https://www.jianshu.com/p/a07d1d4004b0 源问题集合
Java基础
1、List 和 Set 的区别
- List有序,元素可重复
- Set无序,元素不可重复
2、HashSet 是如何保证不重复的
- add之前先判断hash值,和equals, 一样就不存
3、HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程环境下不安全)?
- 不安全, put的时候resize和rehash可能导致死循环
- 遍历时候不允许修改,ConcurrentModificationException, fast-fail, check modificationCount
4、HashMap 的扩容过程
- size > threshold
- table *= 2
- rehash
5、HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
- 链表长度>8 -> 红黑树
- rehash算法进行改进
6、final finally finalize
- final, 类不能继承, 方法不能重载, 变量不能改变
- fianlly 永远会被执行
- finalize, GC的时候调用, 不应该依赖他, 因为不确定GC什么时候进行
7、强引用 、软引用、 弱引用、虚引用
- 正常持有的引用
- 内存不够时候释放的引用
- GC时候一定释放的引用
- 可能在对象回收时候收到一个通知, DirectBuffer里面用到
8、Java反射
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象.
- Class
- Constructor
- Method
- Field
9、Arrays.sort 实现原理和 Collections.sort 实现原理
- Arrays.sort -> DualPivotQuicksort 双基准快排(O(n log(n))),比传统(one-pivot)快排要快
- Colelctions.sort 底层调用Arrays.sort
10、LinkedHashMap的应用
- 它继承自HashMap,实现了Map
- 默认情况,遍历时的顺序是按照插入节点的顺序。这也是其与HashMap最大的区别。
也可以在构造时传入accessOrder参数,使得其遍历顺序按照访问的顺序输出。 - accessOrder ,默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序。为true时,可以在这基础之上构建一个LruCache.
- accessOrder=true的模式下,在afterNodeAccess()函数中,会将当前被访问到的节点e,移动至内部的双向链表的尾部。值得注意的是,afterNodeAccess()函数中,会修改modCount,因此当你正在accessOrder=true的模式下,迭代LinkedHashMap时,如果同时查询访问数据,也会导致fail-fast,因为迭代的顺序已经改变。
- LinkedHashMap相对于HashMap的源码比,是很简单的。因为大树底下好乘凉。它继承了HashMap,仅重写了几个方法,以改变它迭代遍历时的顺序。这也是其与HashMap相比最大的不同。
在每次插入数据,或者访问、修改数据时,会增加节点、或调整链表的节点顺序。以决定迭代时输出的顺序。
11、cloneable接口实现原理
- 它的作用是使一个类的实例能够将自身拷贝到另一个新的实例中,注意,这里所说的“拷贝”拷的是对象实例,而不是类的定义,进一步说,拷贝的是一个类的实例中各字段的值。
- 如果一个类不实现该接口就直接调用clone()方法的话,即便已将clone()方法重写为public,那还是会抛出“不支持拷贝”异常。因此,要想使一个类具备拷贝实例的功能,那么除了要重写Object类的clone()方法外,还必须要实现Cloneable接口。
- 浅拷贝: 对于对象成员变量,只是将引用进行复制,原来的引用修改以后,拷贝对象成员变量的值也会改变(Object.clone)
- 深拷贝: 新建对象,将成员变量的值赋值给新建对象中成员
12、异常分类以及处理机制
- Checked Exception (IOException, SQLException, InterruptedException)
- Unchecked Exception (NullPointerException,IndexOutOfBoundsException)
13、wait和sleep的区别
- Thread.sleep, 不会导致线程释放锁,但是也会释放CPU
- Object wait, 会释放当前的锁, 只有其他线程执行notify/notifyAll的时候才可能重新获取CPU时间片
14、数组在内存中如何分配
- 数组初始化后,该数组所占用的内存空间、长度都是不可变的
- 一维数组,二维数组(存放了数组的数组)
- 数组变量存在栈区,数组对象存在堆内存,只能通过引用来访问堆内存中的数据
Java 并发
1、synchronized 的实现原理以及锁优化?
对象头和monitor是synchnorized的基础。
无锁->偏向锁->轻量级锁->重量级索
2、volatile 的实现原理?
java内存模型,读写屏障, happens before, L1 Cache
3、Java 的信号灯(Semaphore)?
控制访问线程的个数
4、synchronized 在静态方法和普通方法的区别?
