一、Word Embedding
1.Word2Vec(2013)
分布式假设:假设两个词上下文相似,则它们的语义也相似。
2.GloVe
(1)词向量学习算法有两个主要的模型族:
基于全局矩阵分解的方法,如:latent semantic analysis:LSA 。
优点:能够有效的利用全局的统计信息。
缺点:在单词类比任务(如:国王 vs 王后 类比于男人 vs 女人)中表现相对较差。
基于局部上下文窗口的方法,如:word2vec。
优点:在单词类比任务中表现较好。
缺点:因为word2vec 在独立的局部上下文窗口上训练,因此难以利用单词的全局统计信息。
Global Vectors for Word Representation:GloVe 结合了LSA 算法和Word2Vec 算法的优点,既考虑了全局统计信息,又利用了局部上下文。
Cbow/Skip-Gram 是一个local context window的方法,缺乏了整体的词和词的关系,负样本采用sample的方式会缺失词的关系信息。
另外,直接训练Skip-Gram类型的算法,很容易使得高曝光词汇得到过多的权重
Global Vector融合了矩阵分解Latent Semantic Analysis (LSA)的全局统计信息和local context window优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。
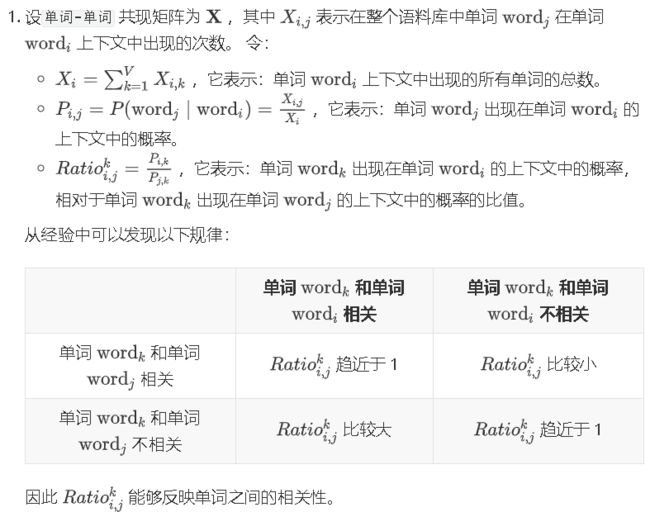
(2)原理



