder[startPos];//postorder中的第一个元素就是当前处理的数据段的根节点
root=new BinaryTreeNode(rootelement);
int temp;
boolean isFound=false;
for(temp=0;temp 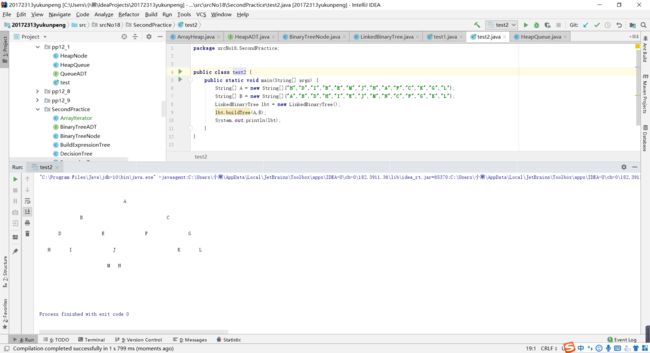
实验三
- 实验三可以说是最简单的了,有了书上的示例进行参考,对文件进行修改即可,在这里不再过多赘述。
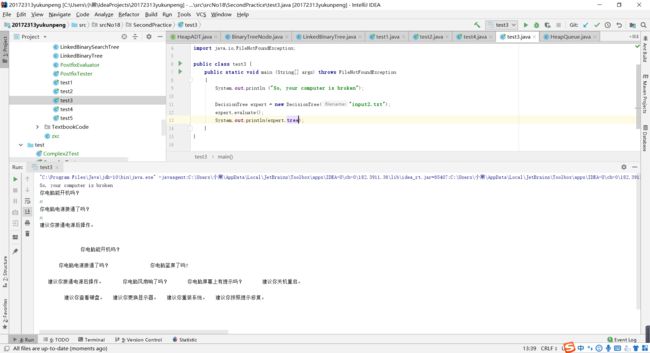
实验四
- 这个实验是本次实验中最有难度的一个,虽然原先学习过中缀表达式转后缀表达式求值的问题,但使用树来进行操作还是第一次。使用后缀表达式进行求值课堂上学习过,书上也有示例代码。这里只列举使用树把中缀表达式变为后缀表达式。设计思路如下:
- 定义两个列表分别用来操作符和“子树“,注意:这里的操作符列表里只存“+”“-”,至于为什么将在下面进行分析。首先把中缀表达式用StringTokenizer方法进行分开,从前到后依次遍历,如果是括号,就把括号里面的内容作为一个新的表达式传入该方法,把返回的结点作为一棵新树的根存进numList。如果遍历到数字,作为一棵新树的element存入numList,如果遍历到“+”“-”,直接存入operLIst中。如果遇到“乘或除”,如果“乘或除”的往后遍历到的是括号,则先把括号里的内容作为一个新的表达式传入该方法,把返回的结点作为“乘号”的右子树的根结点,然后从numList取出最后一个元素作为“乘号”的左子树的根结点。如果“乘或除”的往后遍历到的是数字,则直接作为“乘号”的右子树的根结点,然后从numList取出最后一个元素作为“乘号”的左子树的根结点。
- 这里的核心思想就是一旦遇到括号就把括号里的内容作为参数传入该方法,由于括号运算的优先级,可以把得到的该结点传入numList,在形成二叉树的过程中直接取出。一旦遇到“乘或除”就从numList的末尾取出一位元素作为它的左子树,“乘或除”的下一位元素作为它的右子树,然后把这个子树存入numList,这样在保证了运算优先级的同时,也使得形成二叉树的时候顺序不会被打乱,这就是为什么操作符列表里只存“+”“-”操作符列表里只存“+”“-”,因为“乘或除”作为子树的根结点都存入到了numList。一直到遍历完成,这时候我们知道,最先进入numList的运算优先级最高,所以从索引为0处开始取元素,把它们组装成一棵二叉树即可。
public BinaryTreeNode buildTree(String str) { ArrayListoperList = new ArrayList<>(); ArrayList numList = new ArrayList<>(); StringTokenizer st = new StringTokenizer(str); String token; while (st.hasMoreTokens()) { token = st.nextToken(); if (token.equals("(")) { String str1 = ""; while (true) { token = st.nextToken(); if (!token.equals(")")) str1 += token + " "; else break; } LinkedBinaryTree temp = new LinkedBinaryTree(); temp.root = buildTree(str1); numList.add(temp); token = st.nextToken(); } if (token.equals("+") || token.equals("-")) { operList.add(token); } else if (token.equals("*") || token.equals("/")) { LinkedBinaryTree left = numList.remove(numList.size() - 1); String A = token; token = st.nextToken(); if (!token.equals("(")) { LinkedBinaryTree right = new LinkedBinaryTree(token); LinkedBinaryTree node = new LinkedBinaryTree(A, left, right); numList.add(node); } else { String str1 = ""; while (true) { token = st.nextToken(); if (!token.equals(")")) str1 += token + " "; else break; } LinkedBinaryTree temp2 = new LinkedBinaryTree(); temp2.root = buildTree(str1); LinkedBinaryTree node1 = new LinkedBinaryTree(A, left, temp2); numList.add(node1); } } else numList.add(new LinkedBinaryTree(token)); } while (operList.size() > 0) { LinkedBinaryTree left = numList.remove(0); LinkedBinaryTree right = numList.remove(0); String oper = operList.remove(0); LinkedBinaryTree node2 = new LinkedBinaryTree(oper, left, right); numList.add(0, node2); } node = (numList.get(0)).root; return node; }
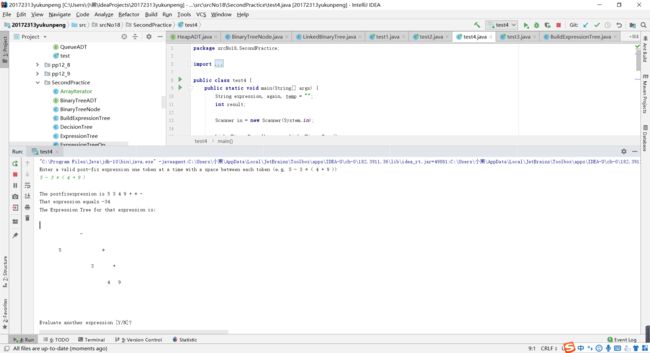
实验五
- 实验五相较于实验四来说又简单了一些,由于二叉查找树的最小元素始终位于整棵树左下角最后一个左子树的第一个位置,最大元素始终位于整棵树右下角最后一个右子树的最后一个位置。从根结点进行遍历即可。注意:这里要判断树为空和结点的左右子树是否存在。
public T removeMax() throws EmptyCollectionException
{
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else
{
if (root.right == null)
{
result = root.element;
root = root.left;
}
else
{
BinaryTreeNode parent = root;
BinaryTreeNode current = root.right;
while (current.right != null)
{
parent = current;
current = current.right;
}
result = current.element;
parent.right = current.left;
}
modCount--;
}
return result;
}
public T findMin() throws EmptyCollectionException
{
if(isEmpty())
System.out.println("BinarySearchTree is empty!");
return findMin(root).getElement();
}
private BinaryTreeNode findMin(BinaryTreeNode p) {
if (p==null)//结束条件
return null;
else if (p.left==null)//如果没有左结点,那么t就是最小的
return p;
return findMin(p.left);
}
public T findMax() throws EmptyCollectionException
{
if(isEmpty())
System.out.println("BinarySearchTree is empty!");
return findMax(root).getElement();
}
private BinaryTreeNode findMax(BinaryTreeNode p){
if (p==null)//结束条件
return null;
else if (p.right==null)
return p;
return findMax(p.right);
} 实验六
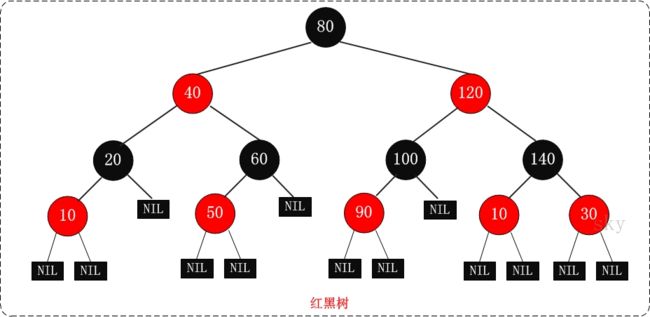
- 红黑树(Red Black Tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。首先,我们先来看看它的性质
- 树中的每一个结点都储存着一种颜色(红色或黑色,通常使用一个布尔值来实现,值false等价于红色)。
- 根结点为黑色。
- 每个叶子结点(null)是黑色。(**注意:这里的叶子结点,是指为空(null)的叶子结点!)