- 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
5、怎么实现所有线程在等待某个事件的发生才会去执行?
- join
- CountDownLatch - A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.
- CyclicBarrier - A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point. CyclicBarriers are useful in programs involving a fixed sized party of threads that must occasionally wait for each other
- BlockingQueue
6、CAS?CAS 有什么缺陷,如何解决?
Compare and Swap, ABA, 版本号
7、synchronized 和 lock 有什么区别?
| synchronized | Lock |
|---|---|
| 关键字, jvm实现 | 类 |
| jvm控制锁的释放 | 必须在finally释放锁,不然容易死锁 |
| 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待 | 分情况而定,Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等待 |
| 锁状态无法判断 | 锁状态可以判断 |
| 可重入 不可中断 非公平 | 可重入 可判断 可公平(两者皆可) |
| 少量同步 | 大量同步 |
lock():获取锁,如果锁被暂用则一直等待
unlock():释放锁
tryLock(): 注意返回类型是boolean,如果获取锁的时候锁被占用就返回false,否则返回true
tryLock(long time, TimeUnit unit):比起tryLock()就是给了一个时间期限,保证等待参数时间
lockInterruptibly():用该锁的获得方式,如果线程在获取锁的阶段进入了等待,那么可以中断此线程,先去做别的事
8、Hashtable 是怎么加锁的 ?
方法上面加锁
9、HashMap 的并发问题?
10、ConcurrenHashMap 介绍?1.8 中为什么要用红黑树?
Node, 分bucket进行cas + sync, 提高性能
11、AQS
LCH
12、如何检测死锁?怎么预防死锁?
jstack
- 加锁顺序
- 加锁时间
- 死锁检测
- 无锁实现,队列,pipeline...
13、Java 内存模型?
本地内存- 主内存
14、如何保证多线程下 i++ 结果正确?
AtomicInteger
15、线程池的种类,区别和使用场景?
newCachedThreadPool
- 底层:返回ThreadPoolExecutor实例,corePoolSize为0;maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为60L;unit为TimeUnit.SECONDS;workQueue为SynchronousQueue(同步队列)
- 通俗:当有新任务到来,则插入到SynchronousQueue中,由于SynchronousQueue是同步队列,因此会在池中寻找可用线程来执行,若有可以线程则执行,若没有可用线程则创建一个线程来执行该任务;若池中线程空闲时间超过指定大小,则该线程会被销毁。
- 适用:执行很多短期异步的小程序或者负载较轻的服务器
newFixedThreadPool
- 底层:返回ThreadPoolExecutor实例,接收参数为所设定线程数量nThread,corePoolSize为nThread,maximumPoolSize为nThread;keepAliveTime为0L(不限时);unit为:TimeUnit.MILLISECONDS;WorkQueue为:new LinkedBlockingQueue
() 无解阻塞队列 - 通俗:创建可容纳固定数量线程的池子,每隔线程的存活时间是无限的,当池子满了就不在添加线程了;如果池中的所有线程均在繁忙状态,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:执行长期的任务,性能好很多
newSingleThreadExecutor:
- 底层:FinalizableDelegatedExecutorService包装的ThreadPoolExecutor实例,corePoolSize为1;maximumPoolSize为1;keepAliveTime为0L;unit为:TimeUnit.MILLISECONDS;workQueue为:new LinkedBlockingQueue
() 无解阻塞队列 - 通俗:创建只有一个线程的线程池,且线程的存活时间是无限的;当该线程正繁忙时,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:一个任务一个任务执行的场景
NewScheduledThreadPool
- 底层:创建ScheduledThreadPoolExecutor实例,corePoolSize为传递来的参数,maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为0;unit为:TimeUnit.NANOSECONDS;workQueue为:new DelayedWorkQueue() 一个按超时时间升序排序的队列
- 通俗:创建一个固定大小的线程池,线程池内线程存活时间无限制,线程池可以支持定时及周期性任务执行,如果所有线程均处于繁忙状态,对于新任务会进入DelayedWorkQueue队列中,这是一种按照超时时间排序的队列结构
- 适用:周期性执行任务的场景
16、分析线程池的实现原理和线程的调度过程?
- 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
- 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
- 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
- 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常RejectExecutionException。
- 当一个线程完成任务时,它会从队列中取下一个任务来执行。
- 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
17、线程池如何调优,最大数目如何确认?