二、RNN改进和扩展
问题:词向量不考虑上下文,无法解决“一词多义”
解决方案:RNN具有“记忆”能力
1.RNN
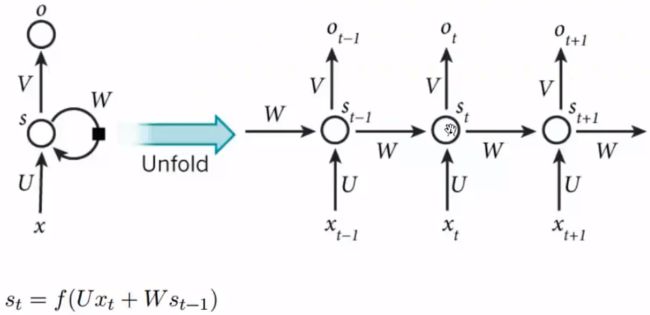
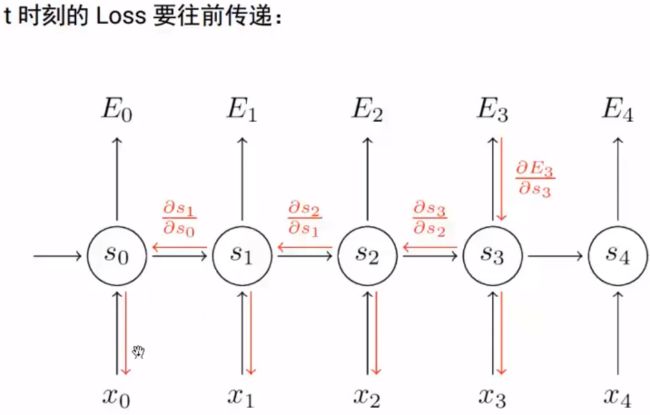
RNN的问题:顺序依赖,无法并行。(单向信息流)
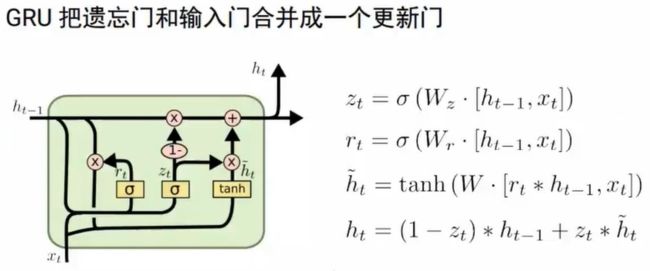
2.LSTM/GRU
2.1 LSTM
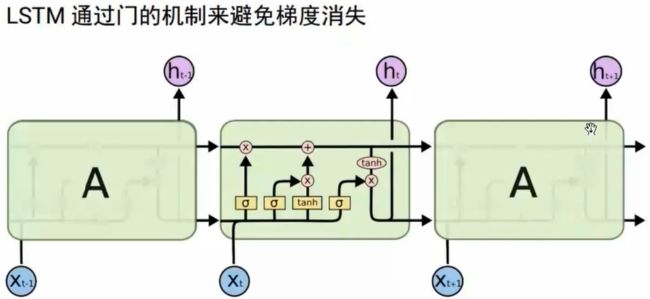
2.2 GRU
3.Seq2Seq
可用于翻译、摘要、问答和对话系统
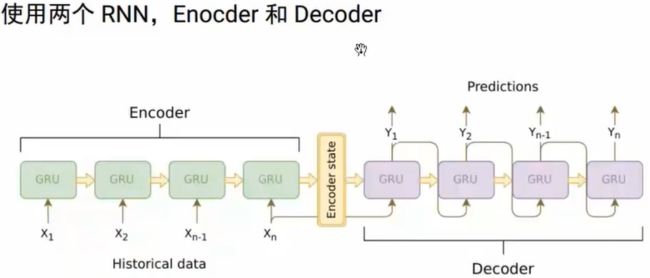
问题:定长的context向量
4.Attention/Self Attention
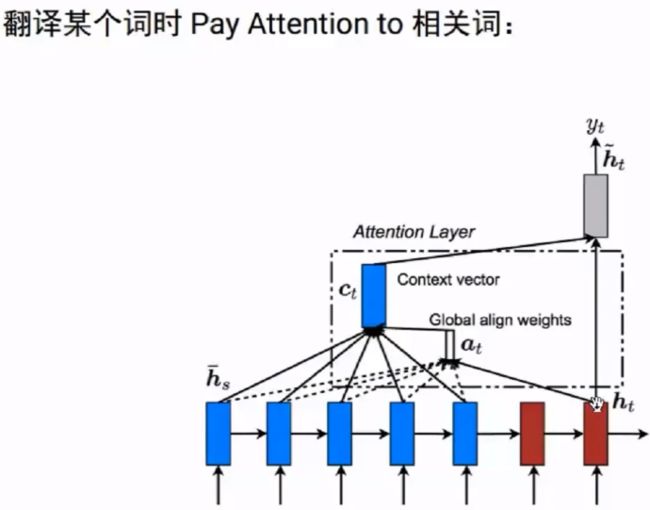

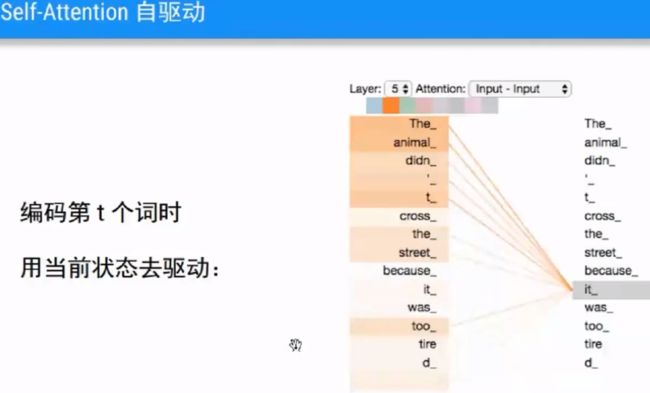
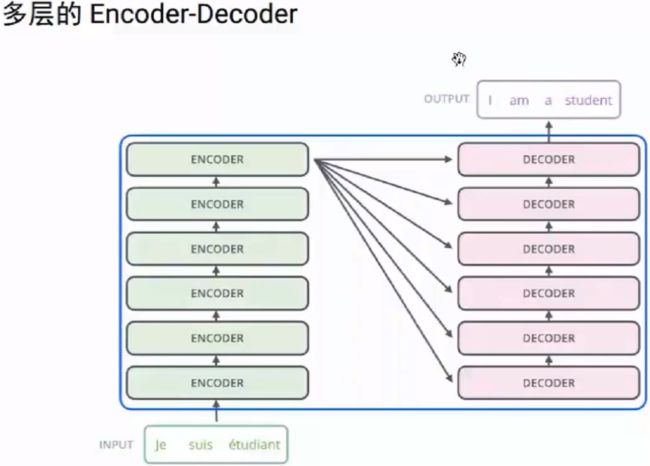
5.Transformer结构
解决:RNN单向数据流的问题
三、Contextual Word Embedding
问题:监督数据量不足,难以学到复杂的上下文表示;
解决方案:无监督的contextual word embedding:ELMo、OpenAI GPT、BERT
1.ELMo