- 从树根到树叶的每条路径都包含有同样数目的黑色结点。
- 如果一个结点的颜色为红色,那么它的子结点必定是黑色。
- 红黑树示意图:
- TreeMap概述:TreeMap是基于红黑树实现的。由于TreeMap实现了java.util.sortMap接口,集合中的映射关系是具有一定顺序的,该映射根据其键的自然顺序进行排序或者根据创建映射时提供的Comparator进行排序,具体取决于使用的构造方法。另外TreeMap中不允许键对象是null。
- TreeMap类:
public class TreeMapTreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。 - TreeMap常用方法:
- TreeMap的构造函数
//使用默认构造函数构造TreeMap时,使用java的默认的比较器比较Key的大小,从而对TreeMap进行排序。 public TreeMap() { comparator = null; } //带比较器的构造函数 public TreeMap(Comparator comparator) { this.comparator = comparator; } //带Map的构造函数,Map会成为TreeMap的子集 ublic TreeMap(Map m) { comparator = null; putAll(m); } //该构造函数会调用putAll()将m中的所有元素添加到TreeMap中。从中,我们可以看出putAll()就是将m中的key-value逐个的添加到TreeMap中。putAll()源码如下: public void putAll(Map m) { for (Map.Entry e : m.entrySet()) put(e.getKey(), e.getValue()); } //带SortedMap的构造函数,SortedMap会成为TreeMap的子集,该构造函数不同于上一个构造函数,在上一个构造函数中传入的参数是Map,Map不是有序的,所以要逐个添加。而该构造函数的参数是SortedMap是一个有序的Map,我们通过buildFromSorted()来创建对应的Map。 public TreeMap(SortedMap- V put(K key,V value):将键值对(key,value)添加到TreeMap中
public V put(K key, V value) {//插入或设置元素,返回原始value值(如果插入返回null) Entry- 按照key值进行查找
final Entry getEntry(Object key) {//根据key值查找元素方法;final方法不允许被子类重写
// Offload comparator-based version for sake of performance
if (comparator != null)//存在比较器,按比较器进行比较查找
return getEntryUsingComparator(key);
if (key == null)//key值为null抛空指针异常
throw new NullPointerException();
Comparable k = (Comparable) key;
Entry p = root;
while (p != null) {//从root开始循环查找,一直到叶子节点
int cmp = k.compareTo(p.key);//采用key的compareTo方法进行比较
if (cmp < 0)//小于继续查找左边
p = p.left;
else if (cmp > 0)//大于继续查找右边
p = p.right;
else
return p;//等于返回当前元素
}
return null;
} - 删除操作
blic V remove(Object key) {
Entry p = getEntry(key);//先找到需要删除的元素
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
private void deleteEntry(Entry p) {
modCount++;
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {//如果有两个孩子
Entry s = successor (p);//查找下一元素
p.key = s.key;
p.value = s.value;//p的数据替换为该元素数据
p = s;//将p指向该元素,作为原始元素(被删除元素)
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry replacement = (p.left != null ? p.left : p.right);//将替换元素设置为左元素(没有则为右元素)
if (replacement != null) {//替换元素不为空
// Link replacement to parent
replacement.parent = p.parent;//将替换元素与原始元素的父亲连接起来
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;//原始元素连接清空
// Fix replacement
if (p.color == BLACK)//删除元素为黑色,需要进行删除后树形变化操作
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;//根节点的删除
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
//没有孩子时,使用自己作为替换节点,先树形变化再进行连接清空操作
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
private void fixAfterDeletion(Entry x) {//删除数据后的树形变化处理
while (x != root && colorOf(x) == BLACK) {//当前节点为黑(替换元素不可能为黑,只有删除自身的情况)
if (x == leftOf(parentOf(x))) {//左节点
Entry sib = rightOf(parentOf(x));//取父亲的右节点(兄节点)
if (colorOf(sib) == RED) {//颜色为红
setColor(sib, BLACK);
setColor(parentOf(x), RED);//着色
rotateLeft(parentOf(x));//按父左旋
sib = rightOf(parentOf(x));//指向左旋后的父亲的右节点(为黑)
}
//颜色为黑
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {//两个孩子均为黑(实际只可能为无孩子情况)
setColor(sib, RED);//着色
x = parentOf(x);//x指向父节点继续判断
} else {
if (colorOf(rightOf(sib)) == BLACK) {//右节点为黑(实际只可能为无右孩子)
setColor(leftOf(sib), BLACK);
setColor(sib, RED);//着色
rotateRight(sib);//按兄右旋
sib = rightOf(parentOf(x));//指向右旋后的父亲的右节点
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);//着色
rotateLeft(parentOf(x));//按父左旋
x = root;//结束循环
}
} else { // symmetric//右节点
Entry sib = leftOf(parentOf(x));//取父亲的左节点(兄节点)
if (colorOf(sib) == RED) {//颜色为红
setColor(sib, BLACK);
setColor(parentOf(x), RED);//着色
rotateRight(parentOf(x));//按父右旋
sib = leftOf(parentOf(x));//指向右旋后的父亲的左节点(为黑或空)
}
//颜色为黑
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {//两个孩子均为黑
setColor(sib, RED);//着色
x = parentOf(x);//x指向父节点继续判断
} else {
if (colorOf(leftOf(sib)) == BLACK) {//左节点为黑
setColor(rightOf(sib), BLACK);
setColor(sib, RED);//着色
rotateLeft(sib);//按兄左旋
sib = leftOf(parentOf(x));//指向左旋后的父亲的左节点
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(leftOf(sib), BLACK);//着色
rotateRight(parentOf(x));//按父右旋
x = root;//结束循环
}
}
}
setColor(x, BLACK);//将x置为黑色
} - 红黑树具体的添加或删除示意图可参照往期博客
- 关于 firstEntry() 和 getFirstEntry()都是用于获取第一个结点,那么两者到底有什么区别呢?