18、ThreadLocal原理,用的时候需要注意什么?
其实在ThreadLocal类中有一个静态内部类ThreadLocalMap(其类似于Map),用键值对的形式存储每一个线程的变量副本,ThreadLocalMap中元素的key为当前ThreadLocal对象,而value对应线程的变量副本,每个线程可能存在多个ThreadLocal。
总之,为不同线程创建不同的ThreadLocalMap,用线程本身为区分点,每个线程之间其实没有任何的联系,说是说存放了变量的副本,其实可以理解为为每个线程单独new了一个对象。
19、CountDownLatch 和 CyclicBarrier 的用法,以及相互之间的差别?
CountDownLatch.countDown
20、LockSupport工具
阻塞
- void park():阻塞当前线程,如果调用unpark方法或者当前线程被中断,从能从park()方法中返回
- void park(Object blocker):功能同方法1,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
- void parkNanos(long nanos):阻塞当前线程,最长不超过nanos纳秒,增加了超时返回的特性;
- void parkNanos(Object blocker, long nanos):功能同方法3,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
- void parkUntil(long deadline):阻塞当前线程,知道deadline;
- void parkUntil(Object blocker, long deadline):功能同方法5,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
唤醒
void unpark(Thread thread):唤醒处于阻塞状态的指定线程
由synchronzed阻塞的线程加入到同步队列,再次被唤醒的线程是随机从同步队列中选择的,而LockSupport.unpark(thread)可以指定线程对象唤醒指定的线程。
21、Condition接口及其实现原理
- 使当前线程进入等待状态直到被通知(signal)或中断
- 当其他线程调用singal()或singalAll()方法时,该线程将被唤醒
- 当其他线程调用interrupt()方法中断当前线程
- await()相当于synchronized等待唤醒机制中的wait()方法
*/
void await() throws InterruptedException;
//当前线程进入等待状态,直到被唤醒,该方法不响应中断要求
void awaitUninterruptibly();
//调用该方法,当前线程进入等待状态,直到被唤醒或被中断或超时
//其中nanosTimeout指的等待超时时间,单位纳秒
long awaitNanos(long nanosTimeout) throws InterruptedException;
//同awaitNanos,但可以指明时间单位
boolean await(long time, TimeUnit unit) throws InterruptedException;
//调用该方法当前线程进入等待状态,直到被唤醒、中断或到达某个时
//间期限(deadline),如果没到指定时间就被唤醒,返回true,其他情况返回false
boolean awaitUntil(Date deadline) throws InterruptedException;
//唤醒一个等待在Condition上的线程,该线程从等待方法返回前必须
//获取与Condition相关联的锁,功能与notify()相同
void signal();
//唤醒所有等待在Condition上的线程,该线程从等待方法返回前必须
//获取与Condition相关联的锁,功能与notifyAll()相同
void signalAll();
AQS的内部类ConditionObject
22、Fork/Join框架的理解
ForkJoinTask与一般任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
23、分段锁的原理,锁力度减小的思考
ConcurrentHashMap
24、八种阻塞队列以及各个阻塞队列的特性
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
http://ifeve.com/java-blocking-queue/
Spring
1、BeanFactory 和 FactoryBean?
- BeanFactory: 工厂类,用来管理Bean的工厂, getBean, containsBean, isPrototype, getType ...方法
- FactoryBean: 一个bean, 根据该Bean的ID从BeanFactory中获取的实际上是FactoryBean的getObject()返回的对象,而不是FactoryBean本身,如果要获取FactoryBean对象,请在id前面加一个&符号来获取。
2、Spring IOC 的理解,其初始化过程?
Inversion of Control,
- BeanDifinition的Resource定位, 它由ResourceLoader通过统一的Resource接口来完成,这个Resource对各种形式的BeanDifinition的使用都提供了统一的接口。
- BeanDifinition的载入, 把用户定义好的Bean表示成Ioc容器内部的数据结构,而这个容器内部的数据结构就是BeanDifinition。
- BeanDifinition的注册, 通过调用BeanDifinitionRegistry借口来实现的。这个注册过程把载入过程中解析得到的BeanDifinition向Ioc容器进行注册。在IOC容器内部将BeanDifinition注入到一个HashMap中去,Ioc容器就是通过这个HashMap来持有这些BeanDifinition数据的。
3、BeanFactory 和 ApplicationContext?
