自学大数据有一段时间了,找工作历时一周,找到一家大厂,下周入职,薪资待遇还不错,公司的业务背景自己也很喜欢。趁着还没有入职,给大家争取先把 Hadoop 系列的文章总结完毕,可以当做科普文,也可以当做笔记收藏。经过查阅各种资料,保证我的理解没有偏差。但是也难免会有疏漏,欢迎朋友们留言给我进行交流。我的座右铭就是:认真搞定一切!绝对保证一字一字好好斟酌,技术不能有半点马虎。
目前 Hadoop 系列文章的规划就是这样,其它的小组件先不进行总结,以后会慢慢涉及到的。
Hadoop 生态系列之 1.0 和 2.0 架构
Hadoop 生态系列之 HDFS
Hadoop 生态系列之 Mapreduce
Hadoop 生态系列之 Yarn
Hadoop 生态系列之 Zookeeper
Hadoop 生态系列之 Hive
Hadoop 生态系列之 HBase
学习大数据的前提思想:分而治之。
先来一个题目大家思考一下:给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
这个问题不要急着我上网去查。先思考一下,结合上面我提到的「分而治之」的思想。思路会在文末给出。
1背景
2003 年 Google 发表三篇论文,分别是 《The Google File System》 《MapReduce: Simplified Data Processing on Large Clusters》 《Bigtable: A Distributed Storage System for Structured Data》,分别对应后来出现的 HDFS,MapReduce, HBase。建议大家都看看论文原文,后台回复谷歌论文即可。
2006 年 Docu Cutting 开源了 Hadoop,名字取自于他儿子的玩具小象 Hadoop。
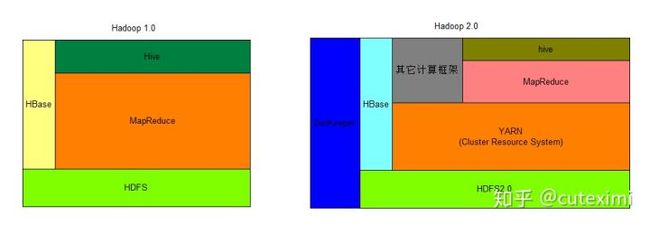
Hadoop 1.0 是指 MapReduce + HDFS,Hadoop 2.0 是指 MapReduce + HDFS + Yarn。
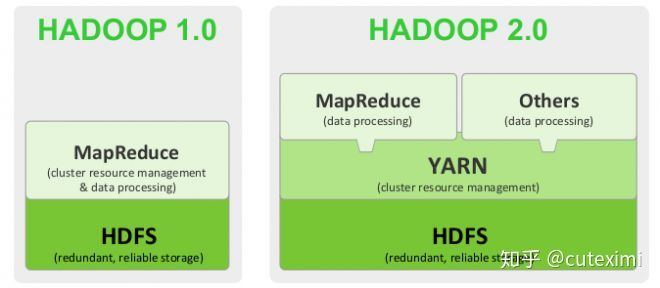
在再细分一下:
大数据解决框架解决的问题大体可以分为两个方面:一是海量数据的存储、二是海量数据的计算。
2Hadoop 1.0 架构
为了解决上述问题,推出了一系列的解决方案,其中开源框架中比较出名的就是 Hadoop 了,提供了分布式存储系统 HDFS 和分布式计算模型 MapReduce。
Hadoop1.0 即第一代 Hadoop,指的是版本为 Apache Hadoop 0.20.x、1.x或者 CDH3 系列的 Hadoop,内核主要由 HDFS 和 MapReduce 两个系统组成,其中MapReduce是一个离线处理框架,由编程模型(新旧API)、运行时环境(JobTracker 和 TaskTracker)和数据处理引擎(MapTask和ReduceTask)三部分组成。
先来说一下 HDFS 的架构,架构图如下:

分布式系统最怕的就是出现单节点的问题,很容易成为性能瓶颈。HDFS 1.0 中使用 NameNode 做为主节点,SecondaryNameNode 作为从节点,但是这里的从节点不能作为主节点的备份。
分布式计算,MapReduce 1.0 的架构如下:

缺点是:JobTracker 压力大。单点故障。只能执行 MapReduce 任务,不能跑 Storm,Flink等计算框架的任务。
3Hadoop 2.0 架构
Hadoop2.0即第二代Hadoop,指的是版本为Apache Hadoop 0.23.x、2.x或者CDH4系列的Hadoop,内核主要由HDFS、MapReduce和YARN三个系统组成,其中YARN是一个资源管理系统,负责集群资源管理和调度,MapReduce则是运行在YARN上的离线处理框架。