- firstEntry() 是对外接口; getFirstEntry() 是内部接口。而且,firstEntry() 是通过 getFirstEntry() 来实现的。那为什么外界不能直接调用 getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?这么做的目的是:防止用户修改返回的Entry。getFirstEntry()返回的Entry是可以被修改的,但是经过firstEntry()返回的Entry不能被修改,只可以读取Entry的key值和value值。
- HashMap类
- Java最基本的数据结构有数组和链表。数组的特点是空间连续(大小固定)、寻址迅速,但是插入和删除时需要移动元素,所以查询快,增加删除慢。链表恰好相反,可动态增加或减少空间以适应新增和删除元素,但查找时只能顺着一个个节点查找,所以增加删除快,查找慢。有没有一种结构综合了数组和链表的优点呢?当然有,那就是哈希表(虽说是综合优点,但实际上查找肯定没有数组快,插入删除没有链表快,一种折中的方式吧)。一般采用拉链法实现哈希表。
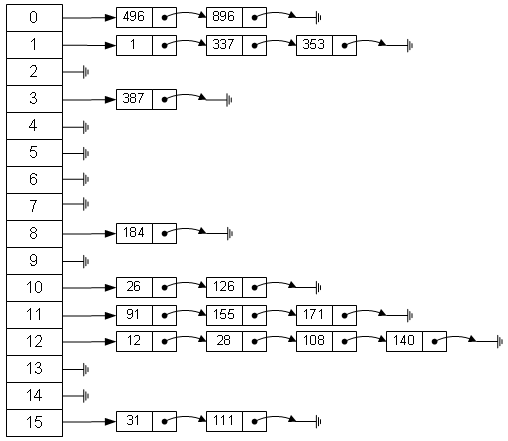
- Java最基本的数据结构有数组和链表。数组的特点是空间连续(大小固定)、寻址迅速,但是插入和删除时需要移动元素,所以查询快,增加删除慢。链表恰好相反,可动态增加或减少空间以适应新增和删除元素,但查找时只能顺着一个个节点查找,所以增加删除快,查找慢。有没有一种结构综合了数组和链表的优点呢?当然有,那就是哈希表(虽说是综合优点,但实际上查找肯定没有数组快,插入删除没有链表快,一种折中的方式吧)。一般采用拉链法实现哈希表。
- HashMap常用方法:
- put()操作:在使用的时候,我们一定会想到如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?为了解决这个问题,HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。
public V put(K key, V value) { //如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,此时threshold为initialCapacity 默认是1<<4(=16) if (table == EMPTY_TABLE) { inflateTable(threshold);//分配数组空间 } //如果key为null,存储位置为table[0]或table[0]的冲突链上 if (key == null) return putForNullKey(value); int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀 int i = indexFor(hash, table.length);//获取在table中的实际位置 for (Entry- inflateTable的源码如下:
private void inflateTable(int toSize) { int capacity = roundUpToPowerOf2(toSize);//capacity一定是2的次幂 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//此处为threshold赋值,取capacity*loadFactor和MAXIMUM_CAPACITY+1的最小值,capaticy一定不会超过MAXIMUM_CAPACITY,除非loadFactor大于1 table = new Entry[capacity];//分配空间 initHashSeedAsNeeded(capacity);//选择合适的Hash因子 }- inflateTable这个方法用于为主干数组table在内存中分配存储空间,通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于toSize的最接近toSize的二次幂,roundUpToPowerOf2中的这段处理使得数组长度一定为2的次幂,Integer.highestOneBit是用来获取最左边的bit(其他bit位为0)所代表的数值。