BeanFactory
BeanFactory -> HierarchicalBeanFactory -> ConfigurableBeanFactory,是一个主要的BeanFactory设计路径。
- BeanFactory:基本规范,比如说getBean()这样的方法。
- HierarchicalBeanFactory:管理双亲IoC容器规范,比如说getParentBeanFactory()这样的方法。
- ConfigurableBeanFactory:对BeanFactory的配置功能,比如通过setParentBeanFactory()设置双亲IoC容器,通过addBeanPostProcessor()配置Bean后置处理器。
ApplicationContext
BeanFactory -> ListableBeanFactory 和 HierarchicalBeanFactory -> ApplicationContext -> ConfigurableApplicationContext
- ListableBeanFactory:细化了许多BeanFactory的功能,比如说getBeanDefinitionNames()。
- ApplicationContext:通过继承MessageSource、ResourceLoader、ApplicationEventPublisher接口,添加了许多高级特性。
4、Spring Bean 的生命周期,如何被管理的?

5、Spring Bean 的加载过程是怎样的?
6、如果要你实现Spring AOP,请问怎么实现?
7、如果要你实现Spring IOC,你会注意哪些问题?
https://www.cnblogs.com/fingerboy/p/5425813.html
8、Spring 是如何管理事务的,事务管理机制?
http://www.mamicode.com/info-detail-1248286.html
编程式事务和声明式事务

Spring并不直接管理事务,而是提供了多种事务管理器,他们将事务管理的职责委托给Hibernate或者JTA等持久化机制所提供的相关平台框架的事务来实现。
Spring事务管理器的接口是org.springframework.transaction.PlatformTransactionManager,通过这个接口,Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。此接口的内容如下:
事务属性 TransactionDefinition:
- 传播行为 int getPropagationBehavior()
- 隔离等级 int getIsolationLevel() //事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据
- 超时管理 int getTimeout(); //事务必须在多少秒内完成
- 是否只读 boolean isReadOnly();
事务状态 TransactionStatus
boolean isNewTransaction(); // 是否是新的事物
boolean hasSavepoint(); // 是否有恢复点
void setRollbackOnly(); // 设置为只回滚
boolean isRollbackOnly(); // 是否为只回滚
boolean isCompleted; // 是否已完成
9、Spring 的不同事务传播行为有哪些,干什么用的?
| 传播行为 | 含义 |
|---|---|
| PROPAGATION_REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则,会启动一个新的事务 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
| PROPAGATION_MANDATORY | 表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常 |
| PROPAGATION_REQUIRED_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NOT_SUPPORTED | 表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NEVER | 表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常 |
| PROPAGATION_NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与PROPAGATION_REQUIRED一样。注意各厂商对这种传播行为的支持是有所差异的。可以参考资源管理器的文档来确认它们是否支持嵌套事务 |
10、Spring 中用到了那些设计模式?
http://www.javainuse.com/spring/spring-design-patterns
11、Spring MVC 的工作原理?
https://www.cnblogs.com/xiaoxi/p/6164383.html
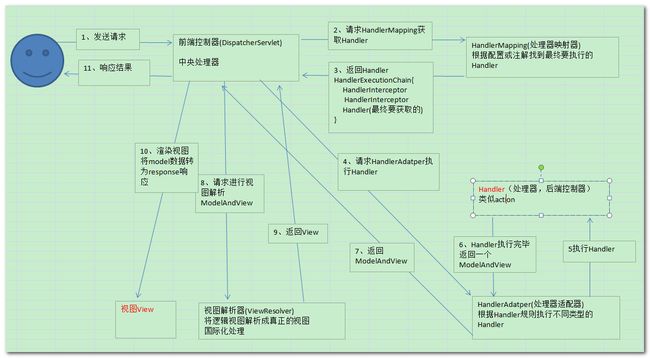
12、Spring 循环注入的原理?
http://jinnianshilongnian.iteye.com/blog/1415278
Spring容器循环依赖包括构造器循环依赖和setter循环依赖, 两个或多个Bean相互之间的持有对方。
13、Spring AOP的理解,各个术语,他们是怎么相互工作的?
14、Spring 如何保证 Controller 并发的安全?