1、针对Hadoop1.0单NameNode制约HDFS的扩展性问题,提出HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展,同时彻底解决了NameNode单点故障问题;
2、针对Hadoop1.0中的MapReduce在扩展性和多框架支持等方面的不足,它将JobTracker中的资源管理和作业控制分开,分别由ResourceManager(负责所有应用程序的资源分配)和ApplicationMaster(负责管理一个应用程序)实现,即引入了资源管理框架Yarn。
3、Yarn作为Hadoop2.0中的资源管理系统,它是一个通用的资源管理模块,可为各类应用程序进行资源管理和调度,不仅限于MapReduce一种框架,也可以为其他框架使用,如Tez、Spark、Storm等。
HDFS 在 Hadoop 2.0 中的架构图如下:
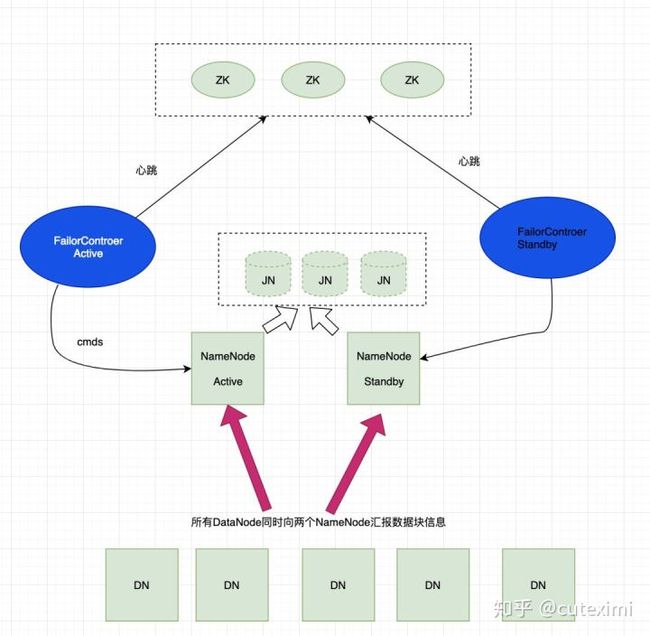
NameNode 变为两个,一个主节点,一个从节点,主节点负责接收客户端的读写请求,从节点同步主节点的元数据。两个 NameNode 就需要保持元数据一致,这个是由 JN 集群来完成的。主从节点的自动切换是由 ZKFC 来完成的。这里面的细实现细节很重要。对于理解分布式应用也是一种帮助。Hadoop 的 高可用原理:Hadoop HA 深度解剖。
Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;核心思想:将MRv1 中 JobTracker 的资源管理和任务调度两个功能分开,分别由 ResourceManager 和 进程实现。
1.ResourceManager负责资源管理和调度;
2.ApplicationMaster:负责任务切分、任务调度、任务监控和容错等。
3.MapTask/ReduceTask:任务驱动引擎,与MRv1一致
注意:每个 MapRduce 作业对应一个 ApplicationMaster 任务调度。
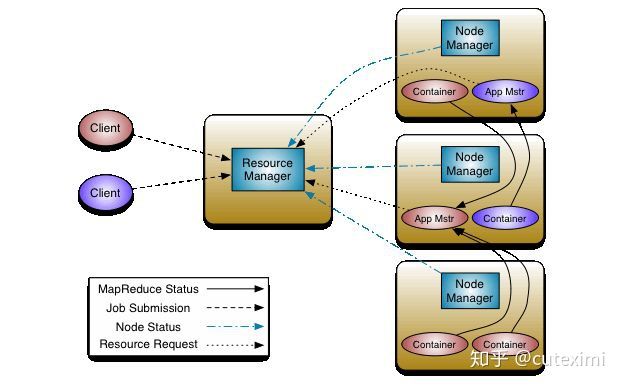
使用 Yarn 资源调度和任务管理。Hadoop 2.0 中 YARN的引入,使得多个计算框架可运行在一个集群中。
今天这篇文章主要是介绍一下 Hadoop 1.0 和 2.0 的架构,以及 2.0 改善的地方。继续深挖的话,东西太多了,你学的越深,不会的东西就越多。但是做研究就是这样,没有一个人敢说自己在某一方面很完美,随着升级打怪的难度提升,不懂的就越多,人生就是这样一个大游戏啊。今天关于架构就介绍到这里,有什么正确的地方欢迎留言指出。
回答一下开头的思路:分而治之。
Q:给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
A:可以估计每个文件的大小为50G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。s 遍历文件a,对每个url求取 hash(url) % 1000,然后根据所取得的值将url分别存储到1000个小文件(记为)中。这样每个小文件的大约为300M。s 遍历文件b,采取和a相同的方式将url分别存储到1000个小文件(记为)。这样处理后,所有可能相同的url都在对应的小文件()中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。s 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
Hadoop 中 MapReduce 计算模型就是分而治之思想的一种实现,更重要对于我们开发者来说使用很简单,只需要开发的过程中使用对应的模块就可以完成我们的分布式应用,Map 和 Reduce 细节不需要我们关心。
(全文完)
如果对您有帮助,欢迎点赞、关注、转发。