在对数组进行空间分配后,会根据hash函数计算散列值。通过hash函数得到散列值后,再通过indexFor进一步处理来获取实际的存储位置。通过以上分析,我们看到,要得到一个元素的存储位置,需要如下几步:
- ①获取该元素的key值
- ②通过hash方法得到key的散列值,这其中需要用到key的hashcode值。
- ③通过indexFor计算得到存储的下标位置。
- 最后,得到存储的下标位置后,我们就可以将元素放入HashMap中,具体通过addEntry实现:
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length);//当size超过临界阈值threshold,并且即将发生哈希冲突时进行扩容,新容量为旧容量的2倍 hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length);//扩容后重新计算插入的位置下标 } //把元素放入HashMap的桶的对应位置 createEntry(hash, key, value, bucketIndex); } //创建元素 void createEntry(int hash, K key, V value, int bucketIndex) { Entry3. 实验过程中遇到的问题和解决过程
- 问题1:在做第二个实验的时候,递归完成后打印的二叉树个预期的不一样。
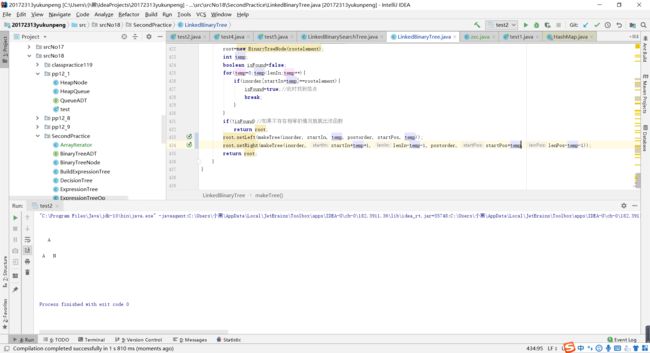
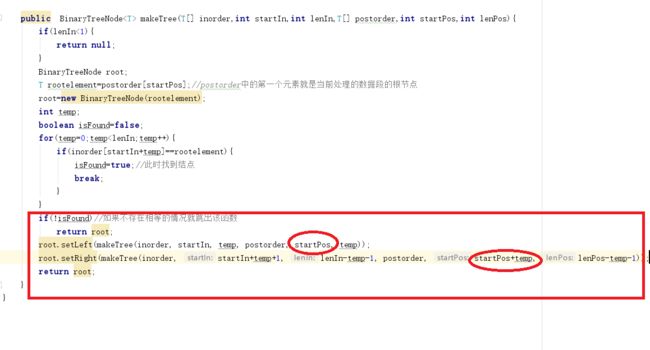
- 问题1解决方案:我先是检查了一遍循环,利用循环在中序序列中找到根节点,我debug了一遍,没有在循环这里发现错误。那就是递归存在问题,我重新捋了一遍自己的思路,根据传入的序列的数组的索引值进行分割,在中序序列中但凡比根元素索引值小的即为根元素的左结点,大的即为根元素的右结点。按照中序序列分成的两部分元素又可以把前序序列分成两部分,接下来用递归,把新得到的序列数组作为参数,直到形成二叉树的结构。我又仔细检查了一下自己的代码,发现了问题所在:因为前序序列的第一个是根元素,所以在进行递归传入参数时startpos变量需要加1,加上后,问题就解决了。
- 问题2:在做第四个实验的时候,始终不能正确的把中缀表达式转换为后缀表达式。
- 问题2解决方案:我先对循环体进行debug,由于代码中的判断条件和循环条件过多,所以的debug的效果并不理想。我仔细检查了一下生成的后缀表达式,发现排列的顺序是相反的,这就说明从numList弹出的时候顺序是不对的。我又仔细想了一下,先进入numList的优先级是最高的,构造二叉树的时候优先级高的成为左子树。所以numList是从前往后遍历的,这样一来,我就找到了我的问题所在。我误在numList弹出元素的时候把索引值设置成了size()-1,改成0问题就得以解决了。


其他
这次实验的难度分布的比较不均匀,大体上来说就是简单的很简单,难的非常难,在一些小地方也浪费了很多时间,导致没有在预想的时间内完成实验,希望自己能在以后的学习生活中继续努力,不断进步!
参考资料
- 二叉树专题-根据前序和中序序列构造二叉树
- 二叉树中缀表达式到后缀表达式的转换
- Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例
- HashMap实现原理及源码分析