Controller单例,避免竞争
Netty
1、BIO、NIO和AIO
2、Netty 的各大组件
3、Netty的线程模型
4、TCP 粘包/拆包的原因及解决方法
5、了解哪几种序列化协议?包括使用场景和如何去选择
6、Netty的零拷贝实现
7、Netty的高性能表现在哪些方面
分布式相关
1、Dubbo的底层实现原理和机制
2、描述一个服务从发布到被消费的详细过程
3、分布式系统怎么做服务治理
服务注册,发现,服务升/降级,限流,动态扩展,超时控制,优先级调度,负载均衡,监控报警,
4、接口的幂等性的概念
- MVCC方案
- 去重表
- 悲观锁
- select + insert
- 状态机幂等
- token机制,防止页面重复提交
- 对外提供接口的api如何保证幂等,如银联提供的付款接口:需要接入商户提交付款请求时附带:source来源,seq序列号。source+seq在数据库里面做唯一索引,防止多次付款,(并发时,只能处理一个请求)
4.1 消息中间件解决消息顺序和重复问题
http://dbaplus.cn/news-21-1123-1.html
RocketMQ 特性:
1.顺序消息:
RocketMQ通过轮询所有队列的方式来确定消息被发送到哪一个队列, 在获取到路由信息以后,会根据MessageQueueSelector实现的算法来选择一个队列,同一个OrderId获取到的肯定是同一个队列
2.重复消息:
- 消费端处理消息的业务逻辑保持幂等性
- 保证每条消息都有唯一编号且保证消息处理成功与去重表的日志同时出现
3.事务消息(现在已经不支持了)
大事务 = 小事务 + 异步
4.Producer如何发消息
Producer轮询某topic下的所有队列的方式来实现发送方的负载均衡
5.消息存储
RocketMQ的消息存储是由consume queue和commit log配合完成的。
- consume queue是消息的逻辑队列,相当于字典的目录,用来指定消息在物理文件commit log上的位置。
死信队列(Dead Letter Queue)一般用于存放由于某种原因无法传递的消息,比如处理失败或者已经过期的消息。
- CommitLog:消息存放的物理文件,每台broker上的commitlog被本机所有的queue共享,不做任何区分。
3.消息实现
4.消息索引
6.消息订阅
RocketMQ消息订阅有两种模式,一种是Push模式,即MQServer主动向消费端推送;另外一种是Pull模式,即消费端在需要时,主动到MQServer拉取。但在具体实现时,Push和Pull模式都是采用消费端主动拉取的方式。
7.其他特性
定时消息
消息的刷盘策略
主动同步策略:同步双写、异步复制
海量消息堆积能力
高效通信
https://yq.aliyun.com/articles/66101
5、消息中间件如何解决消息丢失问题
消息落地
6、Dubbo的服务请求失败怎么处理
超时和重连机制
https://my.oschina.net/u/661116/blog/698566
7、重连机制会不会造成错误
可能会导致某个功能调用多次
8、对分布式事务的理解
8.1 强一致性
- 2PC
- 3PC
- Paxos
8.2 最终一致性
消息补偿
9、如何实现负载均衡,有哪些算法可以实现?
- 随机
- 轮训
- 加权轮训
- 最小连接数
- 源地址hash(根据客户端的IP地址)
- 一致性hash
10、Zookeeper的用途,选举的原理是什么?