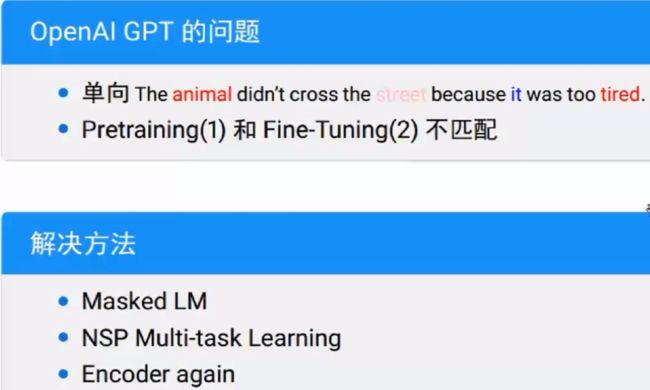
2.OpenAI GPT

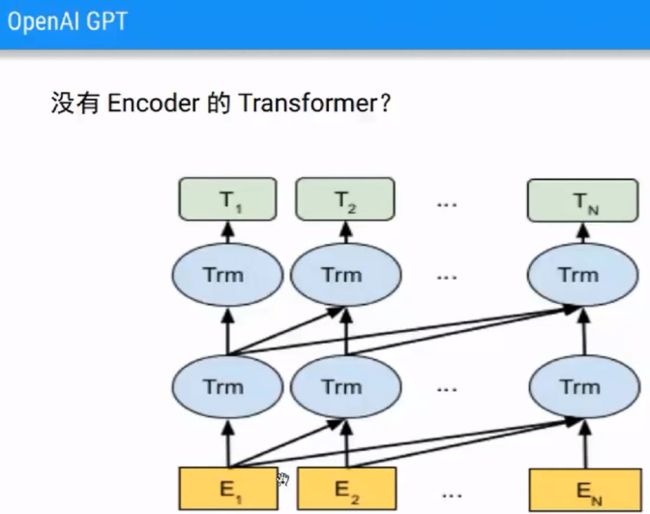
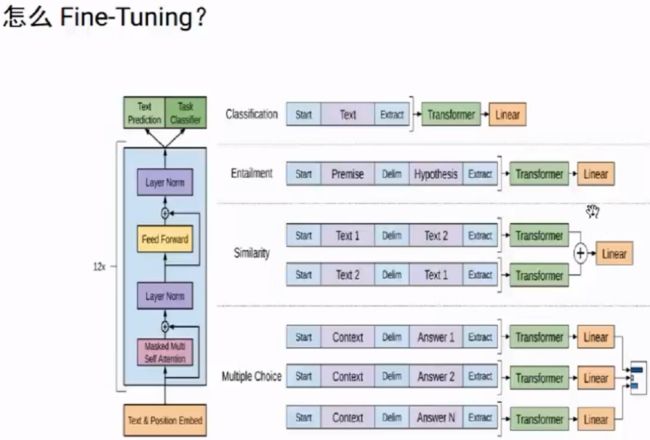
3.BERT

Masked LM:masked language model


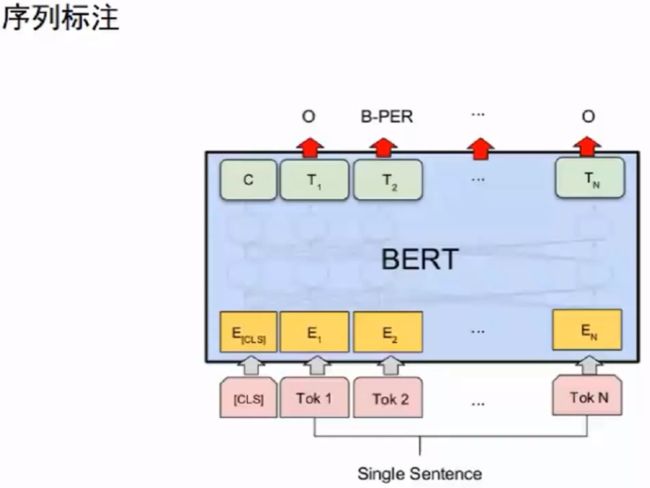
举例:意图分类
问题:给定一个句子,判断其意图分类,几万训练数据,几百个类别,数据不平衡
结果:BERT分类器比BaseLine分类器F1值得分提高3%


参考文献:
【1】60分钟带你掌握NLP BERT理论与实战_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
【2】详解Transformer (Attention Is All You Need) - 知乎