http://blog.csdn.net/king866/article/details/53992653
分布式应用协调系统,完成统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等工作。
选举原理basic 和 fast paxos
11、数据的垂直拆分水平拆分。
12、zookeeper原理和适用场景
http://blog.csdn.net/king866/article/details/53992653
12.1 znode节点
有四种类型的znode:
- PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在 - PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号 - EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除 - EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
12.2 NameService 命名服务
这个似乎最简单,在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现
这个主要是作为分布式命名服务,通过调用zk的create node api,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
12.3 configuration 配置管理
现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
12.4 GroupMembers 集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道了。新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了。
对于第二点,所有机器创建临时顺序编号目录节点,通过master选举算法选举出来。
12.5 适用场景
- 数据发布与订阅 - 将数据发布到zk节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。
- 分布通知/协调 - watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对 ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能 够收到通知,并作出相应处理。
- 分布式锁 - ZooKeeper为我们保证了数据的强一致性,即用户只要完全相信每时每刻,zk集群中任意节点(一个zk server)上的相同znode的数据是一定是相同的。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
- 集群管理 - 集群机器监控; Master选举
13、zookeeper watch机制
http://blog.csdn.net/king866/article/details/53992653
Client可以在某个ZNode上设置一个Watcher,来Watch该ZNode上的变化。如果该ZNode上有相应的变化,就会触发这个Watcher,把相应的事件通知给设置Watcher的Client。需要注意的是,ZooKeeper中的Watcher是一次性的,即触发一次就会被取消,如果想继续Watch的话,需要客户端重新设置Watcher
- 注册只能确保一次消费, 无论是服务端还是客户端,一旦一个 Watcher 被触发,ZooKeeper 都会将其从相应的存储中移除。因此,开发人员在 Watcher 的使用上要记住的一点是需要反复注册。这样的设计有效地减轻了服务端的压力。如果注册一个 Watcher 之后一直有效,那么针对那些更新非常频繁的节点,服务端会不断地向客户端发送事件通知,这无论对于网络还是服务端性能的影响都非常大
- 客户端串行执行,客户端 Watcher 回调的过程是一个串行同步的过程,这为我们保证了顺序,同时,需要开发人员注意的一点是,千万不要因为一个 Watcher 的处理逻辑影响了整个客户端的 Watcher 回调。
- 轻量级设计,WatchedEvent 是 ZooKeeper 整个 Watcher 通知机制的最小通知单元,这个数据结构中只包含三部分的内容:通知状态、事件类型和节点路径。也就是说,Watcher 通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。
14、redis/zk节点宕机如何处理
重新选举
15、分布式集群下如何做到唯一序列号
- 数据库自增长
- UUID (包括变种)
- Redis生成ID, 原子操作, INCR 和 INCRBY
16、如何做一个分布式锁
https://yq.aliyun.com/articles/60663
- 数据库
- redis
- zookeeper
17、用过哪些MQ,怎么用的,和其他mq比较有什么优缺点,MQ的连接是线程安全的吗
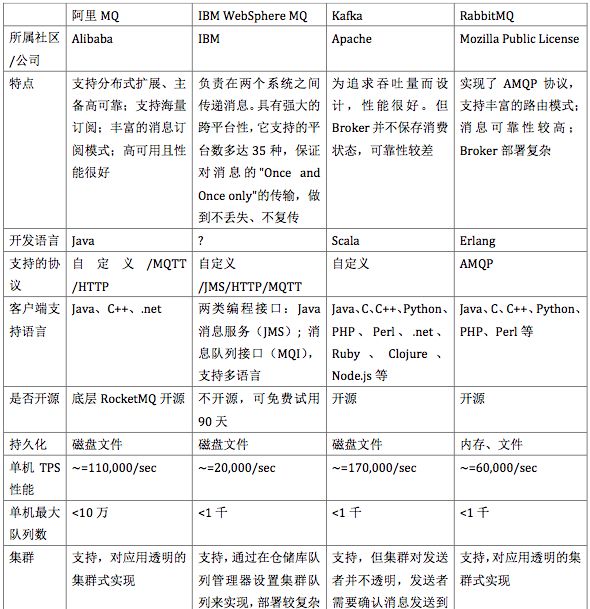
18、MQ系统的数据如何保证不丢失
持久化
19、列举出你能想到的数据库分库分表策略;分库分表后,如何解决全表查询的问题
http://blog.csdn.net/xlgen157387/article/details/53976153
冗余和数据字典
20、zookeeper的选举策略
paxos
21、全局ID
数据库
1、mysql分页有什么优化
官方文档
- 如果只使用LIMIT选择部分行, MySQL大多数情况会全表扫描,有时会用到索引?
- 如果把LIMIT row_count和ORDER BY 结合使用, MySQLY一旦找到需要的行数就会停止排序,而不会将所有数据进行排序,如果排序过程使用到索引速度会非常快。如果必须用到文件排序(外部排序),那么在获得row_count对应的结果之前,所有满足query条件(这里不考虑LIMIT)的行会被选中,文件中的数据在进行外部排序之前应该已经有序。得到row_count的结果以后, MySQL不会对剩余数据进行排序。
这带来的结果就是带不带LIMIT的ORDER BY可能按照不同的顺序返回结果。 - 如果把LIMIT row_count 和 DISTINCT 结合使用, MySQL会在找到不重复的row_count行后立即停止。
- 在某些情况下, GROUP BY 可以通过按顺序读取索引(或对索引进行排序)来解析,然后计算结果直到索引发生变化。这种情况下,LIMIT row_count 不会计算任何非必需的GROUP BY的值。
- 一旦MySQL将需要行数的结果发给客户端,它会终止查询,除非使用SQL_CALC_FOUND_ROWS, 然后使用 SELECT FOUND_ROWS()来获取行数。具体参考 2.14章节。
- LIMIT 0快速返回一个空集合,可以用来检查查询语句是否正确。(后面复杂,懒得翻译了...)
- 如果服务器使用临时表来解析查询,则它使用LIMIT row_count来计算需要多少空间。
- 如果没有用到索引,但是LIMIT语句存在,优化器可能可以做到避免(文件)归并排序而使用内存中的文件排序。具体请参照In-Memory filesort Algorithm
2、悲观锁、乐观锁
悲观锁: 行级锁或者表级锁
乐观锁: 版本号
3、组合索引,最左原则
数据库索引
4、mysql 的表锁、行锁
不同的mysql引擎默认锁级别不同:
- innoDB 行锁, 支持事务,默认可重复读
- MyISAM 表锁, 不支持事务
5、mysql 性能优化
话题太大,回头说...
6、mysql的索引分类:B+,hash;什么情况用什么索引
hash: 只在= 和 <> 时使用,速度快
B+树: 正常手动创建的索引底层都是B+树。
7、事务的特性和隔离级别
数据库事务
缓存
1、Redis用过哪些数据数据,以及Redis底层怎么实现
http://www.runoob.com/redis/redis-tutorial.html
String
- SET name "test"
- GET name
Hash
- HMSET
- HGET key
- HGETALL key
List
- LPUSH
- LINSERT KEY_NAME BEFORE EXISTING_VALUE NEW_VALUE
Set
- SADD
- SDROP
ZSet
- ZADD
- ZRANGE
HyperLogLog
- PFADD
- PFCOUNT
http://www.cnblogs.com/jaycekon/p/6227442.html
2、Redis缓存穿透,缓存雪崩
缓存穿透是指查询一个一定不存在的数据:
- 所有可能的数据hash到一个bitmap
- 如果查询为空,进行缓存,但是要设置过期时间
缓存雪崩:
- 缓存失效时间尽量随机分散
- 二级缓存, 时间比一级缓存时间长
3、如何使用Redis来实现分布式锁
http://ifeve.com/redis-lock/
4、Redis的并发竞争问题如何解决
5、Redis持久化的几种方式,优缺点是什么,怎么实现的
RDB - redis data base
RDB是在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复
- 优点:使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能,并且有数据快照,回复数据比较简单
- 缺点: RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失
- snapshot触发的时机,是有“间隔时间”和“变更次数”共同决定,同时符合2个条件才会触发snapshot
AOF - Append only File
将“操作 + 数据”以格式化指令的方式追加到操作日志文件的尾部,在append操作返回后(已经写入到文件或者即将写入),才进行实际的数据变更
- 优点:可以保持更高的数据完整性,如果设置追加file的时间是1s,如果redis发生故障,最多会丢失1s的数据;且如果日志写入不完整支持redis-check-aof来进行日志修复;AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)。
- 缺点:AOF文件比RDB文件大,且恢复速度慢。
6、Redis的缓存失效策略
1、如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru
2、如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
Redis采用的是定期删除策略和懒汉式的策略互相配合。
懒汉式删除策略
含义:key过期的时候不删除,每次通过key获取值的时候去检查是否过期,若过期,则删除,返回null。
- 优点:删除操作只发生在通过key取值的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
- 缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
定期删除策略
- 含义:每隔一段时间执行一次删除过期key操作
- 优点:
- 通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
- 定期删除过期key--处理"懒汉式删除"的缺点
- 缺点:
- 在内存友好方面,不如"定时删除"(会造成一定的内存占用,但是没有懒汉式那么占用内存)
- 在CPU时间友好方面,不如"懒汉式删除"(会定期的去进行比较和删除操作,cpu方面不如懒汉式,但是比定时好)
- 难点:合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了),每次执行时间太长,或者执行频率太高对cpu都是一种压力。
7、Redis集群,高可用,原理
http://blog.csdn.net/yinwenjie/article/details/53672232
http://rdc.hundsun.com/portal/article/669.html
8、Redis缓存分片
http://wiki.jikexueyuan.com/project/redis-guide/partitioning.html
9、Redis的数据淘汰策略
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据